编程开发_一致性hash算法在内存数据库中的应用技巧
在内存数据库应用上,由于Redis的是单点,但该项目将不可避免地使用多个Redis的缓存服务器,那么如何统一映射缓存键到多个Redis的服务器和缓存服务器的增加或减少,以达到最小化的关键缓存命中率下降了吗?因此,我们需要实现自己的分配。
Memcached的应该不会陌生吧,通过映射到memcached服务器密钥,快速读取。我们可以动态地增加它的节点,之前没有影响的关系已被映射到密钥和memcached的服务器,这是由于使用一致的散列之间的内存数据库。因为Memcached的哈希策略是,在客户端实现,所以不同的客户端的实现是不同的Spymemcache,Xmemcache例如,我们习惯KETAMA作为其实现。
一致性哈希算法:
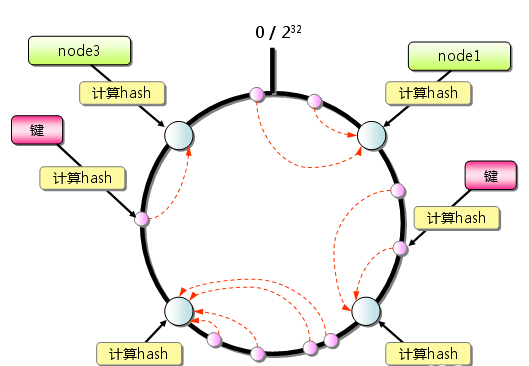
由于散列算法的结果通常是无符号整型,所以哈希函数的结果应均匀分布在[0,2 ^ 32-1]区间,如果我们把戒指戴用2 ^ 32分切均匀,先跟随散列(键)函数计算服务器(节点)的散列值,和环0至2 ^ 32,其被分配到。
具有相同散列(键)函数来查找需要存储数据的密钥的散列值,并且映射到该环。然后从内存数据库映射开始找位置顺时针方向,将数据保存到找到的第一个服务器(节点)。 KEY1,KEY2,KEY3和服务器1,服务器通过哈希可以找到自己的位置在这个环,顺时针的方式来定位密钥服务器。点击,键1和键2存储到Server1和Key3存储服务器2的图像。如果键1和键2的后添加一台服务器,哈希,它只会影响KEY1(在新的服务器密钥1将存储),其他不变。
