用R语言实现深度学习情感分析
黄升:普兰金融数据分析师,从事数据分析相关工作,擅长R语言,热爱统计和挖掘建模。
前言到了2018新的一年。18岁虽然没有成为TF-boys,但是2018新的一年可以成为TF(Tensorflow-boys)啊~~~
word embeddings介绍之前建立的情感分类的模型都是Bag of words方法,仅仅统计词出现的次数这种方法破坏了句子的结构。这样的结构,我们也可以使用如下的向量(one hot 编码)表示句子「The cat sat on the mat」: 然而,在实际应用中,我们希望学习模型能够在词汇量很大(10,000 字以上)的情况下进行学习。从这里能看到使用「独热码」表示单词的效率问题——对这些词汇建模的任何神经网络的输入层至少都有 17000,000 个节点。因此,我们需要使用更高效的方法表示文本数据,而这种方法不仅可以保存单词的上下文的信息,而且可以在更低的维度上表示。这是 word embeddings 方法发明的初衷。
然而,在实际应用中,我们希望学习模型能够在词汇量很大(10,000 字以上)的情况下进行学习。从这里能看到使用「独热码」表示单词的效率问题——对这些词汇建模的任何神经网络的输入层至少都有 17000,000 个节点。因此,我们需要使用更高效的方法表示文本数据,而这种方法不仅可以保存单词的上下文的信息,而且可以在更低的维度上表示。这是 word embeddings 方法发明的初衷。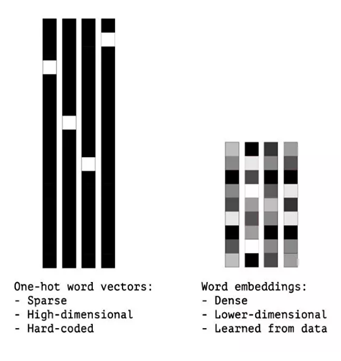 word embeddings就是将一个个词映射到低维连续向量(如下图所示) :
word embeddings就是将一个个词映射到低维连续向量(如下图所示) :
这种向量的思想就是将相似的词映射到相似方向,所以,语义相似性就可以被编码了。相似性一般可以通过余弦相似度来衡量: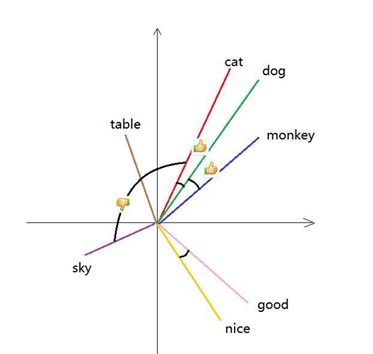 安装TensorFlow和Keras# 安装并加载Keras包install.packages(“devtools”)devtools::install_github(“rstudio/keras”)install_keras()library(keras)
安装TensorFlow和Keras# 安装并加载Keras包install.packages(“devtools”)devtools::install_github(“rstudio/keras”)install_keras()library(keras)
# 安装并加载TensorFlow包devtools::install_github(“rstudio/tensorflow”)library(tensorflow)install_tensorflow()注:安装TensorFlow和Keras前需要安装Anaconda,Anaconda尽量装版本的,Anaconda在Windows安装有一些坑,我是把Java环境删掉还有使用默认路径才成功安装了Anaconda。
检测是否安装成功# 输入下面代码sess = tf$Session()hello <- tf$constant(‘Hello, TensorFlow!’)sess$run(hello)OK,如果没有问题的话,你的结果也将是如上图所示,则表明你已安装成功。
LSTM原理长短期记忆网络——通常简称“LSTMs”,是一种特殊的RNN,能够学习长期依赖关系,它可以桥接超过1000步的时间间隔的信息。LSTM由Hochreiter和Schmidhuber (1997)提出,在后期工作中又由许多人进行了调整和普及(除了原始作者之外,许多人为现代LSTM做出了贡献)。LSTM在各种各样的问题上工作非常好,现在被广泛使用。
LSTMs被设计出来是为了避免长期的依赖性问题,记忆长时间的信息实际上是他们的固有行为,而不是去学习,这点和传统的具有强大的表征学习能力的深度神经网络不同。
所有的RNNs(包括LSTM)都具有一连串重复神经网络模块的形式。在标准的RNNs中,这种重复模块有一种非常简单的结构,比如单个tanh层: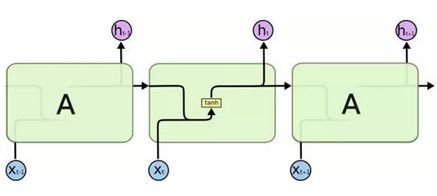
什么是tanh?中文叫双曲正切函数,属于神经网络隐藏层的activation function(激活函数)中的一种。别以为是什么好厉害的东西,其实就是一个简单的以原点对称的值域为[-1,1]的非线性函数。而神经网络中比较常见的另外一个激活函数 sigmoid 函数,则不过是把tanh函数往上平移到[0,1]的区间,这个函数在LSTM也会用到。
LSTM也有像RNN这样的链式结构,只不过重复模块有着与传统的RNN不同的结构,比传统的RNN复杂不少:不只是有一个神经网络层,而是有四个神经网络层,以一个非常特殊的方式进行交互。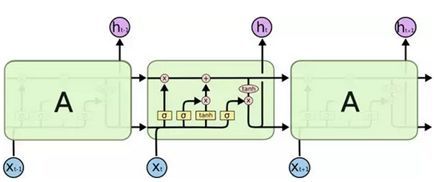 不用担心看不懂细节部分是什么意思,稍后我们将逐步浏览LSTM图。现在,让我们试着去熟悉我们将要使用的符号。
不用担心看不懂细节部分是什么意思,稍后我们将逐步浏览LSTM图。现在,让我们试着去熟悉我们将要使用的符号。
在上面所示的图中,我们对以上符号进行如下定义: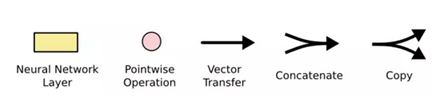
黄块表示学习神经网络层(tanh层或sigmoid层);粉色圆圈表示按位操作,如向量加法或者向量点乘;每条线代表着一整个向量(vector),用来表示从一个节点的输出到另一个节点的输入;合并的线代表连接或者说是拼接;分叉表示其内容被复制,复制内容将转到不同的位置
LSTMs背后的核心理念LSTMs的关键是细胞状态(cell state),是一条水平线,贯穿图的顶部。而Cell 的状态就像是传送带,它的状态会沿着整条链条传送,而只有少数地方有一些线性交互。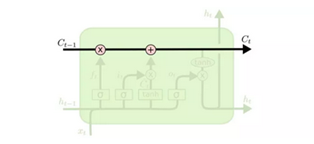 因此“门”就是LSTM控制信息通过的方式,这里的” σ “ 指的是 sigmoid 函数。Sigmoid 层的输出值在 0 到 1 间,表示每个部分所通过的信息。“0” 意味着“让任何事情无法通过”或者说成”忘记所有的事“;“ 1 ”意味着”让一切都通过!“ 或者说”我要记住这一切! “
因此“门”就是LSTM控制信息通过的方式,这里的” σ “ 指的是 sigmoid 函数。Sigmoid 层的输出值在 0 到 1 间,表示每个部分所通过的信息。“0” 意味着“让任何事情无法通过”或者说成”忘记所有的事“;“ 1 ”意味着”让一切都通过!“ 或者说”我要记住这一切! “
一个 LSTM 有三个这样的门,分别是“输入门”、遗忘门“和 ”输出门“,在单一模块里面控制 cell 的状态。
遗忘门首先,LSTM 的第一步就是让信息通过”遗忘门“,决定需要从 cell 中忘掉哪些信息。它的输入是 ht-1 和 xt。另外,我们之所以使用sigmoid激活函数是因为我们所需要的数字介于0至1之间。Ct−1 就是每个在 cell 中所有在 0 和 1 之间的数值,就像我们刚刚所说的,0 代表全抛弃,1 代表全保留。
看到这里应该有朋友会问什么是ht,ht是LSTM层在t时刻的输出,但不是最终的输出,ht仅仅是LSTM层输出的向量,要想得到最终的结果还要连接一个softmax层(sigmoid函数的输出是”0“”1“,但是使用softmax函数能在三个类别以上的时候输出相应的概率以解决多分类问题),而x就是我们的输入,是一个又一个的词语。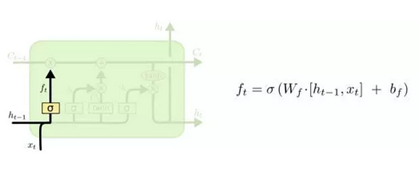 输入门下一步,我们需要决定什么样的信息应该被存储起来。这个过程主要分两步。首先是 sigmoid 层(这就是“输入门”)决定我们需要更新哪些值;随后,tanh 层生成了一个新的“候选添加记忆” C`t,最后,我们将这两个值结合起来。结合后能够加入cell的状态(长期记忆)中。
输入门下一步,我们需要决定什么样的信息应该被存储起来。这个过程主要分两步。首先是 sigmoid 层(这就是“输入门”)决定我们需要更新哪些值;随后,tanh 层生成了一个新的“候选添加记忆” C`t,最后,我们将这两个值结合起来。结合后能够加入cell的状态(长期记忆)中。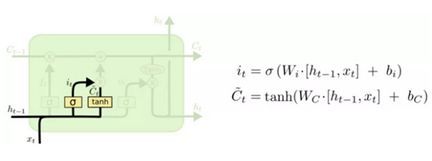
接下来我们可以更新 cell (长期记忆)的状态了。首先第一步将旧状态与通过遗忘门得到的 ft 相乘,忘记此前我们想要忘记的内容,然后加上通过输入门和tanh层得到的候选记忆 C`t。在忘记我们认为不再需要的记忆并保存输入信息的有用部分后,我们就会得到更新后的长期记忆。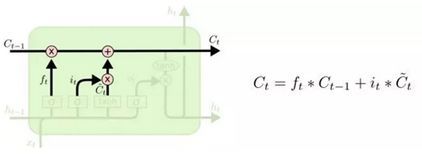 输出门接下来我们来更新一下ht,即输出的内容,这部分由输出门来完成。首先,我们把 cell 状态通过 tanh 函数,将输出值保持在-1 到 1 间。随后,前一时刻的输出ht-1和xt会通过一个 sigmoid 层,决定 cell 状态输出哪一部分。之后,我们再乘以 sigmoid 门的输出值,就可以得到结果了。
输出门接下来我们来更新一下ht,即输出的内容,这部分由输出门来完成。首先,我们把 cell 状态通过 tanh 函数,将输出值保持在-1 到 1 间。随后,前一时刻的输出ht-1和xt会通过一个 sigmoid 层,决定 cell 状态输出哪一部分。之后,我们再乘以 sigmoid 门的输出值,就可以得到结果了。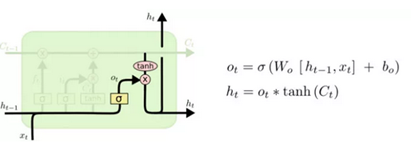 R上用LSTM做情感分类
R上用LSTM做情感分类
max_features <- 20000batch_size <- 32
# Cut texts after this number of words (among top max_features most common words)maxlen <- 80 cat(‘Loading data…\n’)
imdb <- dataset_imdb(num_words = max_features)x_train <- imdb$train$xy_train <- imdb$train$yx_test <- imdb$test$xy_test <- imdb$test$yview(x_train)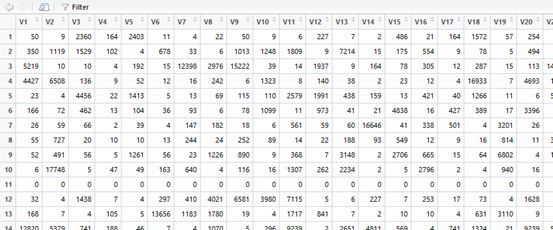 IMDB数据集包含有2.5万条电影评论,被标记为积极和消极。影评会经过预处理,把每一条影评编码为一个词索引(数字)sequence(前面的一种word embeddings方法) 。
IMDB数据集包含有2.5万条电影评论,被标记为积极和消极。影评会经过预处理,把每一条影评编码为一个词索引(数字)sequence(前面的一种word embeddings方法) 。
cat(length(x_train), ‘train sequences\n’)cat(length(x_test), ‘test sequences\n’)cat(‘Pad sequences (samples x time)\n’)
x_train <- pad_sequences(x_train, maxlen = maxlen)x_test <- pad_sequences(x_test, maxlen = maxlen)
cat(‘x_train shape:’, dim(x_train), ‘\n’)cat(‘x_test shape:’, dim(x_test), ‘\n’) cat(‘Build model…\n’)model <- keras_model_sequential()model %>% layer_embedding(input_dim = max_features, output_dim = 128) %>% layer_lstm(units = 64, dropout = 0.2, recurrent_dropout = 0.2) %>% layer_dense(units = 1, activation = ‘sigmoid’)
cat(‘Build model…\n’)model <- keras_model_sequential()model %>% layer_embedding(input_dim = max_features, output_dim = 128) %>% layer_lstm(units = 64, dropout = 0.2, recurrent_dropout = 0.2) %>% layer_dense(units = 1, activation = ‘sigmoid’)
当然,可以尝试使用不同的优化器和不同的优化器配置:model %>% compile( loss = ‘binary_crossentropy’, optimizer = ‘adam’, metrics = c(‘accuracy’))
cat(‘Train…\n’)model %>% fit( x_train, y_train, batch_size = batch_size, epochs = 15, validation_data = list(x_test, y_test))上面代码的训练过程如下图所示(我电脑大概用了20min):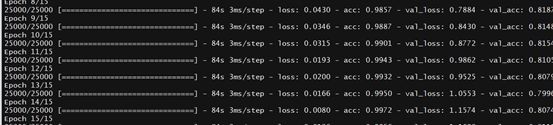 # 模型的准确度度量scores <- model %>% evaluate( x_test, y_test, batch_size = batch_size)
# 模型的准确度度量scores <- model %>% evaluate( x_test, y_test, batch_size = batch_size)
cat(‘Test score:’, scores[[1]])cat(‘Test accuracy’, scores[[2]])
接下来,我们再对比其他模型,不妨以随机森林为例:library(randomForest)
y_train <- as.factor(y_train)y_test <- as.factor(y_test)rf <- randomForest(x=x_train,y=y_train,ntree=1000)predict <- predict(rf,newdata=x_test) 很显然,集成算法随机森林远远没有LSTM出来的效果好。今天关于基于R语言的深度学习就介绍到这里。
参考资料:https://tensorflow.rstudio.com/keras/articles/examples/imdb_lstm.htmlhttp://colah.github.io/posts/2015-08-Understanding-LSTMs/
欢迎加入本站公开兴趣群商业智能与数据分析群兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识QQ群:81035754
