Data Input(数据输入)
与SAS差异的是,SAS有数据步和进程步,而R拥有诸多的数据布局(向量,矩阵,数组,数据框),通过函数在这些数据布局长举办统计阐明和建设图形。在这一点上,R与SAS的PROC IML进程步很相似。
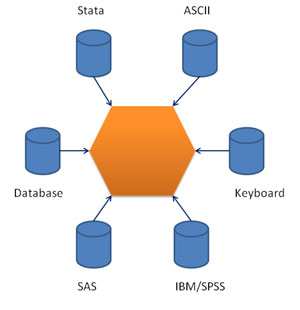
这部门描写如何向R中输入可能导入数据,如作甚统计阐明做筹备。涵盖了R数据布局,导入数据(从Excel,SPSS,SAS,Stata和ASCII文本文件),从键盘输入数据,建设一个与数据库打点系统交互的界面,导出数据(到Excel,SPSS,SAS,Stata和制表符脱离的文本文件),标注数据(变量标签和值标签)与列出数据。另外,先容了丢失数据与数据值的处理惩罚要领。
1.数据范例
R 有很多的数据范例,包罗标量、向量(数值型、字符型和逻辑型)、矩阵、数据框和列表。
1.1向量
a <-
c(1,2,5.3,6,-2,4) #数值型向量b <-
c("one","two","three") #字符型向量c <- c(TRUE,TRUE,TRUE,FALSE,TRUE,FALSE) #逻辑型向量
用下标引用向量的元素:
a[c(2,4)] #向量的第2和第4个元素
1.2矩阵
矩阵中的所有列必需有沟通的模式(数值型、字符型等)和沟通的长度。 一般名目为:
mymatrix
<- matrix(vector, nrow=r, ncol=c, byrow=FALSE,
dimnames=list(char_vector_rownames, char_vector_colnames))
byrow=TRUE暗示矩阵按行填凑数据,byrow=FALSE暗示矩阵按列填凑数据。
#生成一个5 X 4 的数值型矩阵y<-matrix(1:20, nrow=5,ncol=4)
#另一个实例cells <- c(1,26,24,68)rnames <- c("R1", "R2")cnames <- c("C1", "C2") mymatrix <- matrix(cells, nrow=2, ncol=2,
byrow=TRUE, dimnames=list(rnames, cnames))
用下标符号矩阵的行、列和元素:
x[,4] #矩阵的第4列元素x[3,] #矩阵的第2行元素x[2:4,1:3] #矩阵中列号为1,2,3,行号为2,3,4的元素。
1.3数组
数组与矩阵相似,可是维度可以大于2。 可通过help(array) 查察更想具体的信息。
1.4数据框
数据框的观念较矩阵更为一般,差异列可以包括差异的模式(数值型、字符型、因子等)
。她与
SAS 和
SPSS 的数据集雷同。
d <-
c(1,2,3,4)e <- c("red", "white", "red",
NA)f <- c(TRUE,TRUE,TRUE,FALSE)mydata <- data.frame(d,e,f)names(mydata) <-
c("ID","Color","Passed") #列名
界说数据框中元素的要领有许多。
用下标来符号数据框中的行、列和元素:
myframe[3:5]
#选择数据框的第3,4,5列myframe[c("ID","Age")] #选择 数据框中的ID和年数列myframe$X1 #选择数据框中的 x1列
1.5列表
一些工具的有序荟萃。列表答允你整合若干(大概无关的)工具到单个工具名下。
#本例建设一个列表,个中有4个成份:一个字符串、一个数值型向量、一个矩阵和一个标量w <- list(name="Fred", mynumbers=a,
mymatrix=y, age=5.3)
#本例建设一个包括两个子列表的列表v <- c(list1,list2)
用[[]]这种约定符号来标志列表的成份:
mylist[[2]] #列表中的第2个成份mylist[["mynumbers"]] #列表中名为“mynumbers”的成份
1.6因子
名义变量(nominal varialbles)在R中成为因子。函数factor() 以一个整数向量的形式存储种别值,整数的取值范畴是[1…k](个中k是名义型变量中值的个数),同时一个由字符串(原始值)构成的内部变量将映射到这些整数上。
#性别变量有20个“male”实体和30个“female”实体gender <- c(rep("male",20),
rep("female", 30))gender <- factor(gender)
#将性别存储为20个1和30个2,并在内部将这些值关联为1=female,2=male(详细赋值按照字母顺序而定)。R将其作为名义型变量看待。summary(gender)
一个有序因子用来暗示一个有序型变量:
#变量rating被编码为"large",
"medium", "small"rating <- ordered(rating)
# 将rating 从头编码为1,2,3,并将这些值与"large",
"medium", "small"举办关联。
# 1=large,
2=medium, 3=small
# R将其作为有序型变量看待。
在统计进程与图形阐明中,R 将名义型变量和有序型变量作为因子看待。你可以利用 factor( ) 和 ordered( ) 函数中的选项来节制整数值到字符串的映射(重写字母表的顺序)。
你也利用因子来建设值标签。更多关于因子的内容请参照 UCLA
page.
1.7其他实用函数
length(object)
#显示工具中元素/成份的数量str(object) #显示某个工具的布局class(object) #显示某个工具的类可能范例names(object) #显示某个工具中各成份的名称
c(object,object,...) #将工具归并入一个向量cbind(object, object, ...) # 按列归并工具rbind(object, object, ...) #按行归并工具
