用 OpenBLAS 加快 R 的矩阵运算
话说 2010 年我和鸟兄去豆瓣做一个技能交换,阿稳现场展示了并行化计较的 R 情况,矩阵运算瞬间跑满了所有的 CPU,其时让我羡慕不已。多年之后在 第六届 R 语言集会会议 上,张先轶为各人展示了他们认真跟进研发的开源线性代数计较库 OpenBLAS,这个库成立在已经遏制开拓的 GotoBLAS2 上,对 Intel Sandy Bridge 有很是好的支持(机能上甚至同 MKL 八两半斤)。
线性代数库是 R 底层天然的并行运算的极好支持(Revolution R 利用的 MKL 库的支持),可以有效的提高 R 的计较效率。这里要再次感激中科院张先轶的孝敬!
OpenBLAS 的编译
OpenBLAS 的编译照旧较量利便的,假如没有非凡要求,下载直接执行快速安装即可
make
make install即可自行依照情况安装相关组件。
R 的编译
OpenBLAS 情况安装完毕后,即可安装 R 情况,同一般安装 R 雷同,需要增加如下参数:
./configure --disable-nls --with-blas="-lopenblas" --with-lapack --enable-R-shlib make make install
编译的时候大概会报 BLAS 相关的 so 找不到,凭据错误代码信息将文件拷贝至目次即可(或建 link)。
接下来我们比拟一下小我私家电脑的两种平台的计较环境:
先看 Windows 平台原生 R 情况下两个 6000
> x <- matrix(1:(6000 * 6000), 6000, 6000) > system.time(tmp <- x %*% x) user system elapsed 163.67 0.11 163.94 > system.time(tmp <- x %*% x) user system elapsed 163.71 0.11 163.99
再看利用 Open BLAS 加快的 R 的运算功效:
x <- matrix(1:(6000 * 6000), 6000, 6000) system.time(tmp <- x %*% x) user system elapsed 37.964 0.320 19.434 system.time(tmp <- x %*% x) user system elapsed 38.156 0.256 19.495
下图是我的 PC 双核欢畅的跑满(物理双核,虚拟四线程)资源的样子:
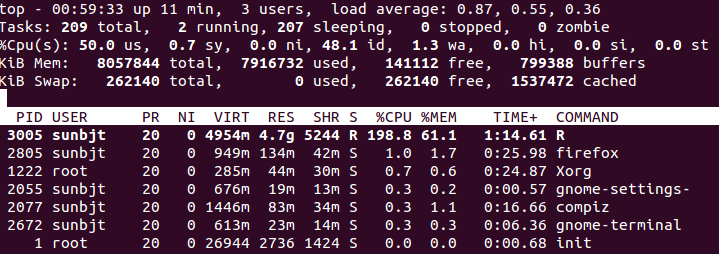
可见 Open BLAS 对付 R 的底层矩阵运算的晋升很是明明,可以想象假如在 R 中假如大量的利用向量化编程思路,计较所损耗的时间将会大大缩短。
留意:还未仔细实验其兼容性,请酌情利用
本文转载自:http://www.bjt.name/2013/06/open-blas-r/
