R与Cassandra 大数据分析强力组合
R作为开源的数据统计阐明语言正潜移默化的在企业中扩大本身的影响力。特有的扩展插件可提供免费扩展,而且答允R语言引擎运行在Hadoop集群之上。如今,Oracle的大数据方案中也呈现了R语言包的身影。
|
R语言是主要用于统计阐明、画图的语言和操尽兴况。R原来是由来自新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开拓。(也因此称为R)此刻由“R开拓焦点团队”认真开拓。R是基于S语言的一个GNU项目,所以也可以看成S语言的一种实现,凡是用 S语言编写的代码都可以不作修改的在R情况下运行。R的语法是来自Scheme。 R的源代码可自由下载利用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包罗UNIX(也包罗FreeBSD和Linux)、Windows和MacOS。R主要是以呼吁行操纵,同时有人开拓了几种图形用户界面。 |
此刻,统计事情者可操作R语言,R语言擅长在Hadoop漫衍式文件系统中存
储的非布局化数据的阐明。R此刻还可以运行在HBase这种非干系型的数据库以及面向列的漫衍式数据存储之上。其主要仿照了Google的
BigTable。这根基上等同于利用Hadoop来持有布局化数据的数据库。就像Apache软件基金会Hadoop项目标子项目HBase一样。同时
R已经可以与Cassandra
从Cassandra读取数据
先觉条件是RJDBC模块,而且Cassandra版本至少在1.0或以上以及Cassandra JDBC驱动。在以下示例中驱动和Cassandra位于同一目次
The example code assumes you have run through the Portfolio Manager Demo that comes with DSC/DSE
- #Load RJDBC
- library(RJDBC)
- #Load in the Cassandra-JDBC diver
- cassdrv <- JDBC("org.apache.cassandra.cql.jdbc.CassandraDriver",
- list.files("/Users/jake/workspace/bdp/resources/cassandra/lib/",pattern="jar$",full.names=T))
- #Connect to Cassandra node and Keyspace
- casscon <- dbConnect(cassdrv, "jdbc:cassandra://localhost:9160/PortfolioDemo")
- #Query timeseries data
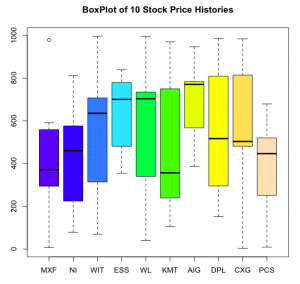
- res <- dbGetQuery(casscon, "select * from StockHist limit 10")
- #Transpose
- tres <- t(res[2:10])
- #Plot
- boxplot(tres,names=res$KEY,col=topo.colors(length(res$KEY)))
- title("BoxPlot of 10 Stock Price Histories")
而RCassandra包也是不错的选择
R、Cassandra和Hive
操作R会见Hive和Cassandra,在这里利用DataStax Enterprise,首先启动Hive处事器:dse hive –service hiveserver
- #Load RJDBC
- library(RJDBC)
- #Load Hive JDBC driver
- hivedrv <- JDBC("org.apache.hadoop.hive.jdbc.HiveDriver",
- c(list.files("/Users/jake/workspace/bdp/resources/hadoop",pattern="jar$",full.names=T),
- list.files("/Users/jake/workspace/bdp/resources/hive/lib",pattern="jar$",full.names=T)))
- #Connect to Hive service
- hivecon <- dbConnect(hivedrv, "jdbc:hive://localhost:10000/default")
- #Create Hive table mapping to Cassandra ColumnFamily
- tmp <- dbSendQuery(hivecon,"create external table StockHist(row_key string, column_name string, value double)
- STORED BY 'org.apache.hadoop.hive.cassandra.CassandraStorageHandler'
- WITH SERDEPROPERTIES ('cassandra.ks.name' = 'PortfolioDemo')")
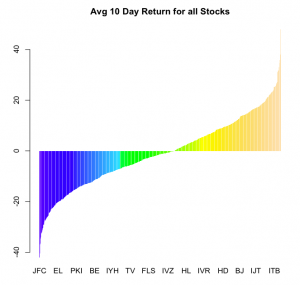
- #Run Hive Query to get returns
- hres <- dbGetQuery(hivecon,"select a.row_key ticker, AVG((b.value - a.value)) ret
- from StockHist a JOIN StockHist b on
- (a.row_key = b.row_key AND date_add(a.column_name,10) = b.column_name)
- group by a.row_key order by ret")
- #Plot
- barplot(hres[,2],names.arg=hres[,1],col = topo.colors(length(hres[,2])), border = NA)
- title("Avg 10 Day Return for all Stocks")
结论
以上事例显示出操作R会见Cassandra数据长短常简朴的,而两者的团结也为统计要领增加了强大的组合。
