R: 进修Gradient Boosting算法,提高预测模子精确率
引言预测模子的精确率可以用2种要领来提高:要么举办特征设计,要么直接利用boosting算法。介入过许大都据科学大赛后,我发明很多人喜欢用boosting算法,因为它只需更少的时间就能发生相似的功效。
今朝有很多boosting算法,如Gradient Boosting、 XGBoost,、AdaBoost和Gentle Boost等等。每个算法都有本身根基的数学道理而且在利用它们时城市发明有一些细微的变革。假如你刚打仗boosting算法,那太好了!以后刻开始你可以在一周内进修所有这些观念。
在本文中,我表明白Gradient Boosting算法的根基观念和巨大性。别的,我也分享了一个实例来进修它在R中的应用。
扼要的说明一旦利用boosting算法,你很快就会发明两个频繁呈现的术语:Bagging和Boosting。那么,它们有什么差异呢?下面将一一表明:
Bagging:这是一种要领,当你利用随机采样的数据,成立进修算法,采纳简朴的手段以找到bagging的大概性。
Boosting:与Bagging雷同,可是,对样本的选择更智能。我们随后会对难以分类的样天职配较大的权重。
好!我大白你脑中会发生雷同的疑问,像‘难以分类的样本’是什么意思?我怎么知道应该要给错误分类的样本几多特另外权重?不要着急,接下来我将答复你所有的疑问。
让我们从一个简朴的例子开始进修假设,你需要改造先前的模子M。此刻,你发明模子已经有80%(在所有指标下)的精确率。你奈何提高M的机能呢?
一种简朴的步伐是操作一个新的输入变量集成立一个完全差异的模子,并实验更好的进修模子。与之相反,我有一个更简朴的要领,该模子是这样的:
Y = M(x) + error
假如我可以或许看到误差(error)并不是白噪声,而是跟输出功效(Y)有相关性呢?倘若我们在误差项(error)上再成立一个模子呢?好比,
error = G(x) + error2
也许,你会看到误差率提高到一个更高的数字,好比84%。让我们继承另一个步调并对error2举办回归。
error2 = H(x) + error3
此刻,我们把所有这些组合到一起:
Y = M(x) + G(x) + H(x) + error3
这也许会有高出84%的精确率。假如我们可以或许找到这三个进修模子的每一个的优化权重呢?
Y = alpha * M(x) + beta * G(x) + gamma * H(x) + error4
假如我们找到了好的权重,我们很有大概做了一个更好的模子。这是boosting进修的根基原则。当我第一次读到这个理论时,很快我就发生了2个问题:
1. 在回归/分类等式中我们能真正看到非白噪声误差么?假如不能,我们怎么能利用这个算法。
2. 假如这有大概的话,为什么没有靠近100%的精确率呢?
在本文中我将以清晰简捷的方法来答复这些问题,Boosting凡是用于弱进修,即没有疏散白噪声的本领。第二,因为boosting会导致过拟合,所以我们需要在正确的时间点遏制。
让我们试试把一个分类问题可视化
请看下面的图表:
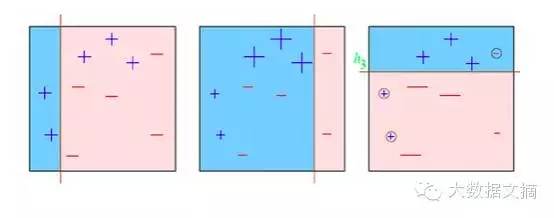
我们从第一个箱线图开始。我们看到一条垂直线,这是我们的第一个弱进修模子。这时我们有3/10的误分类率。此刻我们对3个误分类的样天职配更高的权重,此时,对它们分类很是重要。因此,垂直线向右边沿接近。我们反复这个操纵,然后以得当的权重组合每个进修模子。
相关数学观念的表明
如何给样天职配权重
我们以匀称漫衍的假设开始。将它记作D1,即在n个样本中呈现的概率为1/n。
步调1:假设alpha(t)步调2:获得弱分类功效h(t)步调3:在下次迭代中更新的总量漫衍
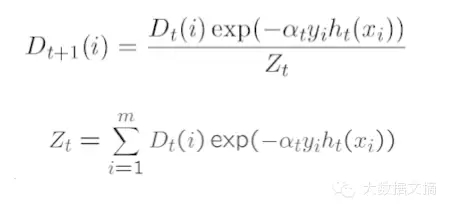
步调4:在下次迭代中利用新的总量漫衍来找到下一个进修模子
被步调3的数学表达式吓到了么?我来给你表明一下。简朴地看一下e指数的参数,alpha是进修率,y是真实的响应(+1或-1),h(x)是通过进修获得的预测分类。本质上,假如进修有错误的话,e指数的值酿成1*alpha可能-1*alpha。重要的是,假如最后一次预测堕落,权重将会增加。那么接下来怎么做呢?
步调5:迭代步调1至步调4直到找不到假设可以进一步提高。
步调6:到今朝为止,在所有用到的进修模子前利用加权平均。可是权重是几多呢?这里权重就是alpha值,alpha的计较公式如下:
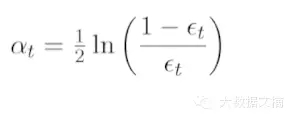
是时候实践一下了,下面是个实例
最近我介入了由Analytics Vidhya组织的在线编程马拉松。为了变量转换更容易,我把文件complete_data中的测试数据和练习数据组合起来利用。我从根基的导入函数开始,把总量分到Devlopment、ITV和Scoring中。
#加载caret包,清空事情空间变量,并配置事情空间library(caret)rm(list=ls())setwd(“C:\\Users\\ts93856\\Desktop\\AV”)#导入Metrice包library(Metrics)#读取complete_data.csv文件complete <- read.csv(“complete_data.csv”, stringsAsFactors = TRUE)#提取练习集,评分集train <- complete[complete$Train == 1,]score <- complete[complete$Train != 1,]#配置随机种子set.seed(999)#对练习集和测试集举办采样ind <- sample(2, nrow(train), replace=T, prob=c(0.60,0.40))trainData<-train[ind==1,]testData <- train[ind==2,]set.seed(999)ind1 <- sample(2, nrow(testData), replace=T, prob=c(0.50,0.50))trainData_ens1<-testData[ind1==1,]testData_ens1 <- testData[ind1==2,]table(testData_ens1$Disbursed)[2]/nrow(testData_ens1)#Response Rate of 9.052%
下面你要做的是成立GBM模子。
fitControl <- trainControl(method = “repeatedcv”, number = 4, repeats = 4)trainData$outcome1 <- ifelse(trainData$Disbursed == 1, “Yes”,”No”)set.seed(33)#将练习数据放入练习池中对模子参数练习,这里采样线性模子,要领回收gbm预计gbmFit1 <- train(as.factor(outcome1) ~ ., data = trainData[,-26], method = “gbm”, trControl = fitControl,verbose = FALSE)#测试数据套入模子中举办验证预测gbm_dev <- predict(gbmFit1, trainData,type= “prob”)[,2]gbm_ITV1 <- predict(gbmFit1, trainData_ens1,type= “prob”)[,2]gbm_ITV2 <- predict(gbmFit1, testData_ens1,type= “prob”)[,2]#计较模子AUC曲线auc(trainData$Disbursed,gbm_dev)auc(trainData_ens1$Disbursed,gbm_ITV1)auc(testData_ens1$Disbursed,gbm_ITV2)
在这段代码运行竣事后,正如你所看到的,所有AUC值将很是靠近0.84,我将把特征设计的任务留给你,因为角逐还在继承举办中。同时接待你利用此代码来介入角逐。GBM是更为遍及利用的算法。XGBoost是别的一个提高进修模子的较快版本。
结语我已经发明boosting进修很是快并且极其高效。它们从来不让我失望,老是能在kaggle或其它平台上能得到较高的初始评分。然而,这一切还取决你如何举办好的特征设计。
你以前利用过Gradient Boosting么?模子运行功效如何?你有没有利用boosting进修来提高其它方面的本领。
