用R语言举办分位数回归 第二节
(一)安装和加载包 R语言的根基包中没有举办分位数回归的措施包,故需要在官网下载并安装相应的措施包quantreg。在电脑上安装过quantreg包今后,下次不需要再次安装了。但每次利用分位数回归前,需要加载quantreg包。
| install.package(“quantreg”) # 保持联网的环境下安装包library(“quantreg”) # 加载包help.start() # 进入R辅佐首页help(rq) # 获取rq函数的辅佐,也可以写成:?rqexample(rq) # 显示分位数回归函数rq()的一个简朴示例代码 |
(二)一个简朴的分位数回归模子及功效
| data(engel) # 加载quantreg包自带的数据集,见说明①fit1 = rq(foodexp ~ income, tau = 0.5, data = engel) # 举办分位数回归,见说明②fit1 # 直接显示分位数回归的模子和系数,见说明③summary(fit1) # 获得越发具体的显示功效,见说明④r1 = resid(fit1) # 获得残差序列,并赋值为变量r1c1 = coef(fit1) # 获得模子的系数,并赋值给变量c1,见说明⑤summary(fit1, se = “nid”) # 通过配置参数se,可以获得系数的假设检讨,说明⑥ |
说明:① engel(1857)是考查食物支出与家庭收入之间干系的一个数据集,用函数head(engel)可以查察前六行的值:
# income foodexp
# 1 420.1577 255.8394
# 2 541.4117 310.9587
# 3 901.1575 485.6800
# 4 639.0802 402.9974
# 5 750.8756 495.5608
# 6 945.7989 633.7978
② 这里因变量为foodexp,即食物支出。自变量为income,即家庭收入。
– tau暗示计较50%分位点的参数,这里可以同时计较多个分位点的分位数回归功效,如tau=c(0.1,0.5,0.9)是同时计较10%、50%、90%分位数下的回归功效。
– data=engel指明这里处理惩罚的数据集为engel。
– method:举办拟合的要领,取值包罗:A. 默认值“br”,暗示 Barrodale & Roberts 算法的修改版;B. “fn”,针对大数据可以回收的Frisch–Newton内点算法;C. “pfn”,针对出格大数据,利用颠末预处理惩罚的Frisch–Newton迫近要领;D. “fnc”,针对被拟合系数非凡的线性不等式约束环境;E. “lasso”和“scad”,基于特定处罚函数的滑腻算法举办拟合。
③ 直接运行fit1,会获得简朴的计较功效,如:
# Call:
# rq(formula = foodexp ~ income, tau = 0.5, data = engel)
#
# Coefficients:
# (Intercept) income
# 81.4822474 0.5601806
#
# Degrees of freedom: 235 total; 233 residual
④ 用summary()函数可以获得回归模子的具体功效,包罗系数和上下限。
# Call: rq(formula = foodexp ~ income, tau = 0.5, data = engel)
#
# tau: [1] 0.5
#
# Coefficients:
# coefficients lower bd upper bd
# (Intercept) 81.48225 53.25915 114.01156
# income 0.56018 0.48702 0.60199
⑤ coef()函数获得的系数为向量形式,第一个元素为常数项的系数,第二个及今后为自变量的系数。
⑥ summary函数se参数的说明:
A. se = “rank”: 凭据Koenker(1994)的排秩要领计较获得的置信区间,默认残差为独立同漫衍。留意的是,上下限是差池称的。
Coefficients:
coefficients lower bd upper bd
(Intercept) 81.48225 53.25915 114.01156
income 0.56018 0.48702 0.60199
B. se=”iid”: 假设残差为独立同漫衍,用KB(1978)的要领计较获得近似的协方差矩阵。
Coefficients:
Value Std. Error t value Pr(>|t|)
(Intercept) 81.48225 13.23908 6.15468 0.00000
income 0.56018 0.01192 46.99766 0.00000
C. se = “nid”: 暗示凭据Huber 要领迫近获得的预计量。
Coefficients:
Value Std. Error t value Pr(>|t|)
(Intercept) 81.48225 19.25066 4.23270 0.00003
income 0.56018 0.02828 19.81032 0.00000
D. se=”ker”: 回收Powell(1990)的核预计要领。
Coefficients:
Value Std. Error t value Pr(>|t|)
(Intercept) 81.48225 30.21532 2.69672 0.00751
income 0.56018 0.03732 15.01139 0.00000
E. se=”boot”: 回收bootstrap要领自助抽样的要领预计系数的误差尺度差。
Coefficients:
Value Std. Error t value Pr(>|t|)
(Intercept) 81.48225 25.23647 3.22875 0.00142
income 0.56018 0.03194 17.53752 0.00000(三)差异分位点下的回归功效较量 1、差异分为点系数预计值的较量
| # 差异分位点下的系数预计值的较量fit1 = summary( rq(foodexp ~ income, tau = 2:98/100) )fit2 = summary( rq(foodexp ~ income, tau = c(0.05,0.25,0.5,0.75,0.95)) )windows(5,5) # 新建一个图形窗口,可以去掉这句plot(fit1)windows(5,5) # 新建一个图形窗口,可以去掉这句plot(fit2) |
功效: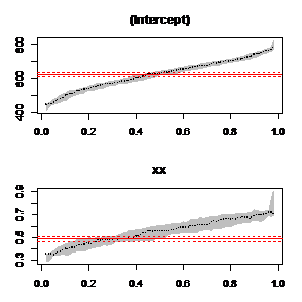 图2.1 99个分位点的系数预计值
图2.1 99个分位点的系数预计值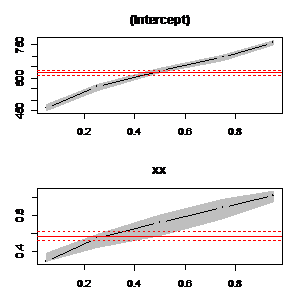 图2.2 5个分位点的系数预计值 2、差异分位点拟合曲线的较量
图2.2 5个分位点的系数预计值 2、差异分位点拟合曲线的较量
| # 散点图attach(engel) # 打开engel数据集,直接运行个中的列名,就可以挪用相应列plot(income,foodexp,cex=0.25,type=”n”, # 绘图,说明① xlab=”Household Income”, ylab=”Food Expenditure”)points(income,foodexp,cex=0.5,col=”blue”) # 添加点,点的巨细为0.5abline( rq(foodexp ~ income, tau=0.5), col=”blue” ) # 画中位数回归的拟合直线,颜色蓝abline( lm(foodexp ~ income), lty = 2, col=”red” ) # 画普通最小二乘法拟合直线,颜色红taus = c(0.05, 0.1, 0.25, 0.75, 0.9, 0.95) for(i in 1:length(taus)){ # 绘制差异分位点下的拟合直线,颜色为灰色 abline( rq(foodexp ~ income, tau=taus[i]), col=”gray” )}detach(engel) |
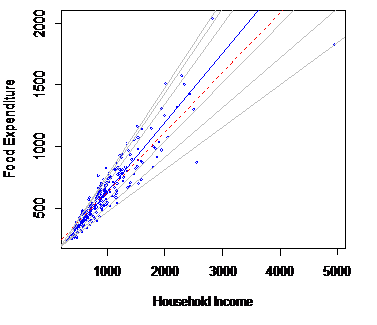 图2.3 差异分位点下的分位数回归拟合功效较量 3、穷人和富人的消费漫衍较量
图2.3 差异分位点下的分位数回归拟合功效较量 3、穷人和富人的消费漫衍较量
| # 较量穷人(收入在10%分位点的那小我私家)和富人(收入在90%分位点的那小我私家)的预计功效# rq函数中,tau不在[0,1]时,暗示按最细的分位点分别方法获得分位点序列z = rq(foodexp ~ income, tau=-1) z$sol # 这里包括了每个分位点下的系数预计功效x.poor = quantile(income, 0.1) # 10%分位点的收入x.rich = quantile(income, 0.9) # 90%分位点的收入ps = z$sol[1,] # 每个分位点的tau值qs.poor = c( c(1,x.poor) %*% z$sol[4:5,] ) # 10%分位点的收入的消费预计值qs.rich = c( c(1,x.rich) %*% z$sol[4:5,] ) # 90%分位点的收入的消费预计值windows(10,5)par(mfrow=c(1,2)) # 把画图区域分别为一行两列plot(c(ps,ps),c(qs.poor,qs.rich),type=”n”, # type=”n”暗示初始化图形区域,但不绘图 xlab=expression(tau), ylab=”quantile”)plot(stepfun(ps,c(qs.poor[1],qs.poor)), do.points=F, add=T)plot(stepfun(ps,c(qs.poor[1],qs.rich)), do.points=F, add=T, col.hor=”gray”, col.vert=”gray”)ps.wts = ( c(0,diff(ps)) + c(diff(ps),0) )/2ap = akj(qs.poor, z=qs.poor, p=ps.wts)ar = akj(qs.rich, z=qs.rich, p=ps.wts)plot(c(qs.poor,qs.rich), c(ap$dens, ar$dens), type=”n”, xlab=”Food Expenditure”, ylab=”Density”)lines(qs.rich,ar$dens,col=”gray”)lines(qs.poor,ap$dens,col=”black”)legend(“topright”, c(“poor”,”rich”), lty=c(1,1), col=c(“black”,”gray”)) |
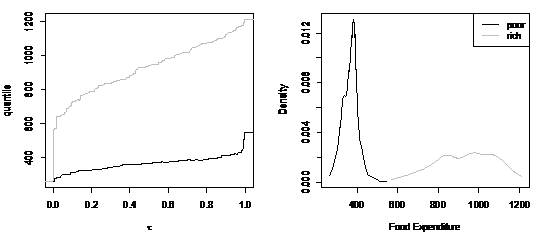 图2.4 10%分位点和90%分位点之间的较量 上图暗示收入(income)为10%分位点处(poor,穷人)和90%分位点处(rich,富人)的食品支出的较量。从左图可以发明,对付穷人而言,在差异分位点预计的食品消费不同不大。而对付富人而言,在差异分位点对食品消费的不同较量大。右图回响了穷人和富人的食品消费漫衍曲线。穷人的食品消费会合于400阁下,较量陡峭;而富人的消费支出会合于800到1200之间,较量分手。(四)模子较量
图2.4 10%分位点和90%分位点之间的较量 上图暗示收入(income)为10%分位点处(poor,穷人)和90%分位点处(rich,富人)的食品支出的较量。从左图可以发明,对付穷人而言,在差异分位点预计的食品消费不同不大。而对付富人而言,在差异分位点对食品消费的不同较量大。右图回响了穷人和富人的食品消费漫衍曲线。穷人的食品消费会合于400阁下,较量陡峭;而富人的消费支出会合于800到1200之间,较量分手。(四)模子较量
| # 较量差异分位点下,收入对食品支出的影响机制是否沟通fit1 = rq(foodexp ~ income, tau = 0.25)fit2 = rq(foodexp ~ income, tau = 0.5)fit3 = rq(foodexp ~ income, tau = 0.75)anova(fit1,fit2,fit3) |
功效:
Quantile Regression Analysis of Deviance Table
Model: foodexp ~ income
Joint Test of Equality of Slopes: tau in { 0.25 0.5 0.75 }
Df Resid Df F value Pr(>F)
1 2 703 15.557 2.449e-07 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1个中P值远小于0.05,故差异分位点下收入对食品支出的影响机制差异。(五)残差形态的检讨
也可以领略为是较量差异分位点的模子之间的干系。主要有两种模子形式:
(1)位置漂移模子:差异分位点的预计功效之间的斜率沟通或近似,只是截距差异;表示为差异分位点下的拟合曲线是平行的。
(2)位置-标准漂移模子:差异分位点的预计功效之间的斜率和截距都差异;表示为差异分位点下的拟合曲线不是平行的。
| # 残差形态的检讨source(“C:/Program Files/R/R-2.15.0/library/quantreg/doc/gasprice.R”)x = gaspricen = length(x)p = 5X = cbind(x[(p-1):(n-1)],x[(p-2):(n-2)],x[(p-3):(n-3)],x[(p-4):(n-4)])y = x[p:n]# 位置漂移模子的检讨T1 = KhmaladzeTest(y~X, taus = -1, nullH=”location”)T2 = KhmaladzeTest(y~X, taus = 10:290/300, nullH=”location”, se=”ker”)# 位置标准漂移模子的检讨T3 = KhmaladzeTest(y~X, taus = -1, nullH=”location-scale”)T4 = KhmaladzeTest(y~X, taus = 10:290/300, nullH=”location-scale”, se=”ker”) |
功效:运行T1,可以查察其检讨功效。个中nullH暗示原假设为“location”,即原假设为位置漂移模子。Tn暗示模子整体的检讨,统计量为4.8。THn是对每个自变量的检讨。较量T1和T3的功效(T3的原假设为“位置标准漂移模子”),T1的统计量大于T3的统计量,可见相对而言,拒绝“位置漂移模子”的概率更大,故相对而言“位置标准漂移模子”越发符合一些。
> T1
$nullH
[1] “location”
$Tn
[1] 4.803762
$THn
X1 X2 X3 X4
1.0003199 0.5321693 0.5020834 0.8926828
attr(,”class”)
[1] “KhmaladzeTest”
> T3
$nullH
[1] “location-scale”
$Tn
[1] 2.705583
$THn
X1 X2 X3 X4
1.2102899 0.6931785 0.5045163 0.8957127
attr(,”class”)

[1] “KhmaladzeTest”
关键字:
