Deep Learning in R · R语言深度进修
本文译自2016年3月7日OKSANA KUTKINA和STEFAN FEUERRIEGEL在R Blog上颁发的《Deep Learning in R》,英文原文链接:http://www.rblog.uni-freiburg.de/2017/02/07/deep-learning-in-r/
Introduction 深度进修是呆板进修规模的一大热点,它可以对非常非线性的数据(包罗图像等)举办建模。在已往的几年,深度进修在各应用规模揭示了惊人的成长势头(Wikipedia 2016a)。个中包罗图像和声音识别、无人驾驶、自然语言处理惩罚等。有趣的是,深度进修有关的大部门的数学道理早在几十年前就存在了。然而,它的潜能是通过近期的一些规模的应用才得以有效的解放(Nair and Hinton 2010; Srivastava et al. 2014)。
已往,由于梯度下降及太过拟合的问题,人工神经网络是很难实现的。如今,通过差异的激活函数、正则化、大量的练习数据集可以办理上述的问题。好比,操作互联网可以获取大量的有标签或无标签的数据。别的,GPUs和GPGPUs(通用计较)使得计较进程更快,本钱更低。
当前,深度进修在险些所有的呆板进修任务中表示出精采的机能,出格适合于巨大的、多条理的数据。最根基的就是通过人工神经网络模子处理惩罚非常非线性的数据,而这些数据凡是是多层面的、非线性的、具有非凡布局的。典范的深度神经网络如下图。
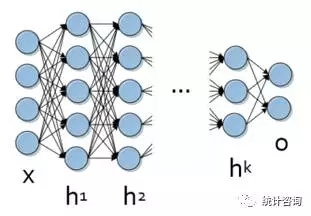
深度进修的乐成使得大量的编程语言有关深度进修的资源应运而生。个中包罗Caffee、Theano、Torch、Tensor Flow等。本文将对几个深度进修相关的R包举办先容和较量。
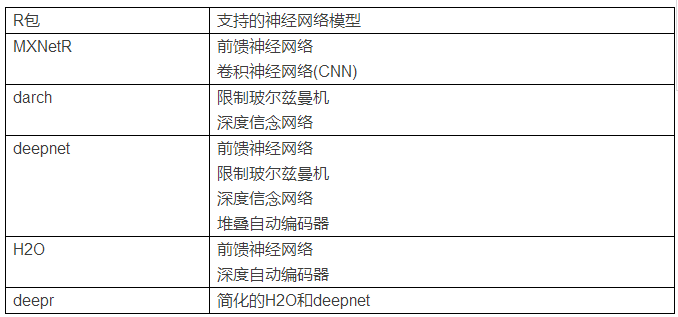
Packages for deep learning in R R语言因其轻便机动、可视化成果强大等在统计学家和数据挖掘阐明师中深受接待。跟着深度进修的成长,一系列深度进修的R包也出来了。我们将先容MXNetR、darch、deepnet、H2O、deepr等五个主要的R包。下表展示的是几个R包的异同。
Package “MXNetR”MXNetR是基于C语言的MXNet库的一个几口。它可以举办前馈神经网络和卷积神经网络(MXNetR 2016a)。也答允我们自界说模子。该R包分为CPU和GPU两个版本,前者通过R软件可以直接安装,尔后者需要继承第三方的一些库如cuDNN等(MXNetR 2016b)。
前馈神经网络例子
①通过封装的函数实现:model <- mx.mlp(train.x, train.y, hidden_node=c(128,64), out_node=2, activation=”relu”, out_activation=”softmax”,num.round=100, array.batch.size=15, learning.rate=0.07, momentum=0.9, device=mx.cpu())
②通过自界说模子实现:data <- mx.symbol.Variable(“data”) fc1 <- mx.symbol.FullyConnected(data, num_hidden=128) act1 <- mx.symbol.Activation(fc1, name=”relu1″, act_type=”relu”) fc2 <- mx.symbol.FullyConnected(act1, name=”fc2″, num_hidden=64) act2 <- mx.symbol.Activation(fc2, name=”relu2″, act_type=”relu”) fc3 <- mx.symbol.FullyConnected(act2, name=”fc3″, num_hidden=2) lro <- mx.symbol.SoftmaxOutput(fc3, name=”sm”)
model2 <- mx.model.FeedForward.create(lro, X=train.x, y=train.y, ctx=mx.cpu(), num.round=100, array.batch.size=15, learning.rate=0.07, momentum=0.9)
可见,MXNetR通过mx.mlp函数可以快速设计尺度的模子,也可以通过自界说参数实现同样的成果。
Package “darch”darch(2015)可以实现深度信念网络和限制玻尔兹曼机模子。它还可以举办微调反馈和选择性的前练习。
深度信念网络的例子darch <- darch(train.x, train.y, rbm.numEpochs = 0, rbm.batchSize = 100, rbm.trainOutputLayer = F, layers = c(784,100,10), darch.batchSize = 100, darch.learnRate = 2, darch.retainData = F, darch.numEpochs = 20)
总的来说,darch的根基利用很是简朴,它只利用一个函数对网络举办练习,可是这也限制了它举办越发深入的深度信念网络进修,因为往往需要更多的练习。
Package “deepnet”deepnet(2015)是一个相对较小而强大的包。nn.train()函数可以实现前反馈神经网络模子,dbn.dnn.train()可以初始化深度信念模子的权重,rbm.train()可以实现限制玻尔兹曼机模子,sae.dnn.train()可以实现堆叠自动编码器模子。
前反馈神经网络的例子nn.train(x, y, initW=NULL, initB=NULL, hidden=c(50,20), activationfun=”sigm”, learningrate=0.8, momentum=0.5, learningrate_scale=1, output=”sigm”, numepochs=3, batchsize=100, hidden_dropout=0, visible_dropout=0)
总之,deepnet是一个轻量级的,设定少数的参数,却能实现大都的模子。
Package “H2O”H2O(2015)本来是一个可以操作漫衍式计较机系统的开源软件平台。它是基于Java语言搭建的,要求版的JVM和JDK(https://www.java.com/en/download/)。该R包提供了许多语言的接口,而且源于云端处事的设计(Candel et al. 2015)。
深度自动编码器的例子anomaly_model <- h2o.deeplearning( x = names(train), training_frame = train, activation = “Tanh”, autoencoder = TRUE, hidden = c(50,20,50), sparse = TRUE, l1 = 1e-4, epochs = 100)
总之,H2O是一个高度用户有好的R包,可以实现前馈神经网络和深度自动编码器,还支持漫衍式计较,甚至提供网络接口。
Package “deepr”deepr(2015)自身其实并不能实现深度进修的算法,当初是由于H2O包在CRAN上不行用时作为补充的。所以它只是引用了H2O和deepnet的某些函数。
Comparison of Packages 我们将从易用性、机动性、易安装性、并行运算支持性、超参数选择性等几方面举办较量。借助常用的数据集Iris、MNIST、Forest Cover Type等为用户提供符合的R包提供参考。
INSTALLATION通过CRAN安装R包长短常轻便的。可是以上某些R包需要第三方库的支持。好比,H2O要求版的Java和JDK。由于darch答允利用GPU,所以darch要基于gputools包,并且它只支持Linux和MacOS系统;MXNetR默认是不开放GPU成果的,因为它基于的cuDNN存在版权的问题,所以GPU版本要求Rtools和C++软件来支持封装来自CUDA SDK和cuDNN的代码。
FLEXIBILITY在机动性利便,MXNetR应该是排在第一位的。由于它分层界说模子的特点,无需配置大量的参数就可以实现差异的模子。在我们看来,H2O和darch应该是排在第二位的。H2O主要存眷前反馈神经网络和深度自动编码器,而darch则存眷限制玻尔兹曼机和深度信念网络。两个包都提供了许多可调解的参数。deepnet是一个相对轻量级的包,主要的利益在于可以拟合多种差异的模子。可是我们不推荐日常利用非GPU版本的deepnet对较大的数据举办阐明,因为相对较少的参数使它不能微调至抱负的模子。
EASE-OF-USEH2O和MXNetR因其速度和易用性而精彩的。MXNetR不要求对数据举办预处理惩罚;而H2O通过as.h2o()函数将数据转换为H2O工具。两个包都提供模子检讨的东西。deepnet凡是把标签作为单特征编码矩阵,这就要求许多的数据初始化事情,因为很大都据集的类储存为向量的名目。可是它不会陈诉这个初始化事情的进程。别的,deepnet也缺乏模子检讨的东西。相反,darch有一个很清晰并且具体的输出。
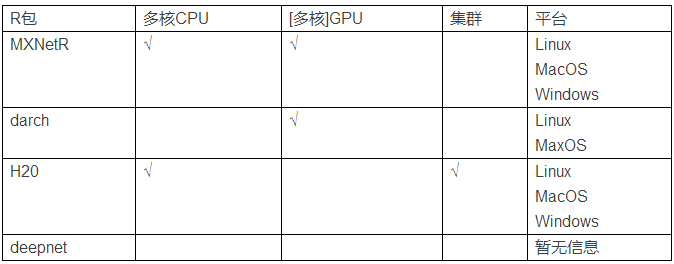
PARALLELIZATION深度进修之所以成为趋势得力于它可以处理惩罚大数据集。所以,假如R包可以支持并行运算,对付深度进修将会是极大的辅佐。下表展示的是几个R包对并行运算的支持性。#p#分页标题#e#
CHOICE OF PARAMETERS另一个重要的方面是超参数的选择性。H2O回收一种全自动的前神经元调解进修算法使其可以或许很快的收敛。它也可以通过交错验证和区域搜寻的要领来优化参数以及模子筛选。
MXNetR会给出每次迭代的练习正确性,darch会给出每次建模的误差。这都答允我们手动的选择差异的参数,由于练习进程可以按照迭代的功效提前终止,而无需比及算法收敛。相反,deepnet没有在练习竣事之前给出任何信息,导致参数选择很是具有挑战性。
Conclusion 通过上面的先容和阐明,我们可知:当前版本的deepnet可以或许实现较大的模子,但在速度和用户友好方面欠佳,也未能支持参数的调解。H2O和MXNetR,相对来说,提供了用户友好的体验。两者都提供参数调解的参考,练习时间快,并且凡是能获得较量好的功效。H2O更适合集群运算的情况,数据阐明师可以通过直接的管道举办数据挖掘和摸索。当我门越发存眷机动性和模子设计方面,MXNetR将会是最符合的选择。它提供了直观的标记东西使我们利便举办自界说。别的,它可以在小我私家电脑上利用多核CPU/GPU举办优化。darch提供了少数但专注于深度信念网络的函数。
总之,R语言可以很好地举办深度进修。H20和MXnetR可以说是R用户强大的深度进修东西,Caffe和TorchIn等更多的接口将会涌现。尽量与其他编程语言对比,R语言在深度进修方面还不是很有优势,但我们相信,逾越必定在不久的未来!
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
