Rattle:数据挖掘的界面化操纵
R语言是一个自由、免费、源代码开放的软件,它是一个用于统计计较和统计制图的优秀东西。这里的统计计较可以是数据阐明、建模或是数据挖掘等,通过无数大牛提供的软件包,可以帮我们轻松实现算法的实施。
一些读者以为R语言琐屑的对象太多了,无法记着那么多函数和成果,于是就问R语言有没有一种雷同于SAS之EM或SPSS之Modeler的界面化操纵。很幸运,Graham等人特地为“偷懒”的阐明师写了rattle包,通过该包就可以实现界面化操纵的数据阐明、数据挖掘流程。下面就跟各人具体先容一些这款免费的东西:
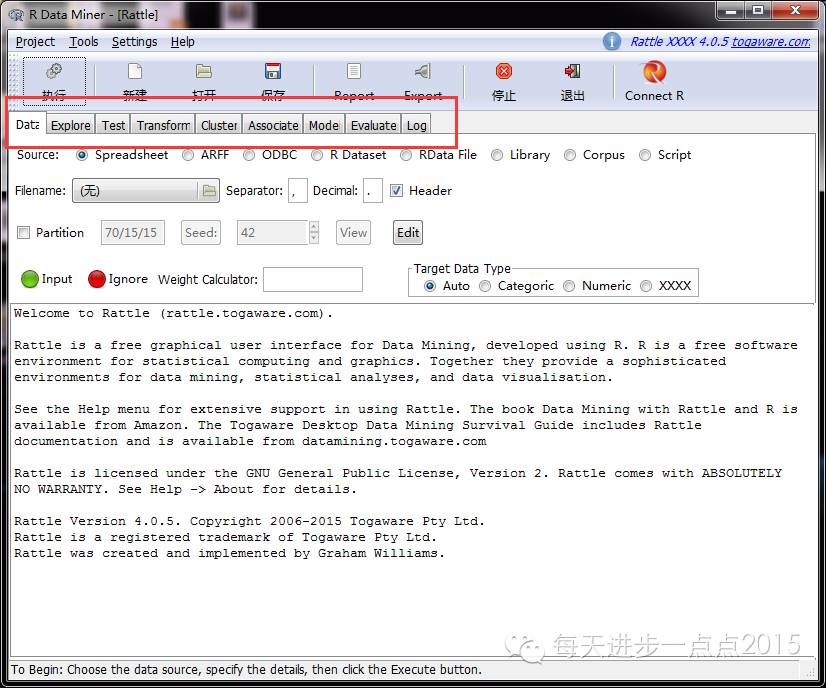
上图赤色区域就是数据阐明与挖掘的流程,包罗:数据源(Data)–>数据摸索与检讨(Explore、Test)–>数据调动(Transform)–>数据挖掘(Cluster、Associate、Model)–>模子评估(Evaluate)。
首先,你会经验“一劳永逸”的进程:安装rattle包不瞒您说,我首次在本身的64位Win7系统中安装rattle包时耗费了不少工夫。当你install.packages(‘rattle’)时,以为很是轻松就下载好了,可是进入library(rattle)并输入rattle()时它会陈诉各类.dll文件不存在。假如您抉择要试试,就下载缺失的dll文件到您的电脑里。
其次,我们来先容一下rattle数据挖掘操纵界面都有哪些对象:
1)数据源(Data)
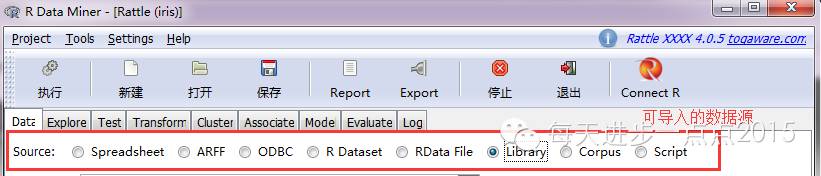
一切数据阐明与挖掘都发源于数据,故第一步就是往rattle中导入数据源,数据源可以是外部数据源,如txt文件、csv文件、Excel文件等;也可以是数据库数据,通过ODBC毗连诸如SQL Server、MySQL等数据库;也可以是当前R空间下的数据集;也可以是外部R数据集文件、还可以是R包自带的数据集。
2)数据摸索与检讨(Explore、Test)
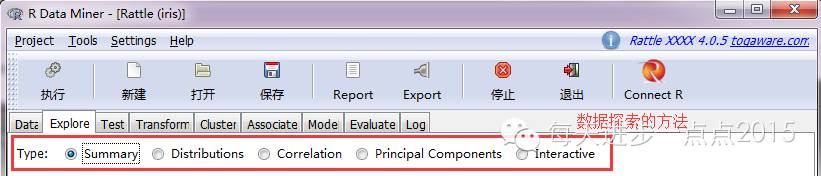
有了数据后,需要举办数据摸索,如汇总(Summary)、漫衍(Distributions)、相关性阐明(Correlation)、主身分阐明(Principal Components)、t检讨、F检讨、K-S正态性检讨、Wilcoxon检讨等
3)数据调动(Transform)
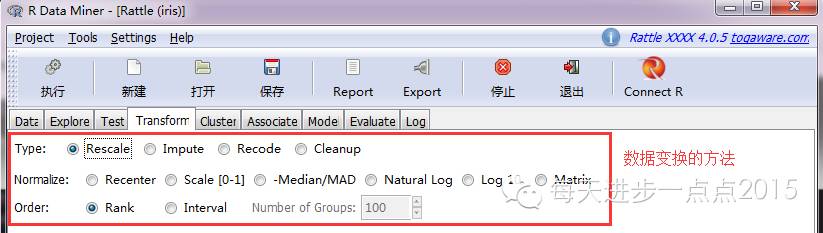
当数据存在缺失或需要重新编码、尺度化时,就需要这里的数据调动了
4)数据挖掘(Cluster、Associate、Model)
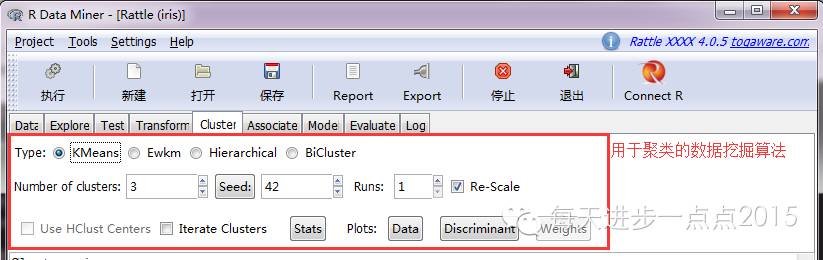
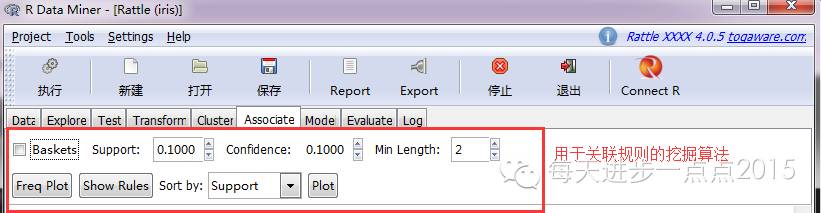
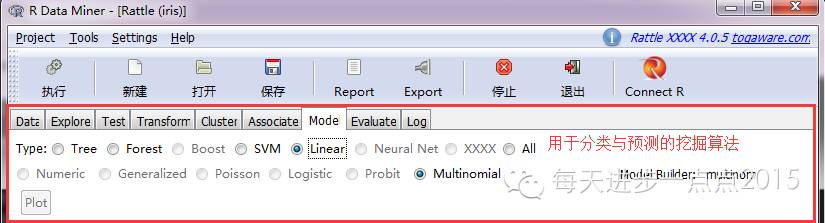
当数据清洗清洁或对数据有了根基相识后,就要进入数据挖掘进程,rattle东西提供了常用的数据挖掘算法,如:K-means聚类、条理聚类、关联法则、决定树、随机丛林、支持向量机、线性回归、Logistic回归、神经网络等
5)模子评估(Evaluate)
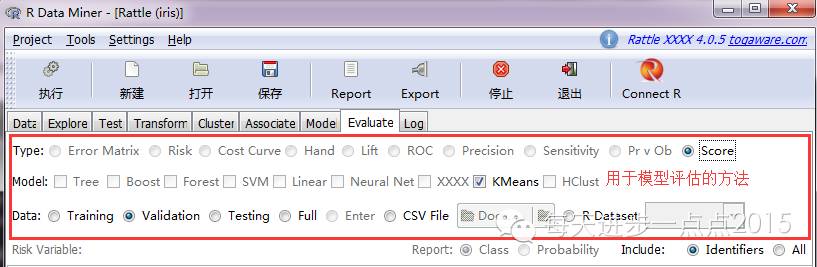
当模子选定,并进入模子运算后,需要对模子举办评估,选择较量抱负的模子用着后期数据的陈设。有关模子评估,rattle提供了夹杂矩阵、风险矩阵、本钱曲线、Lift曲线、ROC曲线等要领。
最后,我们就用这个rattle做一个实战,数据集就利用C50包中的churnTrain,该数据集是德国某电信公司客户是否流失的数据集。
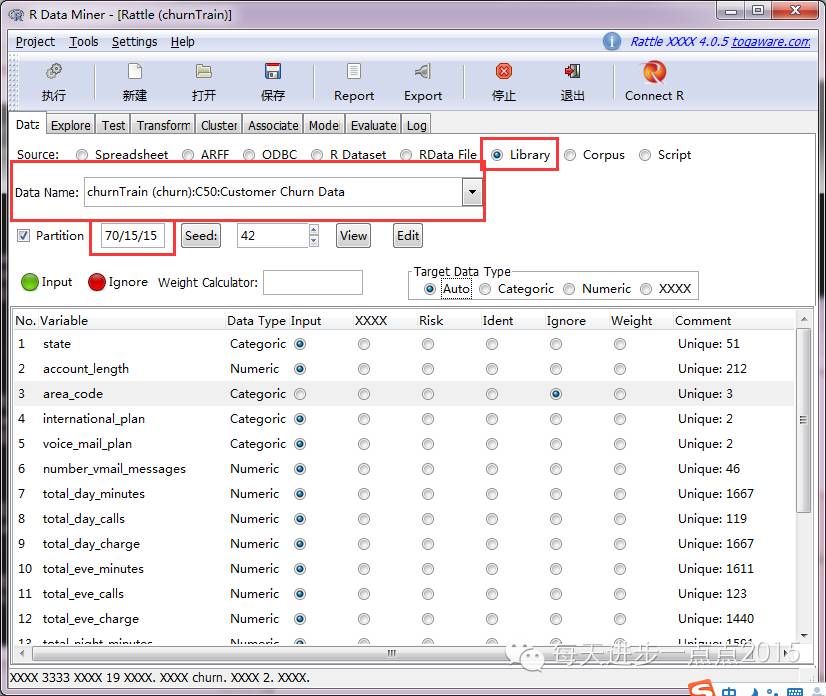
1)读取数据集选择好数据集后,点击“执行”,默认数据集将分为三个子集,即练习集占70%、练习集和检讨集各占15%,最后将指定哪些变量为表明变量和被表明变量,如有不需要的变量,则选为“Ignore”
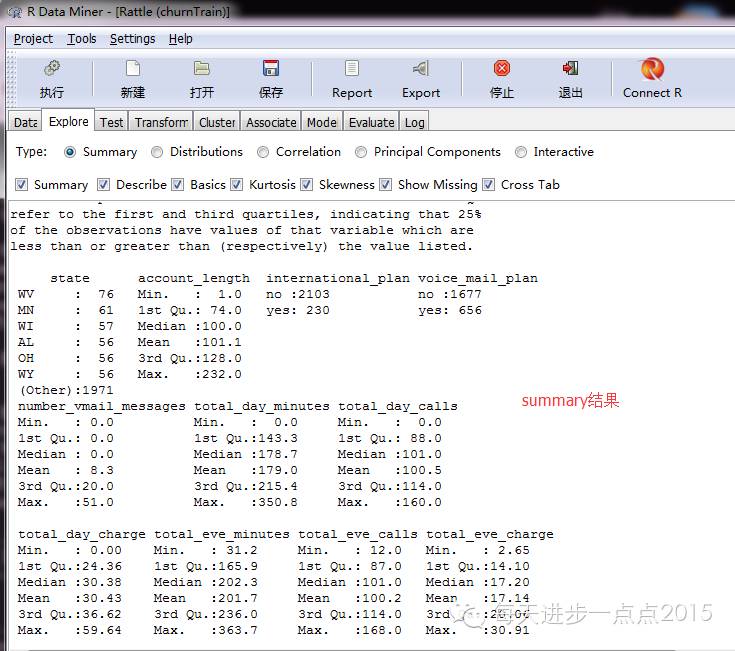
2)数据摸索选择Summary单选、并选择Summary、Describe、Basic、Kurtosis等复选框后,看看都有哪些返回功效:Summary功效
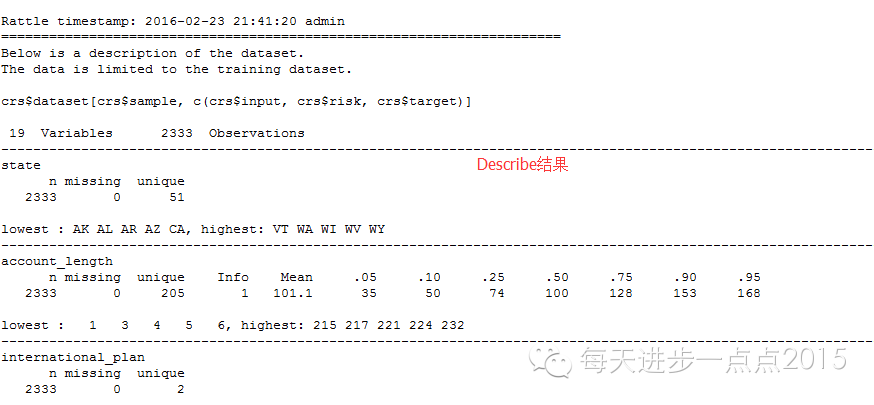
Discribe功效
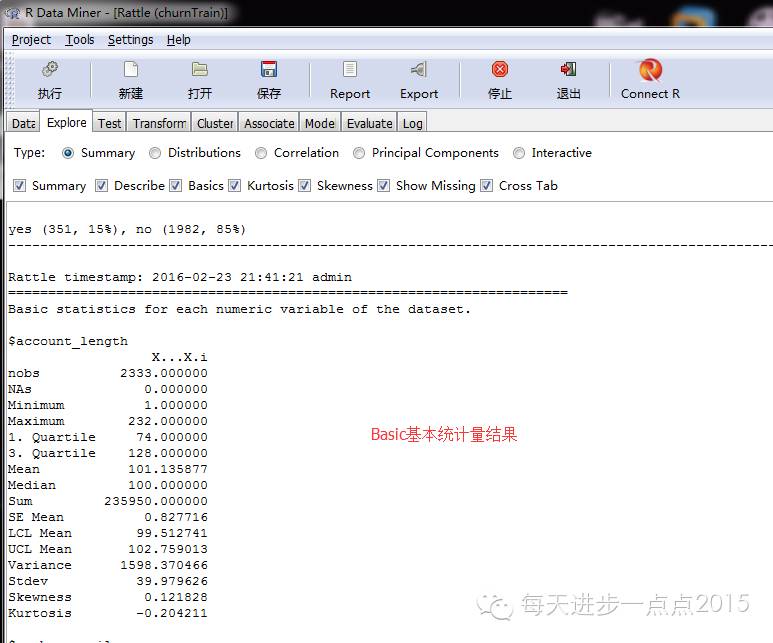
Basic根基统计量功效
尚有很大都据摸索的内容,这里就纷歧一说明白,但愿读者能自行执行,并相识数据的大抵环境。
3)数据挖掘判定客户是否流失,是一种分类问题,下面综合思量利用Logistic回归、决定树、随机丛林三种分类算法。简朴看一下这三种算法的功效:Logistic回归的功效:
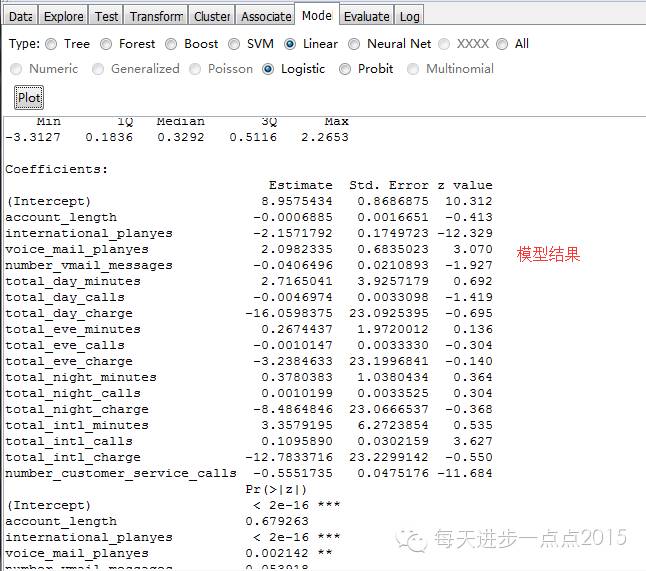
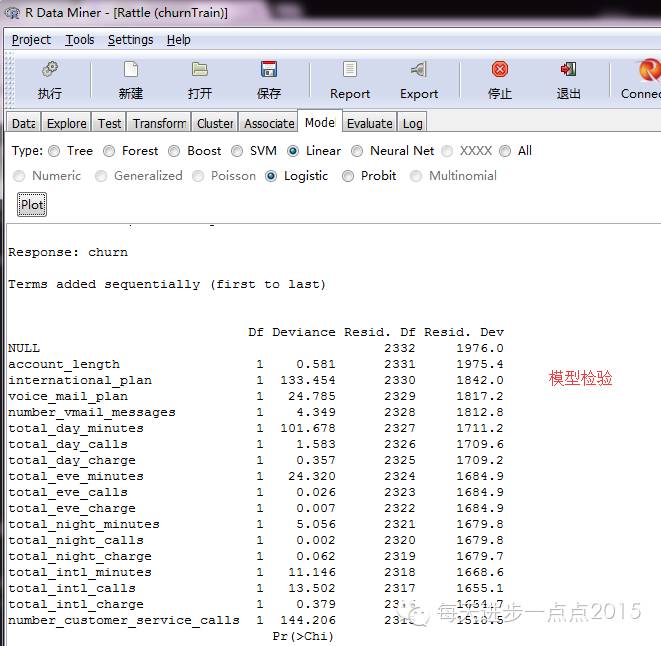
决定树的功效:
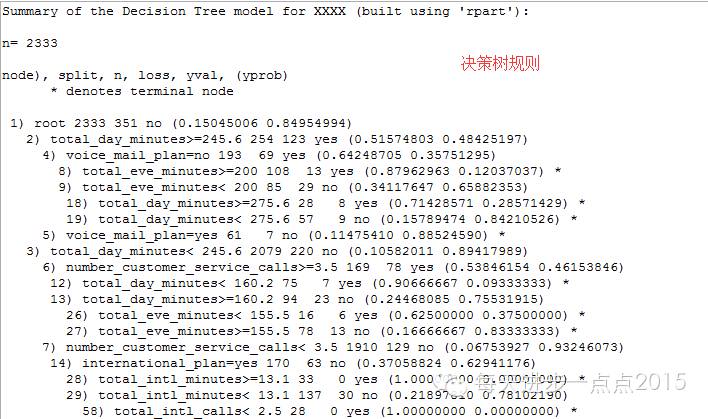

随机丛林的功效:
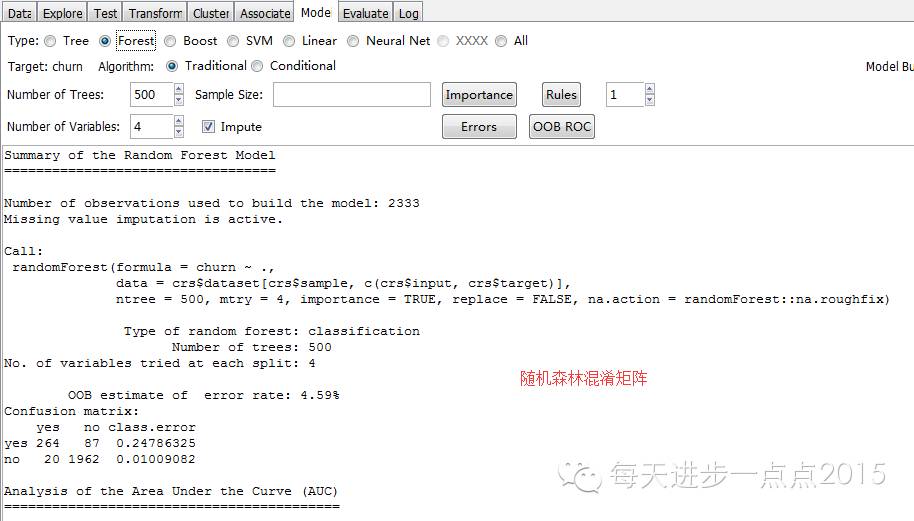

4)模子评估这里我们利用夹杂矩阵和ROC曲线两种评估模子的要领,详细功效见下图的展示:
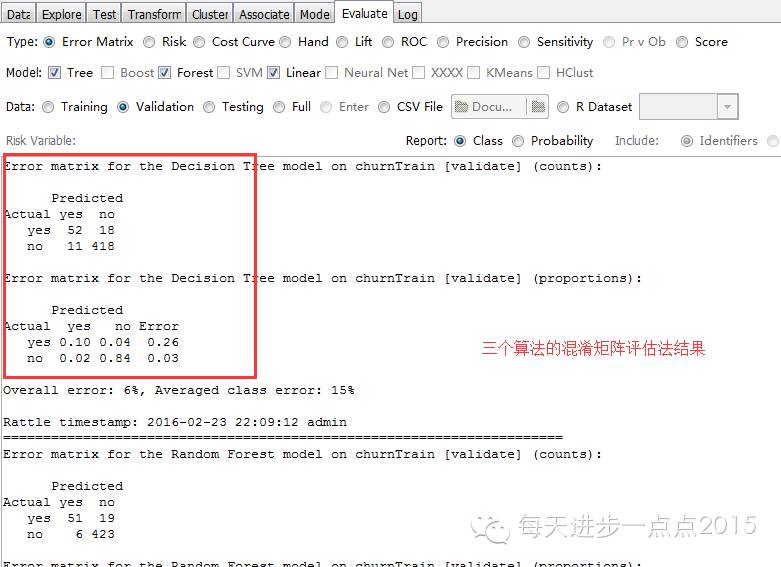
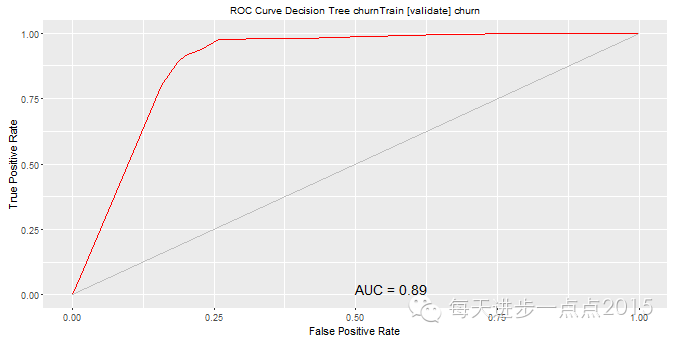
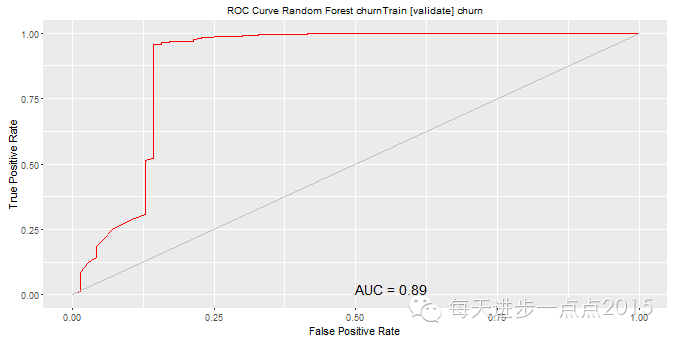
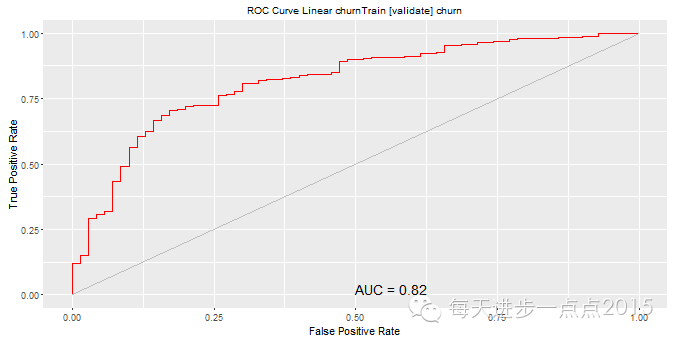
功效显示,三个模子的黑白顺序为:随机丛林、决定树和Logistic回归本文只是带各人进入rattle这个界面化操纵的数据阐明和挖掘东西,更多摸索和玩法还需要各人进一步研究。接待列位交换与探讨有关数据阐明的问题。
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
