Pig Hive先容
在本教程中,我们将接头 Pig & Hive
Pig简介
在Map Reduce框架,需要的措施将其转化为一系列 Map 和 Reduce阶段。 可是,这不是一种编程模子,它被数据阐明所熟悉。因此,为了补充这一差距,一个抽象观念叫 Pig 成立在 Hadoop 之上。
Pig是一种高级编程语言,阐明大数据集很是有用。 Pig 是雅虎尽力开拓的功效
Pig 使人们可以或许更专注于阐明大量数据集和花更少的时间来写map-reduce措施。
雷同猪吃对象,Pig 编程语言的目标是可以在任何范例的数据事情。

Pig 由两部门构成:
-
Pig Latin,这是一种语言
-
运行情况,用于运行PigLatin措施
Pig Latin 措施由一系列操纵或调动应用到输入数据,以发生输出。这些操纵描写被翻译成可执行到数据流,由 Pig 情况执行。下面,这些转换的功效是一系列的 MapReduce 功课,措施员是不知道的。所以,在某种水平上,Pig 答允措施员存眷数据,而不是执行进程。
Pig Latin 是一种相对硬挺的语言,它回收熟悉的要害字来处理惩罚数据,譬喻,Join, Group 和 Filter。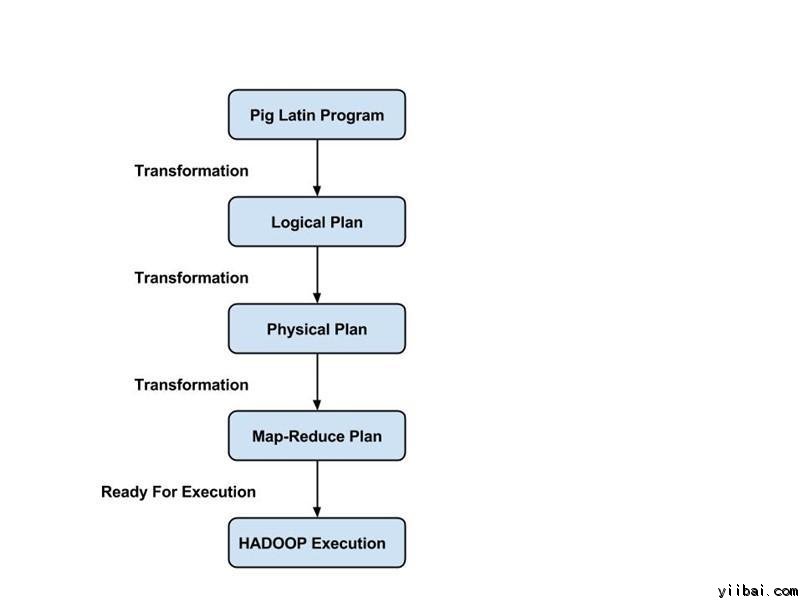

执行模式:
Pig 有两种执行模式:
-
本机模式:在此模式下,Pig 运行在单个JVM,并利用当地文件系统。这种模式只适合利用 Pig 小数据荟萃阐明。
-
Map Reduce模式:在此模式下,写在 Pig Latin 的查询被翻译成MapReduce 功课,并 Hadoop 集群上运行(集群大概是伪或完全漫衍式的)。 MapReduce 模式完全漫衍式集群对大型数据集运行 Pig 很有用的。
HIVE 先容
在某种水平上数据集收集的巨细并在行业用于贸易智能阐明正在增长,它使传统的数据客栈办理方案越发昂贵。HADOOP与MapReduce框架,被用于大型数据集阐明的替代办理方案。固然,Hadoop 地复杂的数据集上事情证明长短常有用的,MapReduce框架长短常初级别而且它需要措施员编写自界说措施,这导致难以维护和重用。 Hive 就是为措施员设计的。
Hive 演变为基于Hadoop的Map-Reduce 框架之上的数据客栈办理方案。
Hive 提供了雷同于SQL的声明性语言,叫作:HiveQL, 用于表达的查询。利用 Hive-SQL,用户可以或许很是容易地举办数据阐明。
Hive 引擎编译这些查询到 map-reduce功课中并在 Hadoop 上执行。另外,自界说 map-reduce 剧本,也可以插入查询。Hive运行存储在表中,它由根基数据范例,如数组和映射荟萃的数据范例的数据。
设置单位带有一个呼吁行shell接口,可用于建设表并执行查询。
Hive 查询语言是雷同于SQL,它支持子查询。通过Hive查询语言,可以利用 MapReduce 跨Hive 表毗连。它有雷同函数简朴的SQL支持- CONCAT, SUBSTR, ROUND 等等, 聚合函数 – SUM, COUNT, MAX etc。它还支持GROUP BY和SORT BY子句。 别的,也可以在设置单位查询语言编写用户界说的成果。
MapReduce,Pig 和 Hive 的较量
|
Sqoop |
Flume |
HDFS |
|
Sqoop用于从布局化数据源,譬喻,RDBMS导入数据 |
Flume 用于移动批量流数据到HDFS |
HDFS利用 Hadoop 生态系统存储数据的漫衍式文件系统 |
|
Sqoop具有毗连器的体系布局。毗连器知道如何毗连到相应的数据源并获取数据 |
Flume 有一个基于署理的架构。这里写入代码(这被称为“署理”),这需要处理惩罚取出数据 |
HDFS具有漫衍式体系布局,数据被漫衍在多个数据节点 |
|
HDFS 利用 Sqoop 将数据导出到目标地 |
通过零个或更多个通道将数据流给HDFS |
HDFS是用于将数据存储到最终目标地 |
|
Sqoop数据负载不事件驱动 |
Flume 数据负载可通过事件驱动 |
HDFS存储通过任何方法提供应它的数据 |
|
为了从布局化数据源导入数据,人们必需只利用Sqoop,因为它的毗连器知道如何与布局化数据源举办交互并从中获取数据 |
为了加载流数据,如微博发生的推文。可能登录Web处事器的文件,Flume 应都可以利用。Flume 署理是专门为获取流数据而成立的。 |
HDFS拥有本身的内置shell呼吁将数据存储。HDFS不能用于导入布局化或流数据 |
