Hadoop HDFS入门
Hadoop 附带了一个名为 HDFS(Hadoop漫衍式文件系统)的漫衍式文件系统,基于 Hadoop 的应用措施利用 HDFS 。HDFS 是专为存储超大数据文件,运行在集群的商品硬件上。它是容错的,可伸缩的,而且很是易于扩展。
你知道吗? 当数据高出一个单个物理呆板上存储的容量,除以跨独立呆板数。打点超过呆板的网络存储特定操纵被称为漫衍式文件系统。
HDFS集群主要由 NameNode 打点文件系统 Metadata 和 DataNodes 存储的实际数据。
NameNode: NameNode可以被认为是系统的主站。它维护所有系统中存在的文件和目次的文件系统树和元数据 。 两个文件:“定名空间映像“和”编辑日志“是用来存储元数据信息。Namenode 有所有包括数据块为一个给定的文件中的数据节点的常识,可是不存储块的位置一连。从数据节点在系统每次启动时信息重构一次。
DataNode : DataNodes作为从机,每台呆板位于一个集群中,并提供实际的存储. 它认真为客户读写请求处事。
HDFS中的读/写操纵运行在块级。HDFS数据文件被分成块巨细的块,这是作为独立的单位存储。默认块巨细为64 MB。
HDFS操纵上是数据复制的观念,个中在数据块的多个副本被建设,漫衍在整个节点的群集以使在节点妨碍的环境下数据的高可用性。
注: 在HDFS的文件,比单个块小,不占用块的全部存储。
在HDFS读操纵
数据读取请求将由 HDFS,NameNode和DataNode来处事。让我们把读取器叫 “客户”。下图描画了文件的读取操纵在 Hadoop 中。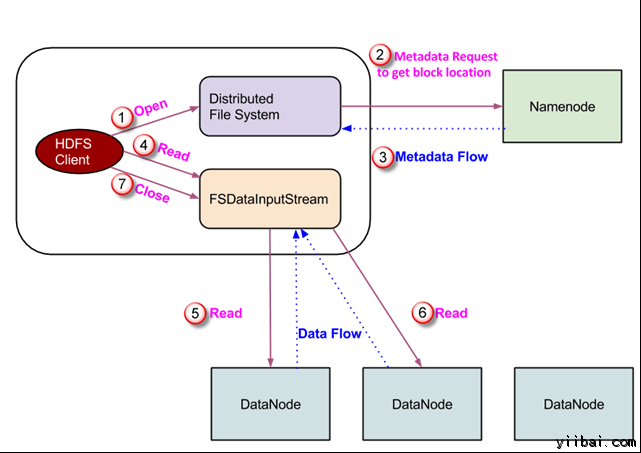
- 客户端启动通过挪用文件系统工具的 open() 要领读取请求; 它是 DistributedFileSystem 范例的工具。
- 此工具利用 RPC 毗连到 namenode 并获取的元数据信息,如该文件的块的位置。 请留意,这些地点是文件的前几个块。
- 响应该元数据请求,具有该块副本的 DataNodes 地点被返回。
-
一旦吸收到 DataNodes 的地点,FSDataInputStream 范例的一个工具被返回到客户端。 FSDataInputStream 包括 DFSInputStream 这需要处理惩罚交互 DataNode 和 NameNode。在上图所示的步调4,客户端挪用 read() 要领,这将导致 DFSInputStream 成立与第一个 DataNode 文件的第一个块毗连。
-
以数据流的形式读取数据,个中客户端多次挪用 “read() ” 要领。 read() 操纵这个进程一直一连,直到它达到块竣事位置。
- 一旦到模块的末了,DFSInputStream 封锁毗连,移动定位到下一个 DataNode 的下一个块
- 一旦客户端已读取完成后,它会挪用 close()要领。
HDFS写操纵
在本节中,我们将相识如何通过的文件将数据写入到 HDFS。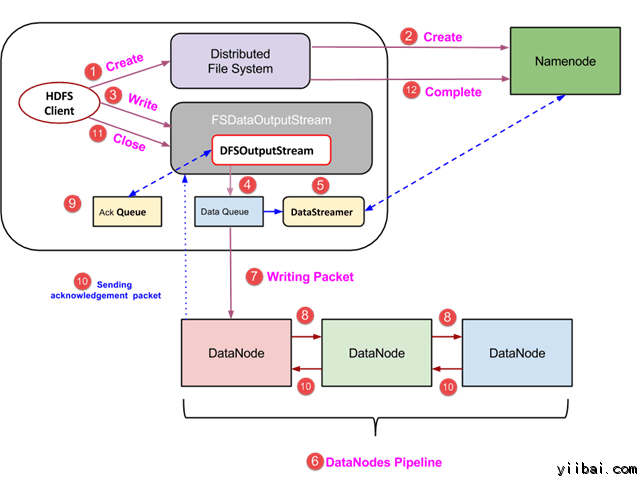
- 客户端通过挪用 DistributedFileSystem工具的 create() 要领建设一个新的文件,并开始写操纵 – 在上面的图中的步调1
- DistributedFileSystem工具利用 RPC 挪用毗连到 NameNode,并启动新的文件建设。可是,此文件建设操纵不与文件任何块相关联。NameNode 的责任是验证文件(其正被建设的)不存在,而且客户端具有正确权限来建设新文件。假如文件已经存在,可能客户端不具有足够的权限来建设一个新的文件,则抛出 IOException 到客户端。不然操纵乐成,而且该文件新的记录是由 NameNode 建设。
- 一旦 NameNode 建设一条新的记录,返回FSDataOutputStream 范例的一个工具到客户端。客户端利用它来写入数据到 HDFS。数据写入要领被挪用(图中的步调3)。
- FSDataOutputStream包括DFSOutputStream工具,它利用 DataNodes 和 NameNode 通信后查找。当客户机继承写入数据,DFSOutputStream 继承建设这个数据包。这些数据包毗连列队到一个行列被称为 DataQueue
- 尚有一个名为 DataStreamer 组件,用于耗损DataQueue。DataStreamer 也要求 NameNode 分派新的块,拣选 DataNodes 用于复制。
- 此刻,复制进程始于利用 DataNodes 建设一个管道。 在我们的例子中,选择了复制程度3,因此有 3 个 DataNodes 管道。
- 所述 DataStreamer 注入包分成到第一个 DataNode 的管道中。
- 在每个 DataNode 的管道中存储数据包吸收并同样转发在第二个 DataNode 的管道中。
- 另一个行列,“Ack Queue”是由 DFSOutputStream 保持存储,它们是 DataNodes 期待确认的数据包。
- 一旦确认在行列中的分组从所有 DataNodes 已吸收在管道,它从 'Ack Queue' 删除。在任何 DataNode 产生妨碍时,从行列中的包从头用于操纵。
- 在客户端的数据写入完成后,它会挪用close()要领(第9步图中),挪用close()功效进入到清理缓存剩余数据包到管道之后期待确认。
- 一旦收到最终确认,NameNode 毗连汇报它该文件的写操纵完成。
利用JAVA API会见HDFS
在本节中,我们来相识 Java 接口并用它们来会见Hadoop的文件系统。
#p#分页标题#e#
为了利用编程方法与 Hadoop 文件系统举办交互,Hadoop 提供多种 Java 类。org.apache.hadoop.fs 包中包括哄骗 Hadoop 文件系统中的文件类东西。这些操纵包罗,打开,读取,写入,和封锁。实际上,对付 Hadoop 文件 API 是通用的,可以扩展到 HDFS 的其他文件系统交互。
编程从 HDFS 读取文件
java.net.URL 工具是用于读取文件的内容。首先,我们需要让 Java 识别 Hadoop 的 HDFS URL架构。这是通过挪用 URL 工具的 setURLStreamHandlerFactory要领和 FsUrlStreamHandlerFactory 的一个实例琮通报给它。此要领只需要执行一次在每个JVM,因此,它被关闭在一个静态块中。
示例代码
|
publicclassURLCat { static{ URL.setURLStreamHandlerFactory(newFsUrlStreamHandlerFactory()); } publicstaticvoidmain(String[] args) throwsException { InputStream in = null; try{ in = newURL(args[0]).openStream(); IOUtils.copyBytes(in, System.out, 4096, false); } finally{ IOUtils.closeStream(in); } } } |
这段代码用于打开和读取文件的内容。HDFS文件的路径作为呼吁行参数通报给该措施。
利用呼吁行界面会见HDFS
这是与 HDFS 交互的最简朴的要领之一。 呼吁行接口支持对文件系统操纵,譬喻:如读取文件,建设目次,移动文件,删除数据,并列出目次。
可以执行 '$HADOOP_HOME/bin/hdfs dfs -help' 来得到每一个呼吁的具体辅佐。这里, 'dfs' HDFS是一个shell呼吁,它支持多个子呼吁。首先要启动 Haddop 处事(利用 hduser_用户),执行呼吁如下:
[email protected]:~$ su hduser_ [email protected]:~$ $HADOOP_HOME/sbin/start-dfs.sh [email protected]:~$ $HADOOP_HOME/sbin/start-yarn.sh
一些遍及利用的呼吁的列表如下
1. 从当地文件系统复制文件到 HDFS
[email protected]:~$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal temp.txt /
此呼吁将文件从当地文件系统拷贝 temp.txt 文件到 HDFS。
2. 我们可以通过以下呼吁列出一个目次下存在的文件 -ls
[email protected]:~$ $HADOOP_HOME/bin/hdfs dfs -ls /


我们可以看到一个文件 'temp.txt“(之前复制)被列在”/“目次。
#p#分页标题#e#
3. 以下呼吁将文件从 HDFS 拷贝到当地文件系统
[email protected]:~$ $HADOOP_HOME/bin/hdfs dfs -copyToLocal /temp.txt
我们可以看到 temp.txt 已经复制到当地文件系统。
4. 以下呼吁用来建设新的目次
[email protected]:~$ $HADOOP_HOME/bin/hdfs dfs -mkdir /mydirectory
 接下来查抄是否已经成立了目次。此刻,应该知道怎么做了吧?
接下来查抄是否已经成立了目次。此刻,应该知道怎么做了吧?
