Pentium III处理惩罚器的单指令大都据流扩展指令(2)
副标题#e#
要害字 :
Pentium,处理惩罚器,单指令大都据流扩展指令,SSE,指令集
提要 :
跟着Intel Pentium III处理惩罚器的宣布,给措施设计人员又带来了很多新的特性。操作这些新特性,措施员可觉得用户缔造出更好的产物. Pentium III和Pentium III Xeon(至强处理惩罚器)的很多新特性,可以使她可以或许比Pentium II和Pentium II Xeon处理惩罚器有更快的运行速度,这些新特性包罗一个处理惩罚器序列号(unique processor ID)和新增SSE处理惩罚器指令集,这些新的指令集就像Pentium II在经典Pentium的基本上添加的MMX指令集.
1. 利用SSE
在详细描写了SSE指令集今后,让我们看看奈何才气在应用措施中利用他们呢.
1.1 汇编语言
传统地,措施员但愿可以或许利用汇编语言来操作新处理惩罚器的新特性.凡是这是必需的,因为高级的措施开拓东西只有在处理惩罚器正式推出今后的某个适当的时间才会由新版本宣布支持. Pentium III的环境也是这样.此刻,只有Intel的C/C++编译器和Microsoft Macro Assembler(6.11d及以上版本)才认识新的SSE指令集.
这里有一个抵牾的处所:假如用纯汇编语言来写一个大型的、巨大的应用措施长短常坚苦的,可是这样写出来的代码执行速度又是最快的.
我们也可以利用SSE SDK(Software Developers Kit,软件开拓东西包)开拓包,Intel在开拓包中提供了两种编程机制去利用SSE指令集:一个intrinsics库和一个暗示SSE界说的新数据范例的C++类.利用这些机制比纯真用汇编语言简朴.这是很明明的,因为这样措施员再也不消由本身去打点SSE的寄存器了,可以很利便的建设出大型的应用措施.可是这种机制写出的代码又比用汇编语言写的代码执行速度慢了.图6说明白这三种开拓要领在措施执行速度和开拓坚苦水平之间的抵牾.

图六: 在差异开拓情况下的措施执行速度和开拓坚苦水平之间的抵牾
#p#副标题#e#
1.1.1 示例:乘法
假设有两个128位的数a和b别离存储在寄存器xmm1和xmm2中,他们的计较功效生存在寄存器xmm0中.用C语言嵌入汇编的代码如下:
#include
...
_asm {
push esi;
push edi;
; a is loaded into xmm1
; b is loaded into xmm2
mov xmm0, xmm1;
mulps xmm0, xmm2;
; store result into c
pop edi;
pop esi;
}
...
图7用图表来暗示了这种包裹乘法(packed multiplication)的计较
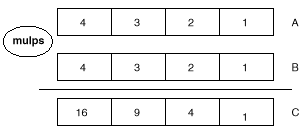
图七:包裹乘法计较
1.2 Intrinsics库
利用Intrinsics库是第一种附加的编程机制.Intrinsics库为C语言提供了一个利用SSE指令集的接口.所有的SSE指令在这个库中都被包装成了C函数.两个包裹数据(packed data)相加的汇编指令是addps.相应的,在intrinsics库中将两个包裹数据相加的对应函数是_mm_add_ps.为了共同这些新增的函数,intrinsics库还界说了一个新的数据范例(__m128)来暗示128位长的数据,可以用来生存4个单精度浮点数.
要利用intrinsics库,还需要在措施中包括(include)xmmintrin.h头文件.
1.2.1 示例:乘法
假设有两个128位数a和b,他们的计较功效将被生存在另一个128位数c中.a,b和c都是__m128数据.__m128是128位数据范例,已经在头文件xmmintrin.h中界说了.函数_mm_set_ps成果是把他的4个参数凭据第一个参数为最高位、最后一个参数为最低位的顺序分列组合成一个128数.
#include
...
__m128 a, b, c;
a = _mm_set_ps(4, 3, 2, 1)
b = _mm_set_ps(4, 3, 2, 1)
c = _mm_set_ps(0, 0, 0, 0)
c = _mm_mul_ps(a, b);
...
1.3 C++
第二种附加的编程机制是利用C++语言.SSE SDK开拓包提供了一个C++类:F32vec4,用来处理惩罚和暗示一个128位的新数据范例.所有的新数据范例的操纵都被封装在这个类中了.在类的内部,他也是利用intrinsics库的.
要利用这个C++类,,还必需在措施中包括(include)fvec.h头文件.
1.3.1 示例:乘法
我们再次假设有两个128位的数a和b,他们的计较功效放在另一个128位数c中.所有的数据都界说成F32vec4类.类的结构函数成果就相当于_mm_set_ps函数.
#include ...
F32vec4 a(4, 3, 2, 1), b(4, 3, 2, 1), c(0, 0, 0, 0);
...
c =a * b;
...
1.4 编译器支持
前面已经说过,只有Intel的C\C++编译器和Microsoft的Macro Assembler支持新的SSE指令集.Intel编译器已经整合到Microsoft的Visual Studio集成开拓情况中了.Visual Studio集成开拓情况可以被设置成利用Intel的编译器来编译整个工程可能工程中的某个文件.
2. SSE指令具体资料
在我们先容SSE指令用法的例子以前,让我们先来看看SSE指令集的所有指令列表.
Arithmetic Instructions(算术指令)
addps, addss
subps, subss
mulps, mulss
divps, divss
sqrtps, sqrtss
maxps, maxss
minps, minss
Logical Instructions(逻辑指令)
andps
andnps
orps
xorps
Compare Instructions(较量指令)
cmpps, cmpss
comiss
ucomiss
Shuffle Instructions(清洗指令)
shufps
unpchkps
unpcklps
Conversion Instructions(转换指令)
cvtpi2ps, cvtpi2ss
cvtps2pi, cvtss2si
Data Movement Instructions(数据移动指令)
movaps
movups
movhps
movlps
movmskps
movss
State Management Instructions(状态打点指令)
ldmxcsr
fxsave
stmxscr
fxstor
Cacheability Control Instructions(cache节制指令)
maskmovq
movntq
movntps
prefetch
sfence
Additional SIMD Integer Instructions(附加的SIMD整数指令)
pextrw
pinsrw
pmaxub, pmaxsw
pminub, pminsw
pmovmskb
pmulhuw
pshufw
3. 例子
#p#分页标题#e#
在这一节,我们将先容几个例子来帮你领略Pentium III的SSE指令集应用.在每个例子中,我们都将先容三种办理方案,别离利用汇编语言、intrinsics库和C++类.附加例子将在下一部门的附加示例节中先容.
3.1 包裹乘法
在前面我们已经用三种差异的开拓机制先容了两个包裹数据的乘法计较,这三种机制别离是利用汇编语言、intrinsics库和C++类来编写.
3.2 较量操纵
让我们来思量一下较量的事件.假如不利用SSE,我们每次只能对一对浮点数举办较量.利用了SSE今后,可以同时对4对浮点数举办较量.
在C和C++中较量4对浮点数,我们可以像下面一样写一个轮回,把每次的较量放在轮回内里.别的我们还需要界说生存较量功效的变量.代码可以雷同于下面的例子.
float a[4], b[4]
int i, c[4];
// assume that a contains 4.5 6.7 2.3 and 1.2
// assume that b contains 4.3 6.9 2.0 and 1.5
for (i = 0;i < 4; i++ )
c[i] = a[i] < b[i];
// take action on comparison result
在SSE指令会合,较量指令是cmpps,她有两个128位的操纵数和一个选项参数.选项参数是用来指明指令较量范例的:是大于、小于、大于便是照旧小于便是的较量.cmpps指令用来较量4对浮点数的巨细,并将较量功效放在第一个操纵数中.假如较量的功效是真,相对应的元素将被置为FFFFFFFF,假如为非,则被置为00000000.这个功效还可以被映射到一个普通的(8位可能16位)寄存器中,这个普通的寄存器用一个位来映射SSE寄存器的一个元素.我们可以从这个映射的寄存器来获得较量的功效.
下面举例来说明cmpps指令的用法.
; assume that xmm0 contains 4.5 6.7 2.3 and 1.2
; assume that xmm1 contains 4.3 6.9 2.0 and 1.5
; compare for less than condition
cmpps xmm0, xmm1, 1;
; move result of comparison as a mask into eax
movmskps eax, xmm0;
; test eax against some value
test eax, 5;
; jump if true, to the given label
je match13
这个操纵也可以用图8的图示来暗示.
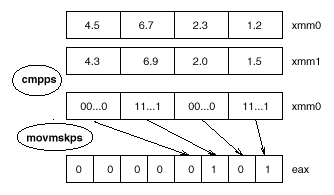
图八 :较量运算
3.3 分支移除
凡是,在措施中我们喜欢用下面的条件语句.
a =(a < b) ? c :d;
在上面的代码中,较量操纵影响着后头代码的执行路径.假如我们可以或许移除条件判定,措施将能执行的更快.下面的这段汇编代码将比上面的代码执行得更快,这不只仅是因为下面的代码是用汇编语言写的,更重要的是这里的分支判定已经被移除了.
; assume that xmm0 stores a, xmm1 stores b
; assume that xmm3 stores c and xmm4 stores d
cmpps xmm0, xmm1, 1;
movaps xmm2, xmm0;
andps xmm0, xmm3;
andnps xmm2, xmm4;
orps xmm0, xmm2;
; xmm0 contains the result, which is either c or d
