漫衍式基本进修【一】 —— 漫衍式文件系统
副标题#e#
漫衍式基本进修
所谓漫衍式,在这里,很狭义的指代以Google的三驾马车,GFS、Map/Reduce、BigTable 为框架焦点的漫衍式存储和计较系统。凡是如我一样初学的人,会以Google这几份经典的论 文作为初步的。它们勾勒出了漫衍式存储和计较的一个根基蓝图,已可窥见其几分风姿,但 终究照旧由于缺少一些实现的代码和示例,色彩有些斑驳,缺少了点感性。幸好我们尚有 Open Source,尚有Hadoop。Hadoop是一个基于Java实现的,开源的,漫衍式存储和计较的项 目。作为这个规模最富盛名的开源项目之一,它的利用者也是大牌如云,包罗了Yahoo, Amazon,Facebook等等(好吧,还大概有校内,不外这真的没啥分量…)。Hadoop自己,实 现的是漫衍式的文件系统HDFS,和漫衍式的计较(Map/Reduce)框架,另外,它还不是一个 人在战斗,Hadoop包括一系列扩展项目,包罗了漫衍式文件数据库HBase(对应Google的 BigTable),漫衍式协同处事ZooKeeper(对应Google的Chubby),等等。。。
如此,一个看上去不错的黄金搭档浮出水面,Google的论文 + Hadoop的实现,顺着论文 的框架看详细的实现,用实现来进一步领略论文的逻辑,看上去至少很美。网上有许多前辈 们,做过Hadoop相关的源码分解事情,我存眷最多的是这里,今朝博主已经完成了HDFS的剖 析事情,Map/Reduce的分解正火热举办中,更新频率之高,分解之详尽,都是可贵一见的, 所以,走过途经必然不要错过了。另外,尚有许多Hadoop的存眷者和利用者贴过相关的文章 ,好比:这里,这里。也可以去Hadoop的中文站点(不知是民间照旧官方…),搜罗一些学 习资料。。。
我小我私家从上述资料中受益匪浅,而我本身要做的整理,与原始的源码分解有些差异,不是 依照实现的模块,而是基于论文的脉络和实现这样系统的根基脉络来举办的,也算,从另一 个角度给出一些对象吧。鉴于小我私家对付漫衍式系统的领略很是的浅薄,缺少足够的实践履历 ,深入的问题就不班门弄斧了,仅做梳理息争析,大牛至此,可绕路而行了。。。
一. 漫衍式文件系统
漫衍式文件系统,在整个漫衍式系统体系中处于最低层最基本的职位,存储嘛,没了数据 ,再好的计较平台,再完善的数据库系统,都成了无水之舟了。那么,什么是漫衍式文件系 统,顾名思义,就是漫衍式+文件系统。它包括这两个方面的内在,从文件系统的客户利用的 角度来看,它就是一个尺度的文件系统,提供了一系列API,由此举办文件或目次的建设、移 动、删除,以及对文件的读写等操纵。从内部实现来看,漫衍式的系统则不再和普通文件系 统一样认真打点当地磁盘,它的文件内容和目次布局都不是存储在当地磁盘上,而是通过网 络传输到远端系统上。而且,同一个文件存储不可是在一台呆板上,而是在一簇呆板上漫衍 式存储,协同提供处事,正所谓漫衍式。。。
因此,考量一个漫衍式文件系统的实现,其实不妨可以从这两方面来别离分解,尔后合二 为一。首先,看它如何去实现文件系统所需的根基增删改查的成果。然后,看它如何思量分 布式系统的特点,提供更好的容错性,负载均衡,等等之类的。这二者合二为一,就大白了 一个漫衍式文件系统,整体的实现模式。。。
#p#副标题#e#
I. 术语比较
说任何对象,都需要统一一下语言先,否则显着说的一个意思,却容易被领略到另一个地 方去。Hadoop的漫衍式文件系统HDFS,根基是凭据Google论文中的GFS的架构来实现的。可是 ,HDFS为了彰显其不走寻常路的天性,个中的大量术语,都与GFS截然差异。显着都是一个枝 上长的土豆,它偏偏就要叫山药蛋,弄得水火不容的,苦了我们看客。承袭老大好人,谁也不 冒犯的目的,文中,既不回收GFS的叫法,也不回收Hadoop的称呼,而是另辟门路,自立派别 ,搞一套本身的中文翻译,为了制止不须要的痛楚,特此先来一帖术语比较表,要不懂查一 查,包治百病。。。
| 文中所用翻译 | HDFS中的术语 | GFS中的术语 | 术语表明 |
| 主控处事器 | NameNode | Master | 整个文件系统的大脑,它提供整个文件系统的目次信息,并 且打点各个数据处事器。 |
| 数据处事器 | DataNode | Chunk Server | 漫衍式文件系统中的每一个文件,都被切分成若干个数据块 ,每一个数据块都被存储在差异的处事器上,此处事器称之为数据处事器。 |
| 数据块 | Block | Chunk | 每个文件城市被切分成若干个块,每一块都有持续的一段文 件内容,是存储的基恩单元,在这里统一称做数据块。 |
| 数据包 | Packet | 无 | 客户端写文件的时候,不是一个字节一个字节写入文件系统 的,而是累计到必然数量后,往文件系统中写入一次,每发送一次的数据,都称为一个数据 包。 |
| 传输块 | Chunk | 无 | 在每一个数据包中,城市将数据切成更小的块,每一个块配 上一个奇偶校验码,这样的块,就是传输块。 |
| 备份主控处事器 | SecondaryNameNode | 无 | 备用的主控处事器,在身后冷静的拉取着主控处事器 的日志 ,期待主控处事器牺牲后被扶正。 |
*注:本文回收的Hadoop是0.19.0版本。
II. 根基架构
1. 处事器先容
#p#分页标题#e#
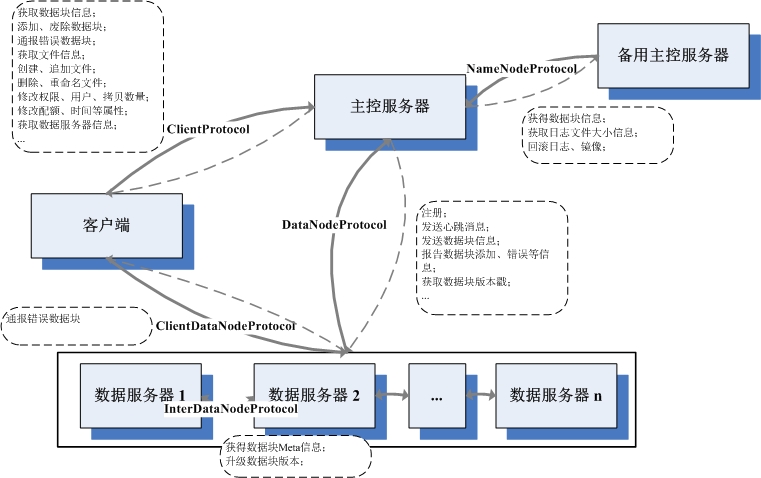
与单机的文件系统差异,漫衍式文件系统不是将这些数据放在一块磁盘上,由上层操纵系 统来打点。而是存放在一个处事器集群上,由集群中的处事器,各尽其责,共同尽力,提供 整个文件系统的处事。个中重要的处事器包罗:主控处事器(Master/NameNode),数据处事 器(ChunkServer/DataNode),和客户处事器。HDFS和GFS都是凭据这个架构模式搭建的。个 人以为,个中设计的最焦点内容是:文件的目次布局独立存储在一个主控处事器上,而详细 文件数据,拆分成若干块,冗余的存放在差异的数据处事器上。
存储目次布局的主控处事器,在GFS中称为Master,在HDFS中称为NameNode。这两个名字 ,叫得都有各自的来由,是瞎子摸象各表一面。Master是之于数据处事器来叫的,它做为数 据处事器的率领同志存在,打点各个数据处事器,收集它们的信息,相识所有数据处事器的 保留近况,然后给它们分派任务,批示它们齐心合力为系统处事;而NameNode是针对客户端 来叫的,对付客户端而言,主控处事器上放着所有的文件目次信息,要找一个文件,必需问 问它,由此而的此名。。。
主控处事器在整个集群中,同时提供处事的只存在一个,假如它不幸牺牲的话,会有后备 军立即前赴后继的跟上,但,同一时刻,需要保持一山不容二虎的态势。这种设计计策,避 免了多台处事器间即时同步数据的价钱,而同时,它也使得主控处事器很大概成为整个架构 的瓶颈地址。因此,只管为主控处事器减负,否则它做太多的工作,就自然而然的提升成了 一个漫衍式文件系统的设计要求。。。
每一个文件的详细数据,被切分成若干个数据块,冗余的存放在数据处事器。凡是的设置 ,每一个数据块的巨细为64M,在三个数据处事器上冗余存放(这个64M,不是随便得来的, 而是颠末重复实践获得的。因为假如太大,容易造成热点的堆叠,大量的操纵会合在一台数 据处事器上,而假如太小的话,附加的节制信息传输本钱,又太高了。因此没有较量特定的 业务需求,可以思量维持此设置…)。数据处事器是典范的四肢发家脑子简朴的夫役,其主 要的事情模式就是按期向主控处事器讲述其状况,然后期待并处理惩罚呼吁,更快更安详的存放 好数据。。。
另外,整个漫衍式文件系统尚有一个重要脚色是客户端。它反面主控处事和数据处事一样 ,在一个独立的历程中提供处事,它只是以一个类库(包)的模式存在,为用户提供了文件 读写、目次操纵等APIs。当用户需要利用漫衍式文件系统举办文件读写的时候,把客户端相 关包给设置上,就可以通过它来享受漫衍式文件系统提供的处事了。。。
2. 数据漫衍
一个文件系统中,最重要的数据,其实就是整个文件系统的目次布局和详细每个文件的数 据。详细的文件数据被切分成数据块,存放在数据处事器上。每一个文件数据块,在数据服 务器上都表征为出双入队的一对文件(这是普通的Linux文件),一个是数据文件,一个是附 加信息的元文件,在这里,不妨把这对文件简称为数据块文件。数据块文件存放在数据目次 下,它有一个名为current的根目次,然后内里有若干个数据块文件和从dir0-dir63的最多64 个的子目次,子目次内部布局等同于current目次,依次类推(更具体的描写,拜见这里)。 小我私家以为,这样的架构,有利于节制同一目次下文件的数量,加速检索速度。。。
#p#分页标题#e#
这是磁盘上的物理布局,与之对应的,是内存中的数据布局,用以表征这样的磁盘布局, 利便读写操纵的举办。Block类用于暗示数据块,而FSDataset类是数据处事器打点文件块的 数据布局,个中,FSDataset.FSDir对应着数据块文件和目次,FSDataset.FSVolume对应着一 个数据目次,FSDataset.FSVolumeSet是FSVolume的荟萃,每一个FSDataset有一个 FSVolumeSet。多个数据目次,可以放在差异的磁盘上,这样有利于加速磁盘操纵的速度。相 关的类图,可以参看这里 。。。
另外,与FSVolume对应的,尚有一个数据布局,就是DataStorage,它是Storage的子类, 提供了进级、回滚等支持。但与FSVolume纷歧样,它不需要相识数据块文件的详细内容,它 只知道有这么一堆文件放这里,会有差异版本的进级需求,它会处理惩罚怎么把它们进级回滚之 类的业务(关于Storage,可以拜见这里)。而FSVolume提供的接口,都根基上是和Block相 关的。。。
对比数据处事器,主控处事器的数据量不大,但逻辑更为巨大。主控处事器主要有三类数 据:文件系统的目次布局数据,各个文件的分块信息,数据块的位置信息(就数据块安排在 哪些数据处事器上…)。在GFS和HDFS的架构中,只有文件的目次布局和分块信息才会被持 久化到当地磁盘上,而数据块的位置信息则是通过动态汇总过来的,仅仅存活在内存数据结 构中,呆板挂了,就灰飞烟灭了。每一个数据处事器启动后,城市向主控处事器发送注册消 息,将其上数据块的状况都奉告于主控处事器。俗话说,简朴就是美,按照DRY原则,生存的 冗余信息越少,呈现纷歧致的大概性越低,支付一点点时间的价钱,调换了一大把逻辑上的 简朴性,绝对应该是一个包赚不赔的交易。。。
在HDFS中,FSNamespacesystem类就认真保管文件系统的目次布局以及每个文件的分块状 况的,个中,前者是由FSDirectory类来认真,后者是各个INodeFile自己维护。在INodeFile 内里,有一个BlockInfo的数组,生存着与该文件相关的所有数据块信息,BlockInfo中包括 了从数据块到数据处事器的映射,INodeFile只需要知道一个偏移量,就可以提供相关的数据 块,和数据块存放的数据处事器信息。。。
3、处事器间协议
在Hadoop的实现中,陈设了一套RPC机制,以此来实现各处事间的通信协议。在Hadoop中 ,每一对处事器间的通信协议,都界说成为一个接口。处事端的类实现该接口,而且成立RPC 处事,监听相关的接口,在独立的线程处理惩罚RPC请求。客户端则可以实例化一个该接口的署理 工具,挪用该接口的相应要领,执行一次同步的通信,传入相应参数,吸收相应的返回值。 基于此RPC的通信模式,是一个动静拉取的流程,RPC处事器期待RPC客户端的挪用,而不会先 发制人主动把相关信息推送到RPC客户端去。。。
其实RPC的模式和道理,实在是没啥好说的,之所以说,是因为可以通过掌握好这个,彻 底理顺Hadoop各处事器间的通信模式。Hadoop会界说一些列的RPC接口,只需要看谁实现,谁 挪用,就可以知道谁和谁通信,都做些啥工作,图中处事器的根基架构、各处事所利用的协 议、挪用偏向、以及协议中的根基内容。。。
III. 根基的文件操纵
根基的文件操纵,可以分成两类,一个是对文件目次布局的操纵,好比文件和目次的建设 、删除、移动、改名等等;另一个是对文件数据流的操纵,包罗读取和写入文件数据。虽然 ,文件读和写,是有本质区此外,尤其是在数据冗余的环境下,因此,当成两类操纵也不敷 为过。另外,要详细到读写的种别,也是可以再继承分类下去的。在GFS的论文中,对付漫衍 式文件系统的读写场景有一个重要的假定(其实是从实际业务角度得来的…):就是文件的 读取是由大数据量的持续读取和小数据量的随机读取构成,文件的写入则根基上都是批量的 追加写,和偶然的插入写(GFS中尚有大量的假设,它们组成了漫衍式文件系统架构设计的基 石。每一个系统架构都是搭建在必然假设上的,这些假设有些来自于实际业务的状况,有些 是因为天生的条件约束,不基于假设领略设计,必定会有失偏颇…)。在GFS中,对文件的 写入分成追加写和插入写都有所支持,可是,在HDFS中仅仅支持追加写,这大大低落了巨大 性。关于HDFS与GFS的一些差异,可以参看这里。。。
1. 文件和目次的操纵
#p#分页标题#e#
文件目次的信息,全部囤积在主控处事器上,因此,所有对文件目次的操纵,只会直接涉 及到客户端和主控处事器。整个目次相关的操纵流程根基都是这样的:客户端DFSClient挪用 ClientProtocol界说的相关函数,该操纵通过RPC传送到其实现者主控处事器NameNode哪里, NameNode做相关的处理惩罚后(很少…),挪用FSNamesystem的相关函数。在FSNamesystem中, 往往是做一些验证和租约操纵,详细的目次布局操纵交由FSDirectory的相应函数来操纵。最 后,依次返回,经过RPC传送回客户端。详细各操纵涉及到的函数和详细步调,拜见下表:
| 相关操纵 | ClientProtocol / NameNode | FSNamesystem | FSDirectory | 要害步调 |
| 建设文件 | create | startFile | addFile | 1. 查抄是否有写权限;
2. 查抄是否已经存在此文件,假如是覆写,则先举办删除操纵; 3. 在指定路径下添加INodeFileUnderConstruction的文件实例; 4. 写日志; 5. 签订租约。 |
| 建设目次 | mkdirs | mkdirs | mkdirs | 1. 查抄指定目次是否是目次;
2. 查抄是否有相关权限; 3. 在指定路径的INode下,添加子节点; 4. 写日志。 |
| 更名操纵 | rename | renameTo | renameTo | 1. 查抄相关路径的权限;
2. 从老路径下移除,在新路径下添加; 3. 修改相关父路径的修改时间; 4. 写日志; 5. 将租约从老路径移动到新路径下。 |
| 删除操纵 | delete | delete | delete | 1. 假如不是递归删除,确认指定路径是否是空目次;
2. 查抄相关权限; 3. 在目次布局上移除相关INode; 4. 修改父路径的修改时间; 5. 将相关的数据块,放入到废弃行列中去,期待处理惩罚; 6. 写日志; 7. 废弃相关路径的租约。 |
| 配置权限 | setPermission | setPermission | setPermission | 1. 查抄owner判定是否有操纵权限;
2. 修改指定路径下INode的权限; 3. 写日志。 |
| 配置用户 | setOwner | setOwner | setOwner | 1. 查抄是否有操纵权限;
2. 修改指定路径下INode的权限; 3. 写日志。 |
| 配置时间 | setTimes | setTimes | setTimes | 1. 查抄是否有写权限;
2. 修改指定路径INode的时间信息; 3. 写日志。 |
从上表可以看到,其实有的操纵本质上照旧涉及到了数据处事器,好比文件建设和删除操 作。可是,之前提到,主控处事器只于数据处事器是一个期待拉取的职位,它们不会主动联 系数据处事器,将指令传输给它们,而是放到相应的数据布局中,期待数据处事器来取。这 样的设计,可以淘汰通信的次数,加速操纵的执行速度。。。
#p#分页标题#e#
另,上述步调中,有些日志和租约相关的操纵,从观念上来说,和目次操纵其实没有任何 接洽,可是,为了满意漫衍式系统的需求,这些操纵长短常有须要的,在此,按下不表。。 。
2、文件的读取
岂论是文件读取,照旧文件的写入,主控处事器饰演的都是中介的脚色。客户端把本身的 需求提交给主控处事器,主控处事器挑选符合的数据处事器,先容给客户端,让客户端和数 据处事器单聊,要读要写随你们便。这种计策雷同于DMA,低落了主控处事器的负载,提高了 效率。。。
因此,在文件读写操纵中,最主要的通信,产生在客户端与数据处事器之间。它们之间跑 的协议是ClientDatanodeProtocol。从这个协议中间,你无法看到和读写相关的接口,因为 ,在Hadoop中,读写操纵是不走RPC机制的,而是另立派别,独立搭了一套通信框架。在数据 处事器一端,DataNode类中有一个DataXceiverServer类的实例,它在一个单独的线程期待请 求,一旦接到,就启动一个DataXceiver的线程,处理惩罚此次请求。一个请求一个线程,对付数 据处事器来说,逻辑上很简朴。当下,DataXceiver支持的请求范例有六种,详细的请求包和 回覆包名目,请拜见这里,这里,这里。在Hadoop的实现中,并没有用类来封装这些请求, 而是按流的序次写下来,这给代码阅读带来挺多的贫苦,也对代码的维护带来必然的坚苦, 不知道是出于何种思量。。。
对比于写,文件的读取实在是一个简朴的进程。在客户端DFSClient中,有一个 DFSClient.DFSInputStream类。当需要读取一个文件的时候,会生成一个DFSInputStream的 实例。它会先挪用ClientProtocol界说getBlockLocations接口,提供应NameNode文件路径、 读取位置、读取长度信息,从中取得一个LocatedBlocks类的工具,这个工具包括一组 LocatedBlock,那内里有所划定位置中包括的所有数据块信息,以及数据块对应的所有数据 处事器的位置信息。当读取开始后,DFSInputStream会先实验从某个数据块对应的一组数据 处事器中选出一个,举办毗连。这个选取算法,在当下的实现中,很是简朴,就是选出第一 个未挂的数据处事器,并没有插手客户端与数据处事器相对位置的考量。读取的请求,发送 到数据处事器后,自然会有DataXceiver来处理惩罚,数据被一个包一个包发送回客户端,比及整 个数据块的数据都被读取完了,就会断开此链接,实验毗连下一个数据块对应的数据处事器 ,整个流程,依次如此重复,直到所有想读的都读取完了为止。。。
3、文件的写入
文件读取是一个一对一的进程,一个客户端,只需要与一个数据处事器接洽,就可以得到 所需的内容。可是,写入操纵,则是一个一对多的流程。一次写入,需要在所有存放相关数 据块的数据处事器都保持同步的更新,有任何的差错,整个流程就告失败。。。
在漫衍式系统中,一旦涉及到写入操纵,并发处理惩罚不免城市沉溺成为一个变了相的串行操 作。因为,假如差异的客户端假如是任意时序并发写入的话,整个写入的序次无法担保,可 能你写半笔记录我写半笔记录,最后出来的功效参差不齐不行估计。在HDFS中,并发写入的 序次节制,是由主控处事器来掌握的。当建设、续写一个文件的时候,该文件的节点类,由 INodeFile进级成为INodeFileUnderConstruction,INodeFileUnderConstruction是 INodeFile的子类,它起到一个锁的浸染。假如当一个客户端想建设或续写的文件是 INodeFileUnderConstruction,会激发异常,因为这说明这个此处有爷,请另寻高就,从而 保持了并发写入的序次性。同时,INodeFileUnderConstruction有包括了此时正在操纵它的 客户端的信息以及最后一个数据块的数据处事器信息,当追加写的时候可以更快速的响应。 。。
与读取雷同,DFSClient也有一个DFSClient.DFSOutputStream类,写入开始,会建设此类 的实例。DFSOutputStream会从NameNode上拿一个LocatedBlock,这内里有最后一个数据块的 所有数据处事器的信息。这些数据处事器每一个都需要可以或许正常事情(对付读取,只要尚有 一个能事情的就可以实现…),它们会依照客户端的位置被分列成一个有着最近物理间隔和 最小的序列(物理间隔,是按照呆板的位置定下来的…),这个排序问题雷同于著名观光商 问题,属于NP巨大度,可是由于处事器数量不多,所以用最粗暴的算法,也并不会看上去不 美。。。
#p#分页标题#e#
文件写入,就是在这一组数据处事器上结构成数据流的双向流水线。DFSOutputStream, 会与序列的第一个数据处事器成立Socket毗连,发送请求头,然后期待回应。DataNode同样 是成立DataXceiver来处理惩罚写动静,DataXceiver会依照包中传过来的其他处事器的信息,建 立与下一个处事器的毗连,并生成雷同的头,发送给它,并期待回包。此流程依次延续,直 到最后一级,它发送回包,反向着逐级通报,再次回到客户端。假如一切顺利,那么此时, 流水线成立乐成,开始正式发送数据。数据是分成一个个数据包发送的,所有写入的内容, 被缓存在客户端,当写满64K,会被封装成DFSOutputStream.Packet类实例,放入 DFSOutputStream的dataQueue行列。DFSOutputStream.DataStreamer会时刻监听这个行列, 一旦不为空,则开始发送,将位于dataQueue队首的包移动到ackQueue行列的队尾,暗示已发 送但尚未接管回覆的包行列。同时启动ResponseProcessor线程监听回包,直到收到相应回包 ,才将发送包从ackQueue中移除,暗示乐成。每一个数据处事器的DataXceiver收到了数据包 ,一边写入到当地文件中去,一边转发给下一级的数据处事器,期待回包,同前面成立流水 线的流程。。。
当一个数据块写满了之后,客户端需要向主控处事器申请追加新的数据块。这个会引起一 次数据块的分派,乐成后,会将新的数据处事器组返还给客户端。然后从头回到上述流程, 继承前行。。。
关于写入的流程,还可以拜见这里。另外,写入涉及到租约问题,后续会仔细的来说。。 。
IV. 漫衍式支持
假如单机的文件系统是田里勤恳的放牛娃,那么漫衍式文件系统就是刀尖上讨饭吃的马贼 了。在漫衍式情况中,有太多的意外,数据随时传输错误,处事器时刻筹备牺牲,许多泛泛 称为异常的现象,在这里都需要凭据泛泛事来看待。因此,对付漫衍式文件系统而言,仅仅 是满意了正常状况下文件系统各项处事还不足,还需要担保漫衍式各类意外场景下康健一连 的处事,不然,将一无是处。。。
1、处事器的错误规复
在漫衍式情况中,哪台处事器牺牲都是常见的工作,牺牲不行怕,可骇的是你都没有时刻 筹备好它们会牺牲。作为一个及格的漫衍式系统,HDFS虽然时刻筹备好了前赴后继奋勇向前 。HDFS有三类处事器,每一类处事器堕落了,都有相应的应急计策。。。
a. 客户端
生命最轻如鸿毛的童鞋,应该就是客户端了。究竟,做为一个文件系统的利用者,在整个 文件系统中的职位,不免有些归于三流。而作为客户端,大部门时候,牺牲了就牺牲了,没 人哀伤,无人同情,只有在在辛勤写入的时候,不幸辞世(呆板挂了,可能网络断了,诸如 此类…),才会引起些惊愕。因为,此时而今,在主控处事器上对应的文件,正作为 INodeFileUnderConstruction在世,仅仅为占有它的谁人客户端处事者,做为一个专一的文 件,它不答允此外客户端染指。这样的话,一旦占有它的客户端处事者牺牲了,此客户端会 依然占着茅坑不拉屎,让如花似玉INodeFileUnderConstruction孤孑立单守寡终身。这种事 情虽然无法容忍,因此,必需有步伐办理这个问题,步伐就是:租约。。。
租约,顾名思义,就是当客户端需要占用某文件的时候,与主控处事器签订的一个短期合 同。这个条约有一个期限,在这个期限内,客户端可以耽误条约期限,一旦高出期限,主控 处事器会强行终止此租约,将这个文件的享用权,分派给他人。。。
在打开或建设一个文件,筹备追加写之前,会挪用LeaseManager的addLease要领,在指定 的路径下与此客户端签订一份租约。客户端会启动DFSClient.LeaseChecker线程,按时轮询 挪用ClientProtocol的renewLease要领,续签租约。在主控处事器一端,有一个 LeaseManager.Monitor线程,始终在轮询查抄所有租约,查察是否有到期未续的租约。假如 一切正常,该客户端完成写操纵,会封锁文件,遏制租约,一旦有所意外,好比文件被删除 了,客户端牺牲了,主控处事器城市剥夺此租约,如此,来制止由于客户端停机带来的资源 被恒久攻克的问题。。。
b. 数据处事器
虽然,会挂的不可是客户端,海量的数据处事器是一个更不不变的因素。一旦某数据处事 器牺牲了,而且主控处事器被蒙在鼓中,主控处事器就会变相的欺骗客户端,给它们无法连 接的读写处事器列表,导致它们随处碰鼻无法事情。因此,为了整个系统的不变,数据处事 器必需时刻向主控处事器讲述,保持主控处事器对其的完全相识,这个机制,就是心跳动静 。在HDFS中,主控处事器NameNode实现了DatanodeProtocol接口,数据处事器DataNode会在 主轮回中,不断的挪用该协议中的sendHeartbeat要领,向NameNode讲述状况。在此挪用中, DataNode会将其整体运行状况奉告NameNode,好比:有几多可用空间、用了多大的空间,等 等之类。NameNode会记着此DataNode的运行状况,作为新的数据块分派或是负载平衡的依据 。当NameNode处理惩罚完成此动静后,会将相关的指令封装成一个DatanodeCommand工具,交还给 DataNode,汇报数据处事器什么数据块要删除什么数据块要新增等等之类,数据处事器以此 为本身的动作依据。。。
#p#分页标题#e#
可是,sendHeartbeat并没有提供当地的数据块信息给NameNode,那么主控处事器就无法 知道此数据处事器应该分派什么数据块应该删除什么数据块,那么它是如何抉择的呢?谜底 就是DatanodeProtocol界说的另一个要领,blockReport。DataNode也是在主轮回中按时挪用 此要领,只是,其周期凡是比挪用sendHeartbeat的更长。它会提交当地的所有数据块状况给 NameNode,NameNode会和当地生存的数据块信息较量,抉择什么该删除什么该新增,并将相 关功效缓存在当地对应的数据布局中,期待此处事器再发送sendHeartbeat动静过来的时候, 依照这些数据布局中的内容,做出相应的DatanodeCommand指令。blockReport要领同样也会 返回一个DatanodeCommand给DataNode,但凡是,只是为空(只有堕落的时候不为空),我想 ,增加缓存,也许是为了确保每个指令都可以反复发送并确定被执行。。。
c. 主控处事器
虽然,作为整个系统的焦点和单点,坚苦卓绝的主控处事器含泪西去,整个漫衍式文件服 务集群将彻底瘫痪歇工。如安在主控处事器牺牲后,提拔新的主控处事器并迅速使其进入工 作脚色,就成了系统必需思量的问题。办理计策就是:日志。。。
其实这并不是啥新鲜对象,一看就知道是从数据库那儿偷师而来的。在主控处事器上,所 有对文件目次操纵的要害步调(详细文件内容所处的数据处事器,是不会被写入日志的,因 为这些内容是动态成立的…),城市被写入日志。别的,主控处事器会在某些时刻,将当下 的文件目次完整的序列化到当地,这称为镜像。一旦存有镜像,镜像前期所写的日志和其他 镜像,都纯属冗余,其汗青使命已经完成,可以报废删除了。在主控处事器不幸牺牲,可能 是计谋性的停机修整竣事,并从头启动后,主控处事器会按照最近的镜像 + 镜像之后的所有 日志,重建整个文件目次,迅速将处事本领规复到牺牲前的水准。。。
对付数据处事器而言,它们会通过一些手段,迅速得知顶头上司的更迭动静。它们会立即 转投新雇主的名下,在新雇主旗下注册,并开始向其发送心跳动静,这个机制,大概用漫衍 式协同处事来实现,这里不说也罢。。。
在HDFS的实现中,FSEditLog类是整个日志体系的焦点,提供了一大堆利便的日志写入API ,以及日志的规复存储等成果。今朝,它支持若干种日志范例,都冠以OP_XXX,并提供相关 API,详细可以拜见这里。为了担保日志的安详性,FSEditLog提供了 EditLogFileOutputStream类作为写入的承载类,它会同时开若干个当地文件,然后依次写入 ,防备日志的损坏导致不行估计的效果。在FSEditLog上面,有一个FSImage类,存储文件镜 像并挪用FSEditLog对外提供相关的日志成果。FSImage是Storage类的子类,假如对数据块的 报告有所印象的话,你可以回想起来,凡事以后类派生出来的对象,都具有版天性质,可以 举办进级和回滚等等,以此,来实现发生镜像是对原有日志和镜像处理惩罚的巨大逻辑。。。
今朝,在HDFS的日志系统中,有些处所与GFS的描写有所差异。在HDFS中,所有日志文件 和镜像文件都是当地文件,这就相当于,把日志放在自家的保险箱中,一旦主控处事器挂了 ,此外后继而上的处事器也无法拿到这些日志和镜像,用于重振雄风。因此,在HDFS中,运 行着一个SecondaryNameNode处事器,它做为主控处事器的替补,隐忍厚积薄发为篡位做好准 备,个中,焦点内容就是:按期下载并处理惩罚日志和镜像。SecondaryNameNode看上去像客户端 一样,与NameNode之间,走着NamenodeProtocol协议。它会不断的查察主控处事器上面累计 日志的巨细,当到达阈值后,挪用doCheckpoint函数,此函数的主要步调包罗:
首先是挪用startCheckpoint做一些当地的初始化事情;
然后挪用rollEditLog,将NameNode上此时操纵的日志文件从edit切到edit.new上来,这 个操纵瞬间完成,上层写日志的函数完全感受不到不同;
接着,挪用downloadCheckpointFiles,将主控处事器上的镜像文件和日志文件都下载到 此候补主控处事器上来;
并挪用doMerge,打开镜像和日志,将日志生成新的镜像,生存包围;
下一步,挪用putFSImage把新的镜像上传回NameNode;
再挪用rollFsImage,将镜像换成新的,在日志从edit.new更名为edit;
最后,挪用endCheckpoint做收尾事情。
#p#分页标题#e#
整个算法涉及到NameNode和SecondaryNameNode两个处事器,最终功效是NameNode和 SecondaryNameNode都依照算法举办前的日志生成了镜像。而两个处事器上日志文件的内容, 前者是整个算法举办期间所写的日志,后者始终不会有任何日志。当主控处事器牺牲的时候 ,运行SecondaryNameNode的处事器立即被扶正,在其上启动主控处事,操作其日志和镜像, 规复文件目次,并慢慢接管各数据处事器的注册,最终向外提供不变的文件处事。。。
同样的工作,GFS回收的大概是别的一个计策,就是在写日志的时候,并不范围在当地, 而是同时书写网络日志,即在若干个长途处事器上生成同样的日志。然后,在某些机缘,主 控处事器本身,生成镜像,低夕阳志局限。当主控处事器牺牲,可以在拥有网络日志的处事 器上启动主控处事,进级成为主控处事器。。。
GFS与HDFS的计策对较量,前者是化整为零,后者则是批量处理惩罚,凡是我们认为,批量处 理的平均效率更高一些,且相对而言,大概实现起来容易一些,可是,由于有间歇期,会导 致日志的丢失,从而无法100%的将备份主控处事器的状态与主控处事器完全同步。。。
2、数据的正确性担保
在巨大纷繁的漫衍式情况中,我们刚强的相信,万事皆有大概。哪怕各个处事器都舒舒服 服的在世,也大概有各类百般的环境导致网络传输中的数据丢失可能错误。而且在漫衍式文 件系统中,同一份文件的数据,是存在大量冗余备份的,系统必需要维护所有的数据块内容 完全同步,不然,一人一言,差异客户端读同一个文件读出差异数据,用户非得疯了不行。 。。
在HDFS中,为了担保数据的正确性和同一份数据的一致性,做了大量的事情。首先,每一 个数据块,都有一个版本标识,在Block类中,用一个长整型的数generationStamp来暗示版 本信息(Block类是所有暗示数据块的数据布局的基类),一旦数据块上的数据有所变革,此 版本号将向前增加。在主控处事器上,生存有此时每个数据块的版本,一旦呈现数据处事器 上相关数据块版本与其纷歧致,将会触发相关的规复流程。这样的机制担保了各个数据处事 器器上的数据块,在根基大偏向上都是一致的。可是,由于网络的巨大性,简朴的版本信息 无法担保详细内容的一致性(因为此版本信息与内容无关,大概会呈现版内情同,但内容不 同的状况)。因此,为了担保数据内容上的一致,必需要依照内容,作出签名。。。
当客户端向数据处事器追加写入数据包时,每一个数据包的数据,城市切分成512字节大 小的段,作为签名验证的根基单元,在HDFS中,把这个数据段称为Chunk,即传输块(留意, 在GFS中,Chunk表达的是数据块…)。在每一个数据包中,都包括若干个传输块以及每一个 传输块的签名,当下,这个签名是按照Java SDK提供的CRC算法算得的,其实就是一个奇偶校 验。当数据包传输到流水线的最后一级,数据处事器会对其举办验证(想一想,为什么只在 最后一级做验证,而不是每级都做…),一旦发明当前的传输块签名与在客户端中的签名不 一致,整个数据包的写入被视为无效,Lease Recover(租约规复)算法被触发。。。
从根基道理上看,这个算法很简朴,就是取所有数据处事器上此数据块的最小长度看成正 确内容的长度,将其他数据处事器上此数据块超出此长度的部门切除。从正确性上看,此算 法无疑是正确的,因为至少有一个数据处事器会发明此错误,并拒绝写入,那么,假如写入 了的,都是正确的;从效率上看,此算法也是高效的,因为它制止了反复的传输和巨大的验 证,仅仅是各自删除尾部的一些内容即可。但从详细实现上来看,此算法稍微有些绕,因为 ,为了低落本已不堪重负的主控处事器的承担,此算法不是由主控处事器这个大脑提倡的, 而是通过选举一个数据处事器作为Primary,由Primary提倡,通过挪用与其他各数据处事器 间的InterDatanodeProtocol协议,最终完成的。详细的算法流程,拜见LeaseManager类上面 的注释。需要说明的是此算法的触发机缘和提倡者。此算法可以由客户端可能是主控处事器 提倡,当客户端在写入一个数据包失败后,会提倡租约规复。因为,一次写入失败,岂论是 何种原因,很有大概就会导致流水线上有的处事器写了,有的没写,从而造成不统一。而主 控处事器提倡的机缘,则是在占有租约的客户端超出一按时限没有续签,这说明客户端大概 挂了,在临死前大概干过倒霉于数据块统一的工作,作为监视者,主控处事器需要提倡一场 规复举动,确保一切正确。。。
3、负载平衡
#p#分页标题#e#
负载的平衡,是漫衍式系统中一个永恒的话题,要让各人各尽其力齐心干活,发挥各自独 特的优势,不能忙得忙死闲得闲死,影响战斗力。并且,负载平衡也是一个巨大的问题,什 么是平衡,是一个很恍惚的观念。好比,在漫衍式文件系统中,总共三百个数据块,平均分 配到十个数据处事器上,就算平衡了么?其实不必然,因为每一个数据块需要若干个备份, 各个备份的漫衍应该充实思量到机架的位置,同一个机架的处事器间通信速度更快,而漫衍 在差异机架则更具有安详性,不会在一棵树上吊死。。。
在这里说的负载平衡,是宽泛意义上的平衡进程,主要涵盖两个阶段的事务,一个是在任 务初始分派的时候尽大概公道分派,另一个是在过后时刻监视实时调解。。。
在HDFS中,ReplicationTargetChooser类,是认真实现为新分派的数据块寻找婆家的。基 本上来说,数据块的分派事情和备份的数量、申请的客户端地点(也就是写入者)、已注册 的数据处事器位置,密切相关。其算法根基思路是只考量静态位置信息,优先照顾写入者的 速度,让多份备份分派到差异的机架去。详细算法,自行拜见源码。另外,HDFS的Balancer 类,是为了实现动态的负载调解而存在的。Balancer类派生于Tool类,这说明,它是以一个 独立的历程存在的,可以独立的运行和设置。它运行有NamenodeProtocol和ClientProtocol 两个协议,与主控处事器举办通信,获取各个数据处事器的负载状况,从而举办调解。主要 的调解其实就是一个操纵,将一个数据块从一个处事器搬家到另一个处事器上。Balancer会 向相关的方针数据处事器发出一个DataTransferProtocol.OP_REPLACE_BLOCK动静,吸收到这 个动静的数据处事器,会将数据块写入当地,乐成后,通知主控处事器,删除早先的谁人数 据处事器上的同一块数据块。详细的算法请自行参考源码。。。
4、垃圾接纳
对付垃圾,各人应该耳熟能详了,在漫衍式文件系统而言,没有操作代价的数据块备份, 就是垃圾。在现实糊口中,我们倡导垃圾分类,为了更好的领略漫衍式文件系统的垃圾收集 ,搞个分类也是很有须要的。根基上,所有的垃圾都可以视为两类,一类是由系统正常逻辑 发生的,好比某个文件被删除了,所有相关的数据块都沦为垃圾了,某个数据块被负载平衡 器移动了,原始数据块也不幸成了垃圾了。此类垃圾最大的特点,就是主控处事器是生成垃 圾的祸首罪魁,也就是说主控处事器完全相识有哪些垃圾需要处理惩罚。别的尚有一类垃圾,是 由于系统的一些异常症状发生的,好比某个数据处事器停机了一段,重启之后发明其上的某 个数据块已经在其他处事器上从头增加了此数据块的备份,它上面的谁人备份逾期了失去价 值了,需要被看成垃圾来处理惩罚了。此类垃圾的特点恰恰相反,主控处事器无法直接相识到垃 圾状况,需要曲线救国。。。
在HDFS中,第一类垃圾的鉴定自然很容易,在一些正常的逻辑中发生的垃圾,全部被塞进 了FSNamesystem的recentInvalidateSets这个Map中。而第二类垃圾的鉴定,则放在数据处事 器发送其数据块信息来的进程中,颠末与当地信息的较量,可以断定,此数据处事器上有哪 些数据块已经不幸沦为垃圾。同样,这些垃圾也被塞到recentInvalidateSets中去。在与数 据处事器举办心跳交换的进程中,主控处事器会将它上面有哪些数据块需要删除,数据处事 器对这些数据块的立场是,直接物理删除。在GFS的论文中,对如何删除一个数据块有着差异 的领略,它觉着应该先缓存起来,过几天没人想规复它了再删除。在HDFS的文档中,则明晰 暗示,在现行的应用场景中,没有需要这个需求的处所,因此,直接删除就完了。这说明, 理念是一切分歧的基础:)。。。
V. 总结
#p#分页标题#e#
整个漫衍式文件系统,计较系统,数据库系统的设计理念,根基是一脉相承的。三类处事 器、作为单点存在的焦点节制处事器、基于日志的规复机制、基于租约的保持接洽机制、等 等,在后续漫衍式计较系统和漫衍式数据库中都可以看到雷同的影子,在漫衍式文件系统这 里,我详述了这些内容,大概在后续就会默认知道而说的较量大略了。而刨去这一些,漫衍 式文件系统中最大特点,就是文件块的冗余存储,它直接导致了较为巨大的写入流程。虽然 ,虽说漫衍式文件系统在漫衍式计较和数据库中都有用到,但假如对其机理没有乐趣,只要 把它当成是一个可以在任何呆板上利用的文件系统,就不会对其他上层修建的领略发生障碍 。
