漫衍式基本进修【二】 —— 漫衍式计较系统(Map/Reduce)
副标题#e#
二. 漫衍式计较(Map/Reduce)
漫衍式式计较,同样是一个宽泛的观念,在这里,它狭义的指代,按Google Map/Reduce 框架所设计的漫衍式框架。在Hadoop中,漫衍式文件系统,很洪流平上,是为各类漫衍式计 算需求所处事的。我们说漫衍式文件系统就是加了漫衍式的文件系统,雷同的界说推广到分 布式计较上,我们可以将其视为增加了漫衍式支持的计较函数。从计较的角度上看, Map/Reduce框架接管各类名目标键值对文件作为输入,读取计较后,最终生成自界说名目标 输出文件。而从漫衍式的角度上看,漫衍式计较的输入文件往往局限庞大,且漫衍在多个机 器上,单机计较完全不行支撑且效率低下,因此Map/Reduce框架需要提供一套机制,将此计 算扩展到无限局限的呆板集群长举办。依照这样的界说,我们对整个Map/Reduce的领略,也 可以别离沿着这两个流程去看。。。
在Map/Reduce框架中,每一次计较请求,被称为功课。在漫衍式计较Map/Reduce框架中, 为了完成这个功课,它举办两步走的计谋,首先是将其拆分成若干个Map任务,分派到差异的 呆板上去执行,每一个Map任务拿输入文件的一部门作为本身的输入,颠末一些计较,生成某 种名目标中间文件,这种名目,与最终所需的文件名目完全一致,可是仅仅包括一部门数据 。因此,比及所有Map任务完成后,它会进入下一个步调,用以归并这些中间文件得到最后的 输出文件。此时,系统会生成若干个Reduce任务,同样也是分派到差异的呆板去执行,它的 方针,就是将若干个Map任务生成的中间文件为汇总到最后的输出文件中去。虽然,这个汇总 不总会像1 + 1 = 2那么直接了当,这也就是Reduce任务的代价地址。颠末如上步调,最终, 功课完成,所需的方针文件生成。整个算法的要害,就在于增加了一其中间文件生成的流程 ,大大提高了机动性,使其漫衍式扩展性获得了担保。。。
I. 术语比较
和漫衍式文件系统一样,Google、Hadoop和….我,各执一种方法表述统一观念,为了保 证其统一性,特有下表。。。
| 文中翻译 | Hadoop术语 | Google术语 | 相关表明 |
| 功课 | Job | Job | 用户的每一个计较请求,就称为一个功课。 |
| 功课处事器 | JobTracker | Master | 用户提交功课的处事器,同时,它还认真各个功课任务的分 配,打点所有的任务处事器。 |
| 任务处事器 | TaskTracker | Worker | 任劳任怨的工蜂,认真执行详细的任务。 |
| 任务 | Task | Task | 每一个功课,都需要拆分隔了,交由多个处事器来完成,拆 分出来的执行单元,就称为任务。 |
| 备份任务 | Speculative Task | Buckup Task | 每一个任务,都有大概执行失败可能迟钝,为了低落为此付 出的价钱,系统会未雨绸缪的实此刻别的的任务处事器上执行同样一个任务,这就是备份任 务。 |
#p#副标题#e#
II. 根基架构
与漫衍式文件系统雷同,Map/Reduce的集群,也由三类处事器组成。个中功课处事器,在 Hadoop中称为Job Tracker,在Google论文中称为Master。前者汇报我们,功课处事器是认真 打点运行在此框架下所有功课的,后者汇报我们,它也是为各个功课分派任务的焦点。与 HDFS的主控处事器雷同,它也是作为单点存在的,简化了认真的同步流程。详细的认真执行 用户界说操纵的,是任务处事器,每一个功课被拆分成许多的任务,包罗Map任务和Reduce任 务等,任务是详细执行的根基单位,它们都需要分派到符合任务处事器上去执行,任务处事 器一边执行一边向功课处事器讲述各个任务的状态,以此来辅佐功课处事器相识功课执行的 整体环境,分派新的任务等等。。。
除了功课的打点者执行者,还需要有一个任务的提交者,这就是客户端。与漫衍式文件系 统一样,客户端也不是一个单独的历程,而是一组API,用户需要自界说好本身需要的内容, 经过客户端相关的代码,将功课及其相关内容和设置,提交到功课处事器去,并时刻监控执 行的状况。。。
#p#分页标题#e#
同作为Hadoop的实现,与HDFS的通信机制沟通,Hadoop Map/Reduce也是用了协议接口来 举办处事器间的交换。实现者作为RPC处事器,挪用者经过RPC的署理举办挪用,如此,完成 大部门的通信,详细处事器的架构,和个中运行的各个协议状况,拜见下图。从图中可以看 到,与HDFS对比,相关的协议少了几个,客户端与任务处事器,任务处事器之间,都不再有 直接通信干系。这并不料味着客户端就不需要相识详细任务的执行状况,也不料味着,任务 处事器之间不需要相识别家任务执行的景象,只不外,由于整个集群各呆板的接洽比HDFS复 杂的多,直接通信过于的难以维系,所以,都统一由功课处事器整理转发。别的,从这幅图 可以看到,任务处事器不是一小我私家在战斗,它会像孙悟空一样招出一群宝宝辅佐其详细执行 任务。这样做的长处,小我私家以为,应该有安详性方面的思量,究竟,任务的代码是用户提交 的,数据也是用户指定的,这质量自然良莠不齐,万一碰上个搞粉碎的,把整个任务处事器 历程搞死了,就因小失大了。因此,放在单独的土地举办,爱咋咋地,也算是权责明晰了。 。。
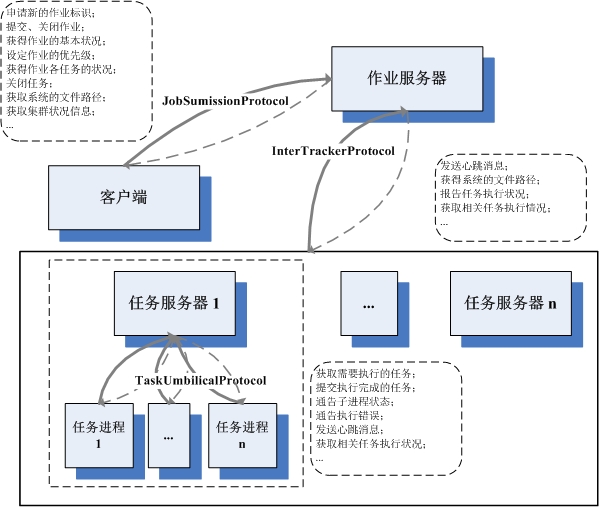
与漫衍式文件系统对比,Map/Reduce框架的尚有一个特点,就是可定制性强。文件系统中 许多的算法,都是很牢靠和直观的,不会由于所存储的内容差异而有太多的变革。而作为通 用的计较框架,需要面临的问题则要巨大许多,在各类差异的问题、差异的输入、差异的需 求之间,很难有一种包治百病的药可以或许一招鲜吃遍天。作为Map/Reduce框架而言,一方面要 尽大概的抽取出民众的一些需求,实现出来。更重要的,是需要提供精采的可扩展机制,满 足用户自界说各类算法的需求。Hadoop是由Java来实现的,因此通过反射来实现自界说的扩 展,显得较量小菜一碟了。在JobConf类中,界说了大量的接口,这根基上是Hadoop Map/Reduce框架所有可定制内容的一次会合展示。在JobConf中,有大量set接口接管一个 Class<? extends xxx>的参数,凡是它都有一个默认实现的类,用户假如不满足,则 可自界说实现。。。
III. 计较流程
假如一切都按部就班的举办,那么整个功课的计较流程,应该是功课的提交 -> Map任 务的分派和执行 -> Reduce任务的分派和执行 -> 功课的完成。而在每个任务的执行 中,又包括输入的筹备 -> 算法的执行 -> 输出的生成,三个子步调。沿着这个流程 ,我们可以很快的整理清晰整个Map/Reduce框架下功课的执行。。。
1、功课的提交
一个功课,在提交之前,需要把所有应该设置的对象都设置好,因为一旦提交到了功课服 务器上,就陷入了完全自动化的流程,用户除了张望,最多也就能起一个监视浸染,惩办一 些欠好功德情的任务。。。
根基上,用户在提交接码阶段,需要做的事情主要是这样的:
首先,书写好所有自定的代码,最起码,需要有Map和Reduce的执行代码。在Hadoop中, Map需要派生自Mapper<K1, V1, K2, V2>接口,Reduce需要派生自Reducer<K2, V2, K3, V3>接口。这里都是用的泛型,用以支持差异的键值范例。这两个接口都仅有一个方 法,一个是map,一个是reduce,这两个要领都直接管四个参数,前两个是输入的键和值相关 的数据布局,第三个是作为输出相关的数据布局,最后一个,是一个Reporter类的实例,实 现的时候可以操作它来统计一些计数。除了这两个接口,尚有大量可以派生的接口,好比分 割的Partitioner<K2, V2>接口。。。
然后,需要书写好主函数的代码,个中最主要的内容就是实例化一个JobConf类的工具, 然后挪用其富厚的setXXX接口,设定好所需的内容,包罗输入输出的文件路径,Map和Reduce 的类,甚至包罗读取写入文件所需的名目支持类,等等。。。
最后,挪用JobClient的runJob要领,提交此JobConf工具。runJob要了解先行挪用到 JobSubmissionProtocol接口所界说的submitJob要领,将此功课,提交给功课处事器。接着 ,runJob开始轮回,不断的挪用JobSubmissionProtocol的getTaskCompletionEvents要领, 得到TaskCompletionEvent类的工具实例,相识此功课各任务的执行状况。。。
2、Map任务的分派
#p#分页标题#e#
当一个功课提交到了功课处事器上,功课处事器会生成若干个Map任务,每一个Map任务, 认真将一部门的输入转换成名目与最终名目沟通的中间文件。凡是一个功课的输入都是基于 漫衍式文件系统的文件(虽然在单机情况下,文件系统单机的也可以…),因为,它可以很 天然的和漫衍式的计较发生接洽。而对付一个Map任务而言,它的输入往往是输入文件的一个 数据块,可能是数据块的一部门,但凡是,不跨数据块。因为,一旦跨了数据块,就大概涉 及到多个处事器,带来了不须要的巨大性。。。
当一个功课,从客户端提交到了功课处事器上,功课处事器会生成一个JobInProgress对 象,作为与之对应的标识,用于打点。功课被拆分成若干个Map任务后,会预先挂在功课处事 器上的任务处事器拓扑树。这是依照漫衍式文件数据块的位置来分另外,好比一个Map任务需 要用某个数据块,这个数据块有三份备份,那么,在这三台处事器上城市挂上此任务,可以 视为是一个预分派。。。
关于任务打点和分派的大部门的真实成果和逻辑的实现,JobInProgress则依托 JobInProgressListener和TaskScheduler的子类。TaskScheduler,顾名思义是用于任务分派 的计策类(为了简化描写,用它代指所有TaskScheduler的子类…)。它会把握好所有功课 的任务信息,其assignTasks函数,接管一个TaskTrackerStatus作为参数,依照此任务处事 器的状态和现有的任务状况,为其分派新的任务。而为了把握所有功课相关任务的状况, TaskScheduler会将若干个JobInProgressListener注册到JobTracker中去,当有新的功课到 达、移除或更新的时候,JobTracker会奉告给所有的JobInProgressListener,以便它们做出 相应的处理惩罚。。。
任务分派是一个重要的环节,所谓任务分派,就是将符合功课的符合任务分派到符合的服 务器上。不丢脸出,内里蕴含了两个步调,先是选择功课,然后是在此功课中选择任务。和 所有分派事情一样,任务分派也是一个巨大的活。不精采的任务分派,大概会导致网络流量 增加、某些任务处事器负载过重效率下降,等等。不只如此,任务分派照旧一个无一致模式 的问题,差异的业务配景,大概需要差异的算法才气满意需求。因此,在Hadoop中,有许多 TaskScheduler的子类,像Facebook,Yahoo,都为其孝敬出了自家用的算法。在Hadoop中, 默认的任务分派器,是JobQueueTaskScheduler类。它选择功课的根基序次是:Map Clean Up Task(Map任务处事器的清理任务,用于清理相关的逾期的文件和情况…) -> Map Setup Task(Map任务处事器的安装任务,认真设置好相关的情况…) -> Map Tasks – > Reduce Clean Up Task -> Reduce Setup Task -> Reduce Tasks。在这个前提 下,详细到Map任务的分派上来。当一个任务处事器事情的游刃有余,等候得到新的任务的时 候,JobQueueTaskScheduler会凭据各个功课的优先级,从最高优先级的功课开始分派。每分 配一个,还会为其留出余量,已被不时之需。举一个例子:系统今朝有优先级3、2、1的三个 功课,每个功课都有一个可分派的Map任务,一个任务处事器来申请新的任务,它尚有本领承 载3个任务的执行,JobQueueTaskScheduler会先从优先级3的功课上取一个任务分派给它,然 后再留出一个1任务的余量。此时,系统只能在将优先级2功课的任务分派给此处事器,而不 能分派优先级1的任务。这样的计策,根基思路就是一切为高优先级的功课处事,优先分派不 说,分派了好保存有余力以备不时之需,如此优待,足以让高优先级的功课喜极而泣,让低 优先级的功课感应既生瑜何生亮,甚至是活活饿死。。。
确定了从哪个功课提取任务后,详细的分派算法,颠末一系列的挪用,最后实际是由 JobInProgress的findNewMapTask函数完成的。它的算法很简朴,就是尽全力为此处事器非配 且尽大概好的分派任务,也就是说,只要尚有可分派的任务,就必然会分给它,而不思量后 来者。功课处事器会从离它最近的处事器开始,看上面是否还挂着未分派的任务(预分派上 的),从近到远,假如所有的任务都分派了,那么看有没有开启多次执行,假如开启,思量 把未完成的任务再分派一次(后头有处所详述…)。。。
对付功课处事器来说,把一个任务分派出去了,并不料味着它就彻底解放,可以对此任务 可以不管掉臂了。因为任务可以在任务处事器上执行失败,大概执行迟钝,这都需要功课服 务器辅佐它们再来一次。因此在Task中,记录有一个TaskAttemptID,对付任务处事器而言, 它们每次跑的,其实都只是一个Attempt罢了,Reduce任务只需要采信一个的输出,其他都算 白忙乎了。。。
3、Map任务的执行
#p#分页标题#e#
与HDFS雷同,任务处事器是通过心跳动静,向功课处事器讲述此时而今其上各个任务执行 的状况,并向功课处事器申请新的任务的。详细实现,是TaskTracker挪用 InterTrackerProtocol协议的heartbeat要领来做的。这个要领接管一个TaskTrackerStatus 工具作为参数,它描写了此时此任务处事器的状态。当其有余力接管新的任务的时候,它还 会传入acceptNewTasks为true的参数,暗示但愿功课处事器委以重任。JobTracker吸收到相 关的参数后,颠末处理惩罚,会返回一个HeartbeatResponse工具。这个工具中,界说了一组 TaskTrackerAction,用于指导任务处事器举办下一步的事情。系统中已界说的了一堆其 TaskTrackerAction的子类,有的对携带的参数举办了扩充,有的只是标明白下ID,详细不详 写了,一看便知。。。
当TaskTracker收到的TaskTrackerAction中,包括了LaunchTaskAction,它会开始执行所 分派的新的任务。在TaskTracker中,有一个TaskTracker.TaskLauncher线程(确切的说是两 个,一个等Map任务,一个等Reduce任务),它们在痴痴的守候着新任务的来到。一旦比及了 ,会最终挪用到Task的createRunner要领,结构出一个TaskRunner工具,新建一个线程来执 行。对付一个Map任务,它对应的Runner是TaskRunner的子类MapTaskRunner,不外,焦点部 分都在TaskRunner的实现内。TaskRunner会先将所需的文件全部下载并拆包好,并记录到一 个全局缓存中,这是一个全局的目次,可以供所有此功课的所有任务利用。它会用一些软链 接,将一些文件名链接到这个缓存中来。然后,按照差异的参数,设置出一个JVM执行的情况 ,这个情况与JvmEnv类的工具对应。
接着,TaskRunner会挪用JvmManager的launchJvm要领,提交给JvmManager处理惩罚。 JvmManager用于打点该TaskTracker上所有运行的Task子历程。在今朝的实现中,实验的是池 化的方法。有若干个牢靠的槽,假如槽没有满,那么就启动新的子历程,不然,就寻找idle 的历程,假如是同Job的直接放进去,不然杀死这个历程,用一个新的历程取代。每一个历程 都是由JvmRunner来打点的,它也是位于单独线程中的。可是从实现上看,这个机制仿佛没有 陈设开,子历程是死轮回期待,而不会阻塞在父历程的相关线程上,父线程的变量一直都没 有个调解,一旦分派,始终都处在忙碌的状况了。
真实的执行载体,是Child,它包括一个main函数,历程执行,会将相关参数传进来,它 会拆解这些参数,而且结构出相关的Task实例,挪用其run函数举办执行。每一个子历程,可 以执行指定个数量的Task,这就是上面所说的池化的设置。可是,这套机制在我看来,并没 有运行起来,每个历程其实都没有时机不死而执行新的任务,只是傻傻的期待历程池满,而 被一刀毙命。也许是我老眼昏花,没看出个中实现的眉目。。。
4、Reduce任务的分派与执行
比之Map任务,Reduce的分派及其简朴,根基上是所有Map任务完成了,有空闲的任务处事 器,来了就给分派一个Job任务。因为Map任务的功效星罗棋布,且变革多端,真要搞一个全 局优化的算法,绝对是得不偿失。而Reduce任务的执行历程的结构和分派流程,与Map根基完 全的一致,没有啥可说的了。。。
但其实,Reduce任务与Map任务的最大差异,是Map任务的文件都在当地隔着,而Reduce任 务需要处处收罗。这个流程是功课处事器经过此Reduce任务所处的任务处事器,汇报Reduce 任务正在执行的历程,它需要的Map任务执行过的处事器地点,此Reduce任务处事器会于原 Map任务处事器接洽(虽然当地就免了…),通过FTP处事,下载过来。这个隐含的直接数据 接洽,就是执行Reduce任务与执行Map任务最大的差异了。。。
5、功课的完成
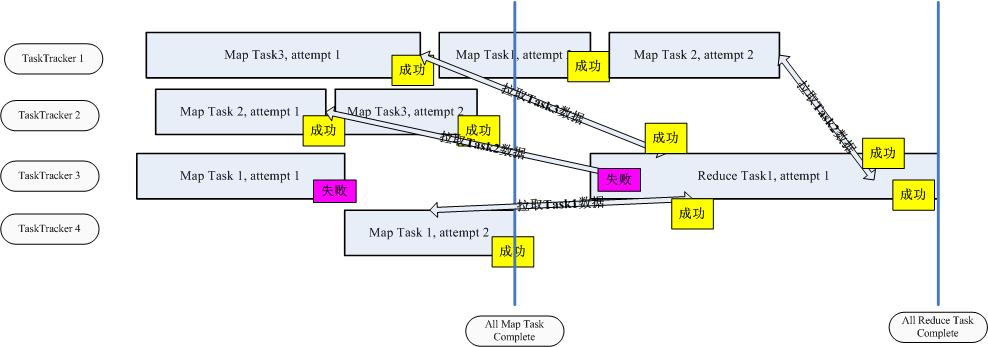
当所有Reduce任务都完成了,所需数据都写到了漫衍式文件系统上,整个功课才正式完成 了。此中,涉及到许多的类,许多的文件,许多的处事器,所以说起来很费劲,话说,一图 解千语,说了那么多,我照旧画两幅图,彻底表达一下吧。。。
首先,是一个时序图。它模仿了一个由3个Map任务和1个Reduce任务组成的功课执行流程 。我们可以看到,在执行的进程中,只要有人太慢,可能失败,就会增加一次实验,以此换 取最快的执行总时间。一旦所有Map任务完成,Reduce开始运作(其实,不必然要这样的… ),对付每一个Map任务来说,只有执行到Reduce任务把它上面的数据下载完成,才算乐成, 不然,都是失败,需要从头举办实验。。。
#p#分页标题#e#
而第二副图,不是我画的,就不转载了,拜见这里,它描写了整个Map/Reduce的处事器状 况图,包罗整体流程、所处处事器历程、输入输出等,看清楚这幅图,对Map/Reduce的根基 流程应该能完全跑通了。有这几点,大概图中描写的不足清晰需要提及一下,一个是在HDFS 中,其实尚有日志文件,图中没有标明;另一个是步调5,其实是由TaskTracker主动去拉取 而不是JobTracker推送过来的;尚有步调8和步调11,建设出来的MapTask和ReduceTask,在 Hadoop中都是运行在独立的历程上的。。。
IV. Map任务详请
从上面,可以相识到整个Map和Reduce任务的整体流程,尔后头要烦琐的,是详细执行中 的细节。Map任务的输入,是漫衍式文件系统上的,包括键值对信息的文件。为了给每一个 Map任务指定输入,我们需要把握文件名目把它分切成块,并从每一块中疏散出键值信息。在 HDFS中,输入的文件名目,是由InputFormat<K, V>类来暗示的,在JobConf中,它的 默认值是TextInputFormat类(见getInputFormat),此类是特化的 FileInputFormat<LongWritable, Text>子类,而FileInputFormat<K, V>正是 InputFormat<K, V>的子类。通过这样的干系我们可以很容易的领略,默认的文件名目 是文本文件,且键是LongWritable范例(整形数),值是Text范例(字符串)。仅仅知道文 件范例是不足的,我们还需要将文件中的每一条数据,疏散成键值对,这个事情,是 RecordReader<K, V>来做的。在TextInputFormat的getRecordReader要领中我们可以 看到,与TextInputFormat默认配套利用的,是LineRecordReader类,是特化的 RecordReader<LongWritable, Text>的子类,它将每一行作为一个记录,起始的位置 作为键,整行的字符串作为值。有了名目,分出了键值,还需要切开分给每一个Map任务。每 一个Map任务的输入用InputSplit接口暗示,对付一个文件输入而言,其实现是FileSplit, 它包括着文件名、起始位置、长度和存储它的一组处事器地点。。。
当Map任务拿到所属的InputSplit后,就开始一条条读取记录,并挪用用于界说的Mapper ,举办计较(拜见MapRunner<K1, V1, K2, V2>和MapTask的run要领),然后,输出。 MapTask会通报给Mapper一个OutputCollector<K, V>工具,作为输出的数据布局。它 界说了一个collect的函数,接管一个键值对。在MapTask中,界说了两个OutputCollector的 子类,一个是MapTask.DirectMapOutputCollector<K, V>,人如其名,它的实现确实 很Direct,直截了当。它会操作一个RecordWriter<K, V>工具,collect一挪用,就直 接挪用RecordWriter<K, V>的write要领,写入当地的文件中去。假如觉着 RecordWriter<K, V>呈现的很突兀,那么看看上一段提到的RecordReader<K, V>,根基上,数据布局都是对应着的,一个是输入一个是输出。输出很对称也是由 RecordWriter<K, V>和OutputFormat<K, V>来协同完成的,其默认实现是 LineRecordWriter<K, V>和TextOutputFormat<K, V>,何等的眼熟啊。。。
除了这个很是直接的实现之外,MapTask中尚有一个巨大的多的实现,是 MapTask.MapOutputBuffer<K extends Object, V extends Object>。有道是简朴压倒 一切,那为什么有很简朴的实现,要琢磨一个巨大的呢。原因在于,看上去很美的往往带着 刺,简朴的输出实现,每挪用一次collect就写一次文件,频繁的硬盘操纵很有大概导致此方 案的低效。为了办理这个问题,这就有了这个巨大版本,它先开好一段内存做缓存,然后制 定一个比例做阈值,开一个线程监控此缓存。collect来的内容,先写到缓存中,当监控线程 发明缓存的内容比例高出阈值,挂起所有写入操纵,建一个新的文件,把缓存的内容批量刷 到此文件中去,清空缓存,从头开放,接管继承collect。。。
为什么说是刷到文件中去呢。因为这不是一个简朴的照本宣科简朴复制的进程,在写入之 前,会先将缓存中的内存,颠末排序、归并器(Combiner)统计之后,才会写入。假如你觉 得Combiner这个名词听着太生疏,那么思量一下Reducer,Combiner也就是一个Reducer类, 通过JobConf的setCombinerClass举办配置,在常用的设置中,Combiner往往就是用用户为 Reduce任务界说的谁人Reducer子类。只不外,Combiner只是处事的范畴更小一些罢了,它在 Map任务执行的处事器当地,依照Map处理惩罚过的那一小部门数据,先做一次Reduce操纵,这样 ,可以压缩需要传输内容的巨细,提高速度。每一次刷缓存,城市开一个新的文件,等此任 务所有的输入都处理惩罚完成后,就有了若干个有序的、颠末归并的输出文件。系统会将这些文 件搞在一起,再做一个多路的合并外排,同时利用归并器举办归并,最终,获得了独一的、 有序的、颠末归并的中间文件(注:文件数量等同于分类数量,在不思量分类的时候,简朴 的视为一个…)。它,就是Reduce任务求之不得的输入文件。。。
#p#分页标题#e#
除了做归并,巨大版本的OutputCollector,还具有分类的成果。分类,是通过 Partitioner<K2, V2>来界说的,默认实现是HashPartitioner<K2, V2>,功课 提交者可以通过JobConf的setPartitionerClass来自界说。分类的寄义是什么呢,简朴的说 ,就是将Map任务的输出,分别到若干个文件中(凡是与Reduce任务数目相等),使得每一个 Reduce任务,可以处理惩罚某一类文件。这样的长处是大大的,举一个例子说明一下。好比有一 个功课是举办单词统计的,其Map任务的中间功效应该是以单词为键,以单词数量为值的文件 。假如这时候只有一个Reduce任务,那还好说,从全部的Map任务哪里收集文件过来,别离统 计获得最后的输出文件就好。可是,假如单Reduce任务无法承载此负载或效率太低,就需要 多个Reduce任务并行执行。此时,再沿用之前的模式就有了问题。每个Reduce任务从一部门 Map任务哪里得到输入文件,但最终的输出功效并不正确,因为同一个单词大概在差异的 Reduce任务哪里都有统计,需要想要领把它们统计在一起才气得到最后功效,这样就没有将 Map/Reduce的浸染完全发挥出来。这时候,就需要用到分类。假如此时有两个Reduce任务, 那么将输出分成两类,一类存放字母表排序较高的单词,一类存放字母表排序低的单词,每 一个Reduce任务从所有的Map任务哪里获取一类的中间文件,获得本身的输出功效。最终的结 果,只需要把各个Reduce任务输出的,拼接在一起就可以了。本质上,这就是将Reduce任务 的输入,由垂直支解,酿成了程度支解。Partitioner的浸染,正是接管一个键值,返回一个 分类的序号。它会在从缓存刷到文件之前做这个事情,其实只是多了一个文件名的选择罢了 ,此外逻辑都不需要变革。。。
除了缓存、归并、分类等附加事情之外,巨大版本的OutputCollector还支持错误数据的 跳过成果,在后头漫衍式将排错的时候,还会提及,标志一下,按下不表。。。
V. Reduce任务详情
理论上看,Reduce任务的整个执行流程要比Map任务更为的罗嗦一些,因为,它需要收集 输入文件,然后才气举办处理惩罚。Reduce任务,主要有这么三个步调:Copy、Sort、Reduce( 拜见ReduceTask的run要领)。所谓Copy,就是从执行各个Map任务的处事器哪里,采集到本 地来。拷贝的任务,是由ReduceTask.ReduceCopier类来认真,它有一个内嵌类,叫 MapOutputCopier,它会在一个单独的线程内,认真某个Map任务处事器上文件的拷贝事情。 长途拷贝过来的内容(虽然也可以是当地了…),作为MapOutput工具存在,它可以在内存 中也可以序列化在磁盘上,这个按照内存利用状况来自动调理。整个拷贝进程是一个动态的 进程,也就是说它不是一次给好所有输入信息就不再变革了。它会不断的挪用 TaskUmbilicalProtocol协议的getMapCompletionEvents要领,向其父TaskTracker询问此作 业个Map任务的完成状况(TaskTracker要向JobTracker询问后再转告给它…)。当获取到相 关Map任务执行处事器的信息后,城市有一个线程开启,做详细的拷贝事情。同时,尚有一个 内存Merger线程和一个文件Merger线程在同步事情,它们将新鲜下载过来的文件(大概在内 存中,简朴的统称为文件…),做着合并排序,以此,节省时间,低落输入文件的数量,为 后续的排序事情减负。。。
Sort,排序事情,就相当于上述排序事情的一个延续。它会在所有的文件都拷贝完毕后进 行,因为固然同步有做着合并的事情,但大概留着尾巴,没做彻底。颠末这一个流程,该彻 底的都彻底了,一个崭新的、归并了所有所需Map任务输出文件的新文件,降生了。而那些千 行万苦从其他各个处事器网罗过来的Map任务输出文件,很快的竣事了它们的汗青使命,被扫 地出门一扫而光,全部删除了。。。
所谓好戏在背面,Reduce任务的最后一个阶段,正是Reduce自己。它也会筹备一个 OutputCollector收集输出,与MapTask差异,这个OutputCollector更为简朴,仅仅是打开一 个RecordWriter,collect一次,write一次。最大的差异在于,这次传入RecordWriter的文 件系统,根基都是漫衍式文件系统,可能说是HDFS。而在输入方面,ReduceTask会从JobConf 哪里挪用一堆getMapOutputKeyClass、getMapOutputValueClass、getOutputKeyComparator 等等之类的自界说类,结构出Reducer所需的键范例,和值的迭代范例Iterator(一个键到了 这里一般是对应一组值)。详细实现颇为含血喷人,发起看一下Merger.MergeQueue, RawKeyValueIterator,ReduceTask.ReduceValuesIterator等等之类的实现。有了输入,有 了输出,不绝轮回挪用自界说的Reducer,最终,Reduce阶段完成。。。
VI. 漫衍式支持
1、处事器正确性担保
#p#分页标题#e#
Hadoop Map/Reduce处事器状况和HDFS很雷同,由此可知,救死扶伤的要领也是大同小异 。空话不多说了,直接切正题。同作为客户端,Map/Reduce的客户端只是将功课提交,就开 始搬个板凳看戏,没有占茅坑的动作。因此,一旦它挂了,也就挂了,不感冒雅。而任务服 务器,也需要随时与功课处事器保持心跳接洽,一旦有了问题,功课处事器可以将其上运行 的任务,移交给它人完成。功课处事器,作为一个单点,很是雷同的是操作还原点(等同于 HDFS的镜像)和汗青记录(等同于HDFS的日志),来举办规复。其上,需要耐久化用于规复 的内容,包括功课状况、任务状况、各个任务实验的事情状况等。有了这些内容,再加上任 务处事器的动态注册,就算挪了个窝,照旧很容易规复的。JobHistory是汗青记录相关的一 个静态类,原来,它也就是一个干写日志活的,只是在Hadoop的实现中,对日志的写入做了 面向工具的封装,同时又大量用到调查者模式做了些嵌入,使得看起来不是那么直观。本质 上,它就是打开若干个日志文件,操作种种接口交往内里写内容。只不外,这些日志,会放 在漫衍式文件系统中,就不需要像HDFS那样,来一个SecondXXX随时候命,由此可见,有巨人 在脚下踩着,真好。JobTracker.RecoveryManager类是功课处事器顶用于举办规复相关的事 情,看成业处事器启动的时候,会挪用其recover要领,规复日志文件中的内容。个中步调, 注释中写的很清楚,请自行查察。。。
2、任务执行的正确和速度
整个功课流程的执行,承袭着木桶道理。执行的最慢的Map任务和Reduce任务,抉择了系 统整体执行时间(虽然,假如执行时间在整个流程中占比例很小的话,也许就微不敷道了… )。因此,只管加速最慢的任务执行速度,成为提高整体速度要害。所利用的计策,简约而 不简朴,就是一个任务多次执行。当所有未执行的任务都分派出去了,而且先富起来的那部 分任务已经完成了,并尚有任务处事器孜孜不倦的索取任务的时候,功课处事器会开始炒剩 饭,把那些正在吭哧吭哧在某个处事器上逐步执行的任务,再把此任务分派到一个新的任务 处事器上,同时执行。两个处事器各尽其力,成王败寇,先竣事者的功效将被采用。这样的 计策,隐含着一个假设,就是我们相信,输入文件的支解算法是公正的,某个任务执行慢, 并不是由于这个任务自己承担太重,而是由于处事器不争气承担太重本领有限可能是即将撒 手西去,给它换个新情况,人挪死树挪活事半功倍。。。
虽然,必定有哽咽的任务,岂论是在哪个处事器上,都无法顺利完成。这就说明,此问题 不在于处事器上,而是任务自己天资有缺憾。缺憾在那里?每个功课,成果代码都是一样的 ,此外任务乐成了,就是这个任务不乐成,很显然,问题出在输入哪里。输入中有犯科的输 入条目,导致措施无法辨识,只能洒泪惜别。说到这里,办理计策也浮出水面了,三十六计 走位上,惹不起,照旧躲得起的。在MapTask中的MapTask.SkippingRecordReader<K, V>和ReduceTask里的ReduceTask.SkippingReduceValuesIterator<KEY,VALUE>,都 是用于干这个工作的。它们的道理很简朴,就是在读一笔记录前,把当前的位置信息,封装 成SortedRanges.Range工具,经过Task的reportNextRecordRange要领提交到TaskTracker上 去。TaskTracker会把这些内容,搁在TaskStatus工具中,跟着心跳动静,讲述到JobTracker 上面。这样,功课处事器就可以随时随刻相识清楚,每个任务正读取在谁人位置,一旦堕落 ,再次执行的时候,就在分派的任务信息内里添加一组SortedRanges信息。MapTask或 ReduceTask读取的时候,会看一下这些区域,假如当前区域正长处于上述雷区,跳过不读。 如此重复,正可谓,阶梯曲折,前途光亮啊。。。
VII. 总结
对付Map/Reduce而言,真正的坚苦,在于提高其适应本领,打造一款可以或许包治百病的执行 框架。Hadoop已经做得很好了,但只有真正搞清楚了整个流程,你才气辅佐它做的更好。
