可设置语法阐明器开拓纪事(四) 结构一个真正能用的状态机(上)
副标题#e#
原来说这一篇文章要把结构确定性状态机和look ahead讲完的,当我真正要写的时候发明对象太多,只好分成两篇了。上一篇文章说道一个根基的状态机是如何结构出来的,可是按照第一篇文章的说法,这一次设计的文法是为了直接结构出语法树处事的,所以一定在执行状态机的时候就要得到结构语法树的一切信息。假如本身开拓过雷同的对象就会知道,雷同LALR这种对象,你可以很容易的把整个字符串阐明完判定他是不是属于这个LALR状态机描写的这个荟萃,可是你却不能拿到语法阐明所走的路径,也就是说你很难直接拿到那颗阐明树。没有阐明树必定是做不出语法树的。因此我们得把一些信息插入到状态机内里,才气最终把阐明树(并不必然真的要表告竣树,像上一篇文章的“阐明路径”(其实就是阐明树的一种大概的表达形式)所确定的语法树结构出来。
就像《结构正则表达式引擎》一般给状态机添加信息的要领,就是把一些附加的数据加到状态与状态之间的跳转箭头内里去。为了形象的表达这个工作,我就拿第一篇文章的四则运算式子来举例。在这里我为了各人利便,反复一下这个文法的内容(撤除了语树书声明):
token NAME = "[a-zA-Z_]/w*";
token NUMBER = "/d+(./d+)";
token ADD = "/+";
token SUB = "-";
token MUL = "/*";
token DIV = "//";
token LEFT = "/(";
token RIGHT = "/)";
token COMMA = ",";
rule NumberExpression Number
= NUMBER : value;
rule FunctionExpression Call
= NAME : functionName "(" [ Exp : arguments { "," Exp : arguments } ] ")";
rule Expression Factor
= !Number | !Call;
rule Expression Term
= !Factor;
= Term : firstOperand "*" Factor : secondOperand as BinaryExpression with { binaryOperator = "Mul" };
= Term : firstOperand "/" Factor : secondOperand as BinaryExpression with { binaryOperator = "Div" };
rule Expression Exp
= !Term;
= Exp : firstOperand "+" Term : secondOperand as BinaryExpression with { binaryOperator = "Add" };
= Exp : firstOperand "-" Term : secondOperand as BinaryExpression with { binaryOperator = "Sub" };
那么我们把这个文发转成状态机之后,要给跳转加上什么呢?从直觉上来说,跳转的时候我们会有六种要干的工作:
1、Create:这个文法建设的语法树节点是某个范例的(区别于在这一刻给这个问法建设一个返回什么范例的语法树节点)
2、Set:给建设的语法树节点的某个成员变量配置一个指定的值
3、Assign:给建设的语法树节点的某个成员变量配置这一次跳转的标记发生的语法树节点(譬如说Exp = Exp: firstOperand “+” Term: secondOperand,走Term的时候,一个语法树节点就会被assign给谁人叫做secondOperand的成员变量)
4、Using:利用这一次跳转的标记发生的语法树节点来做这次文法的返回值(譬如说Factor = !Number | !Caller这一条)
5、Shift:略
6、Reduce:略
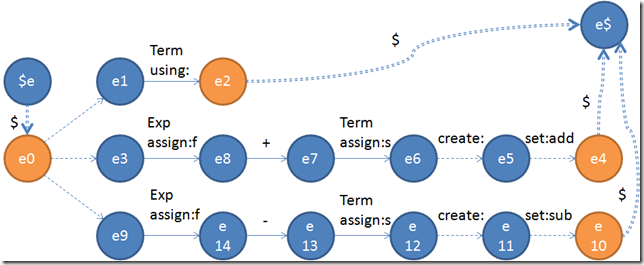
在这里我们并没有标志整个文法从哪一个非终结符开始,因为在实际进程中,其实阐明师可以从任何一个文法开始的。譬如说写IDE的时候,我们大概在某些环境下仅仅只需要阐明一个表达式。所以思量到每一个非终结符都有大概被用到,因此我们的“Token流开始”和“Token流竣事”就会在每一个非终结符的状态机中都呈现。因此在第一步建设Epsilon PDA(下推自念头)的时候,就可以先直接生成。在这里我们拿Exp做例子:
本栏目
双虚线代表的是Token流和Token流竣事,这并不是我们此刻体贴的工作。在剩下的转换中,实现是具有输入的转换,而虚线则是没有输入的转换(一般称为epsilon边)。
在这里我们要明晰一个观念——阐明路径。阐明路径代表的是token在“流”过状态机的时候,状态是如何跳转的。因此对付实际的阐明进程,阐明路径其实就是阐明树的一种表达形式。而在状态机内里,阐明路径则代表一条从开始到末了的大概的路径。譬如说在这里,阐明路径可以有三条:
$e –> e1 –> e2 –> e$
$e –> e3 –> e8 –> e7 –> e6 –> e5 –> e4 –> e$
$e –> e9 –> e14 –> e13 –> e12 –> e11 –> e10 –> e$
因此我们可以清楚,一条路径上是不能呈现多个create的,不然你就不知道应该建设的是什么了。虽然create和using都不能同时呈现,using也不能有多个。并且由于create和set都是在描写这个非终结符(在这里是Exp)所建设的语法树节点的范例和属性,跟执行他们的机缘无关,所以其实在同一条阐明路径内里,create和set放在那边都不要紧。就譬如说在上面的第二条阐明路径内里,create是在e6->e5内里标志出来的。就算他移动到了e3->e8,做的工作也一样。横竖只要一条路径上标志了create,那么他在这条路径被确定之后,就必然会create所指定的详细范例的语法树节点。这是相当重要的,因为在后头的阐明中,我们很大概需要移动create和set的详细位置。
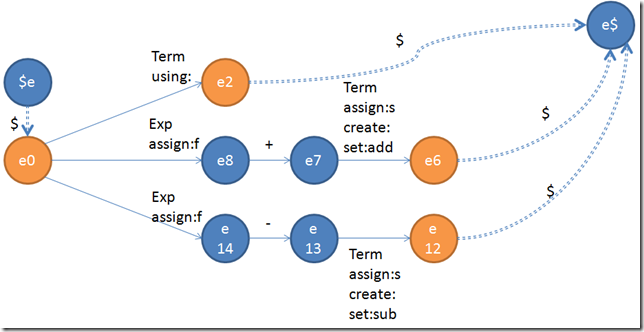
跟上一篇文章说的一样,接下来的一步就是去除epsilon边了。功效如下:
#p#副标题#e#
#p#分页标题#e#
面临这种状态机,去除epsilon边就不能跟处理惩罚正则表达式一样简朴的去除了。首先,所有的终结状态——也就是所有颠末可能不颠末epsilon边之后,通过“Token流竣事”标记毗连到最后一个状态的状态,在这里别离是e2、e6和e12——都是不能删掉的。并且所有的“Token流开始”和“Token流竣事”——也就是图内里的$转换——是不能带有信息的。所以我们就会看到e6后头的信息全部被移动到了e7->e6这条边上面。由于create和set的活动性,我们这么做对付状态机的界说完全没有影响。
到了这里还没完,因为这个状态机照旧有许多冗余的状态的。譬如说e8和e14、e7和e13、e2和e6和e12实际上是可以归并的。归并的计策其实十分简朴:
1、假如我们有跳转e0->e1和e0->e2,而且两个跳转所携带的token输入和信息完全一致的话,那么e1和e2就可以归并。
2、假如我们有跳转e1->e0和e2->e0,而且两个跳转所携带的token输入和信息完全一致的话,那么e1和e2就可以归并。
所以对付e8和e14我们是完全可以归并的。那么e7和e13怎么办呢?按照create和set的活动性,我们只要把这两个对象挪到他的前面一个可能若干个跳转去,那这两个状态就可以归并了。为了让算法越发的简朴,我们碰着两个跳转雷同的时候,老是先挪动create和set,然后再看看是不是真的可以归并。所以这一步处理惩罚完之后就会酿成下面这个样子:
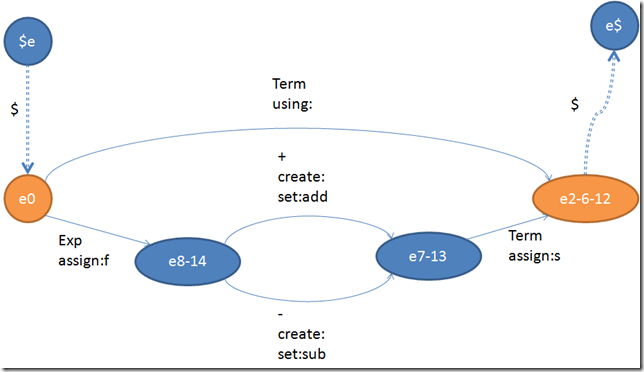
我们在不改变状态机语义的环境下,把Exp的三个状态机最终压缩成了这个样子。看过上一篇文章的同学们都知道,下一步就是要把所有的状态机统统都毗连起来了。关于在毗连的时候如何详细操纵转换附带的信息、以及做出一个确定性的下推状态机的所有工作将在下一篇文章具体表明。
