从Google开源RE2库进修到的C++测试方案
副标题#e#
最近因为科研需求,一直在研究Google的开源RE2库(正则表达式识别库),库源码体积复杂,用C++写的,对付我这个以前专供Java的人来说真的是一件很疾苦的事,天天只能啃一点点。本日研究了下内里用到的测试要领,感受挺好的,拿来跟各人分享下!(哈~C++大牛勿喷)
对付我这个C++菜鸟中的菜鸟而言,平时写几个函数想要测试一般都是在main中一个一个的测试,因为没用C++写过项目,没有N多要领所以在main中一个个测试也不费劲。可是对付一个项目而言,或多或少都有N多要领,假如在main中一个个测试的话,不只效率低并且还容易堕落漏掉什么的。那么该怎么举办测试呢?貌似此刻有许多C++自动化测试的东西,横竖我是一个没用过,也没法评价。我就说下Google在RE2库里是怎么测试的吧。
先用一个超等简朴的例子来做讲授:测试两个要领getAsciiNum()和getNonAsciiNum(),别离求flow中ASCII码字符的数目和非ASCII码字符的数目。
第一步:写个头文件,界说测试所用类和测试要领。
// test.h
#define TEST(x, y) \
void x##y(void); \
TestRegisterer r##x##y(x##y, # x "." # y); \
void x##y(void)
void RegisterTest(void (*)(void), const char*);
class TestRegisterer {
public:
TestRegisterer(void (*fn)(void), const char *s) {
RegisterTest(fn, s);
}
};
理会:首先看界说的类TestRegisterer,有个结构要领,两个参数:
1. 一个函数指针:void (*fn)(void),指向我们详细要编写的测试要领名;
2. 一个字符串:constchar *s,属于该测试要领的描写信息。
这个结构函数挪用了另一个函数RegisterTest(),详细实现见下面。
然后看最上面界说的宏TEST(x, y),主要将其替换为TestRegisterer r##x##y(x##y, # x"." # y);个中x##y作为要领名,# x"." # y作为描写信息。这里大概有些和我一样入门级此外人没怎么看懂这个宏,因为不知道前后加void x##y(void);这个是干嘛用的?一开始我也没想大白,因为不加的话就会报错,厥后通过gcc的-E选项激活宏编译,看了下编译期间展开成啥容貌了。这里以一个简朴的例子作为说明:假设x为test,y为flow,假如不加前后谁人,那么展开后为TestRegisterer rtestflow(testflow, "test.flow"); 这明明是个函数声明,有两个参数,第二个是字符串,那么第一个是什么?编译器会认为是个函数名(实际上也是的),但这个函数前面明明未界说,就会报找不到此函数声明的错误,所以就需要在之前加上void x##y(void);声明函数,虽然光声明不实此刻链接时同样报错,所以就需要在之后加上void x##y(void)举办详细实现了,留意这里没有逗号,也没有详细实现的{},因为这只是宏,Google的所有测试函数是这样写的:
TEST(x, y) {
.... // 详细实现
}
那么上面例子TEST(test, flow){ … // 详细实现 },整体展开后就是这样:
void testflow(void);
TestRegisterer rtestflow(testflow, "test.flow");
void testflow(void) {
.... // 详细实现
}
#p#副标题#e#
第二步:N多个详细的测试实现。
01.#include <string>
02.#include <vector>
03.#include "test.h"
04.
05.#define arraysize(array) (sizeof(array)/sizeof((array)[0]))
06.#define CHECK_EQ(x, y) if((x) != (y)) { printf("test failed!\n"); system("pause"); exit(0); }
07.
08.struct TestFlow {
09. const char* flow;
10. const int num;
11.};
12.
13.static struct TestFlow tests1[] = {
14. {"\x02\x97\xa4\xe6\xfe\x0c", 2},
15. {"\x05\x97\x35\xe6\xfe\xac\x04", 3},
16. {"\xb2\x97\xa5\xe6\x9c\x1c\x58\xaa\x97\x03", 3},
17. {"\x32\x97\xa5\x05\x9c\xac\xe8\xaa\x57", 3},
18. {"\x42\x01\xa5\x86\x0c\x56\xe8\xaa\x97\x03", 5},
19.};
20.
21.static struct TestFlow tests2[] = {
22. {"\x02\x97\xa4\xe6\xfe\x0c", 4},
23. {"\x05\x97\x35\xe6\xfe\xac\x04", 4},
24. {"\xb2\x97\xa5\xe6\x9c\x1c\x58\xaa\x97\x03", 7},
25. {"\x32\x97\xa5\x05\x9c\xac\xe8\xaa\x57", 6},
26. {"\x42\x01\xa5\x86\x0c\x56\xe8\xaa\x97\x03", 5},
27.};
28.
29.int getAsciiNum(const char*);
30.int getNonAsciiNum(const char*);
31.
32.TEST(TestAsciiNum, Simple) {
33. int failed = 0;
34. for (int i = 0; i < arraysize(tests1); i++) {
35. const TestFlow& t = tests1[i];
36. int num = getAsciiNum(t.flow);
37. if (num != t.num) {
38. failed++;
39. }
40. }
41. CHECK_EQ(failed, 0);
42.}
43.
44.TEST(TestNonAsciiNum, Simple) {
45. int failed = 0;
46. for (int i = 0; i < arraysize(tests2); i++) {
47. const TestFlow& t = tests2[i];
48. int num = getNonAsciiNum(t.flow);
49. if (num != t.num) {
50. failed++;
51. }
52. }
53. CHECK_EQ(failed, 0);
54.}
55.
56.int getAsciiNum(const char* flow) {
57. // we assume that there's no \x00 in flow otherwise we cannot use strlen()
58. int num = 0, i;
59.
60. for(i = 0; i < strlen(flow); i++) {
61. // ASCII: 0 ~ 127
62. if(flow[i] >= 0 && flow[i] < 128)
63. num++;
64. }
65.
66. return num;
67.}
68.
69.int getNonAsciiNum(const char* flow) {
70. // we assume that there's no \x00 in flow otherwise we cannot use strlen()
71. int num = 0, i;
72. for(i = 0; i < strlen(flow); i++) {
73. // ASCII: 0 ~ 127
74. if(flow[i] < 0 || flow[i] >= 128)
75. num++;
76. }
77.
78. return num;
79.}
看上去一目了然,TEST(TestAsciiNum, Simple)和TEST(TestNonAsciiNum, Simple)就是两个详细的测试实现了,这个例子很简朴,仅仅是为了说明问题。
#p#分页标题#e#
第三步:详细的测试方案。
// test.cpp
#include <stdio.h>
#include <stdlib.h>
#include "test.h"
struct Test {
void (*fn)(void);
const char *name;
};
static Test tests[10000];
static int ntests;
void RegisterTest(void (*fn)(void), const char *name) {
tests[ntests].fn = fn;
tests[ntests++].name = name;
}
int main(int argc, char **argv) {
for (int i = 0; i < ntests; i++) {
printf("%s\n", tests[i].name);
tests[i].fn();
}
printf("PASS\n");
system("pause");
return 0;
}
理会:
1. 布局体Test存储详细的测试实现,界说最多能有10000个差异的要领测试,也就是能同时测试10000个要领。
2. ntests代表实际所测试的要领数,我这里就是2了。
3. RegisterTest()详细的实现也较量简朴,就是将实际所要测试的要领名和描写信息存储到Test布局体数组tests中。
4. 最后就是在main中举办统一测试了,首先输出测试要领描写信息,以便知道当前测试了哪些要领及假如有测试失败时能实时举办排查。然后就是详细的执行测试函数了。
本例的测试功效如下:
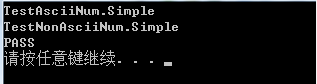
思考:下面看下详细是如何执行的:
各人大概以为main写的太简捷,一开始什么都没挪用,直接来个for轮回,ntests的值初始不是0吗?在main一开始也没显式的挪用RegisterTest()将测试要领加进去啊,怎么一进入main,ntests就酿成2了?
各人要记着:所有的测试详细实现都是在TEST这个宏内里,而宏是在编译期间就开始展开了。以 TEST(TestAsciiNum, Simple){ … }为例,详细的执行进程如下:
编译期间:
TEST(TestAsciiNum, Simple)展开为:
void TestAsciiNumSimple(void);
TestRegisterer rTestAsciiNumSimple(TestAsciiNumSimple, "TestAsciiNum.Simple");
void TestAsciiNumSimple(void) {
int failed = 0;
for (int i = 0; i < arraysize(tests1); i++) {
const TestFlow& t = tests1[i];
int num = getAsciiNum(t.flow);
if (num != t.num) {
failed++;
}
}
CHECK_EQ(failed, 0);
}
然后就触发挪用了TestRegisterer的结构要领从而开始执行RegisterTest(TestAsciiNumSimple,"TestAsciiNum.Simple")要领,将TestAsciiNumSimple要领名和描写信息"TestAsciiNum.Simple"插手到布局体数组tests中,这时ntests增为1,同理另一个宏TEST(TestNonAsciiNum, Simple)展开后也将TestAsciiNonNumSimple要领名和描写信息"TestNonAsciiNum.Simple"插手到布局体数组tests中,这时ntests增为2,这是编译期间做的事。
运行期间:
从main开始,执行for轮回,先后执行了详细的测试实现要领TestAsciiNumSimple()和TestAsciiNonNumSimple()从而完成测试。
用一个图来说明越发清晰(图画的不太好,望留情~~~)
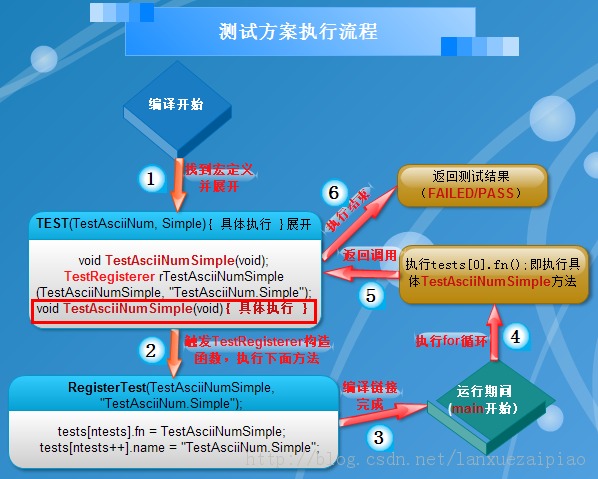
作者:csdn博客 lanxuezaipiao
