关于Oracle性能调整与优化的讲解
不经意间我们又来到了oracle系统文章的学习,在众多学习中,我们的文章也许不起眼,但是想必大家都有很多问题吧,所以重要的下面我们就来讲解一下,大家一定要认真看奥!!
【51CTO快译】为了能取得**成功,我将涉及到一些预备步骤,它们将在查看发生了什么时需要,这些步骤包括运行plustrce SQL脚本、创建一个“EXPLAIN_PLAN”表、授予角色、配置sql*plus环境查看执行计划。所有这些步骤都包括在“Oracle 9i R2数据库性能调整指南和参考”中“在sql*plus中使用自动跟踪”,对于Oracle 10g,这些步骤包括在“sql*plus用户指南和参考10.2版”中“调整sql*plus”。
预备步骤
如果角色PLUSTRACE不存在,用ORACLE_HOME\\sqlplus\\admin目录下的PLUSTRCE SQL脚本来创建它,这个脚本相当简单:
drop role plustrace; create role plustrace; grant select on v_$sesstat to plustrace; grant select on v_$statname to plustrace; grant select on v_$mystat to plustrace; grant plustrace to dba with admin option; |
检查角色使用情况:
SQL> select role from dba_roles where role = 'PLUSTRACE'; ROLE ---------------- PLUSTRACE |
用户必须有(或有权限访问)一个PLAN_TABLE(它可以被命名为其他名字,但是默认的名字非常好),这个表是用ORACLE_HOME\\rdbms\\admin目录下的UTLXPLAN SQL脚本创建的。
SQL> show user USER is "SYSTEM" SQL> @?\\rdbms\\admin\\utlxplan Table created. SQL> create public synonym plan_table for system.plan_table; Synonym created. SQL> grant select, update, insert, delete on plan_table to <你的用户名>; Grant succeeded. SQL> grant plustrace to <你的用户名>; Grant succeeded. |
我们的例子中使用的用户是HR(可以在Oracle提供的样本方案中找到)。
SQL> conn hr/hr Connected. SQL> set autotrace on SQL> select * from dual; D - X |
因为autotrace被设置为on,你将能够看到执行计划和一些统计信息,你看到的输出应该与下面的内容类似:
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=2 Card=1 Bytes=2) 1 0 TABLE Access (FULL) OF 'DUAL' (TABLE) (Cost=2 Card=1 Bytes=2) Statistics ---------------------------------------------------------- 24 recursive calls 0 db block gets 6 consistent gets 1 physical reads 0 redo size 389 bytes sent via SQL*Net to client 508 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed |
要取消查询结果,在set语句中使用“traceonly”。
使用绑定变量
在任何DBA帮助类型的网站上,常常会看到一点使用绑定变量的建议,但是步骤或包括在这些步骤中的指令很少,这里有一个创建和使用绑定变量的简单方法。
SQL> vaRIAble department_id number SQL> begin 2 :department_id := 80; 3 end; 4 / PL/SQL procedure successfully completed. SQL> print department_id DEPARTMENT_ID ------------- 80 |
现在我们对使用和不使用绑定变量查询雇员id两种情况做一下比较(使用traceonly关闭输出)。
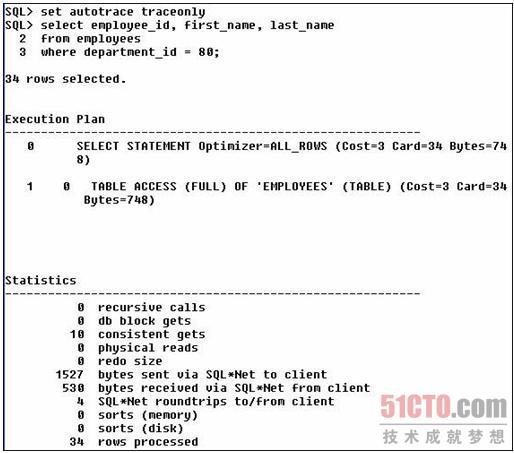
现在让我们使用绑定变量:oracle教学视频
Oracle WDP 全称为Oracle Workforce Development Program,是Oracle (甲骨文)公司专门面向学生、个人、在职人员等群体开设的职业发展力课程。在成熟的资本市场,市值是衡量一家企业规模、利润及增长状况等综合竞争力的动态结果。根据金融时报1月公布的2010年末全球市值500强的数据,苹果首次夺得了全球IT业市值的年终榜首。能够进入市值十强的公司,都是令人尊敬的IT顶尖企业,以市值顺序排列,这十家企业是苹果、微软、IBM、甲骨文、谷歌、三星电子、英特尔、思科、惠普和亚马逊。
Oracle的技术广泛应用于各行各业,其中电信、电力、金融、政府及大量制造业都需要Oracle技术人才,Oracle公司针对职业教育市场在全球推广的项目,其以低廉的成本给这部分人群提供Oracle技术培训,经过系统化的实训,让这部分人群能够迅速掌握Oracle最新的核心技术,并能胜任企业大型数据库管理、维护、开发工作。
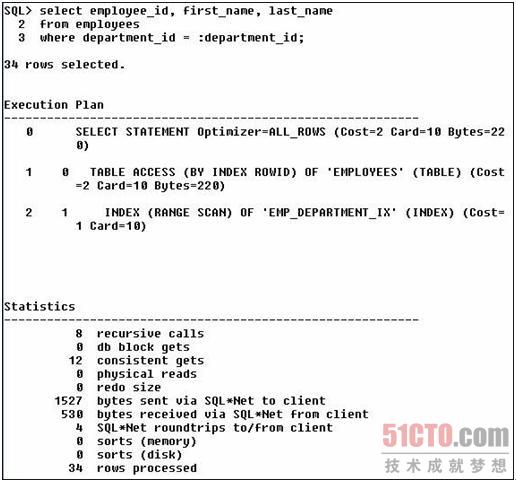
ok!区别不是太大(cost从3变为2),但这是一个小例子(表只有107行),当工作在一个更大的表上会有更多区别吗?使用SH方案,它的SALES表有超过900,000行数据。
SQL> select prod_id, count(prod_id) 2 from sales 3 where prod_id > 130 4 group by prod_id; |

同样的查询,但这次使用一个绑定变量:
SQL> variable prod_id number SQL> begin 2 :prod_id := 130; 3 end; 4 / PL/SQL procedure successfully completed. SQL> print prod_id PROD_ID ---------- 130 SQL> select prod_id, count(prod_id) 2 from sales 3 where prod_id > :prod_id 4 group by prod_id; |

cost从540变为33了,这一下就显得十分明显了,其中最主要的受益是使用绑定变量的查询,你要做的就是为这个变量替换一个新值。
使用效率高的SQL
假设你在下面的两个查询中做一个选择(再次使用HR方案):
查询1
select d.department_id, d.department_name, r.region_name from departments d, locations l, countries c, regions r where d.location_id=l.location_id and l.country_id=c.country_id and c.region_id=r.region_id; |
和
select department_id, department_name, region_name from departments natural join locations natural join countries natural join regions; |
这产生了四个问题。oracle视频教程
1、这些查询的查询结果集一致吗?
2、如果它们是一致的,你能预计在它们的执行计划中有什么不同吗?
3、如果这些执行计划一致,是什么使得这些查询不同?
4、能做些什么事情来改善成本(cost)?
第一个问题的答案是“是”,它们的查询结果集是一致的;第二个问题的答案是“不能”,因为相同的步骤是连接表;第三个问题的答案需要处理输入的数量或涉及的编码。
在这个例子中关键词“自然连接(natural join)”,“join on”,“左/右 外连接(right/left outer join)”的使用是怎么回事,如果你懂得什么是自然连接(仍然连接两个表,但是涉及到的列名是相同的),看起来使用第二个查询不是更容易了吗?
下面展示的是验证第二个问题的答案。
查询1的执行计划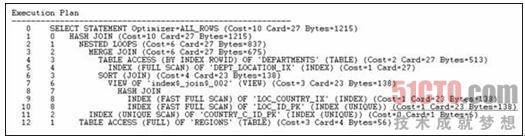
查询2的执行计划
至于最后一个问题的答案,效率高的SQL对不同的人可能意思不一样,在本例中,使用一个视图怎么样?这样与最初的查询在成本上有何不同,或有其他需要考虑的事情吗?
假设我有一个名叫cost_example的视图,创建语句如下:
create or replace view cost_example as select department_id, department_name, region_name from departments natural join locations natural join countries natural join regions; |
让我们在视图中查看一条记录
SQL> select department_id, department_name, region_name 2 from cost_example 3 where department_id=70; DEPARTMENT_ID DEPARTMENT_NAME REGION_NAME ------------- ------------------------------ ------------ 70 Public Relations Europe |
输出三列或字段,它们能够被改动吗?如果可以,为什么?如果不可以,为什么不可以?
我们假设现在用Asia代替REGION_NAME的值Europe
SQL> update cost_example 2 set region_name = 'Asia' 3 where region_name = 'Europe'; set region_name = 'Asia' * ERROR at line 2: ORA-01779: cannot modify a column which maps to a non key-preserved table |
DEPARTMENT_NAME字段的值能被修改吗?
SQL> update cost_example 2 set department_name = 'PR' 3 where department_name = 'Public Relations'; 1 row updated. |
为什么在视图中的记录能被更新的原因是departments表是一个关键保护表(它的主键DEPARTMENT_ID用于视图的创建了)。
这个例子的要点是:仅仅因为你获得了低成本并不意味着你就不能再为查询优化做其他的事情了,使用单一连接结构适用于开发者,视图适用于用户。
小结
本文的主要观点是:
·使用绑定变量
·使用效率高的SQL
·使用编码标准
·创建适当的视图
这些步骤没有哪个在执行或实现起来特别困难,因为程序员常常使用”tableA.column_name = tableB.column_name”的格式来连接,转移到使用自然连接节约相当多的输入,加上受益于关键列名相配(在子表中的外键列与父表中的主键有相同的列名),如展示的那样,某些量度可能没有大的影响,但是当当作为一个整体时,每一个小的都对改善性能有帮助,在第3部分中,我们将查看更多的例子。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
原文名:Oracle Performance Tuning – Part 2 作者:Steve Callan
小主们看完我们的文章,想必一定对我们文章很感兴趣了吧,若大家想了解更多视频课程文章的课程,亲们可以到课课家官网查看。非常真诚地欢迎大家,偶在等你们哟,快来吧!!!
