mysql中如何进行limit和join的优化?
在MySQL数据库中有一个很重要的优化方案,就是limit与join的实际优化方案,今天给大家讲解具体的实际应用中如何实操limit与join的实际优化方案。

我们今天主要和大家讨论的是Mysql数据库下limit与join的实际优化方案,如果你对其具体的实际操作感兴趣的话,你就可以点击以下的文章了。
以下的文章主要描述的是MySQL数据库下limit与join的实际优化方案,我们大家都知道其在实际中的应用比例还是占为多数的,如果你对这一技术,心存好奇的话,以下的文章将会揭开它的神秘面纱。
php中分页肯定会使用到MySQL的limit,大部分对类似”select*fromtitlewhereuid=**orderbyiddesclimitm,n”很熟悉,也不是全部都能看出里面有什么不对,可是当是在大数据量下操作呢,比如类似”select*fromtitlewhereuid=177orderbyiddesclimit1234567,20″就会发现sql执行的时间明显变得很长,为什么呢?
先从MySQL数据库的limit原理说起,使用limitm,n是时候,MySQL先扫描(m+n)条记录,然后从m行开始取n行.比如上面的例子就是先扫描1234587条数据,这样的话sql能快吗?这就要求我们尽可能的减少m的值,甚至没有m直接limitn这样是sql.
看个例子:
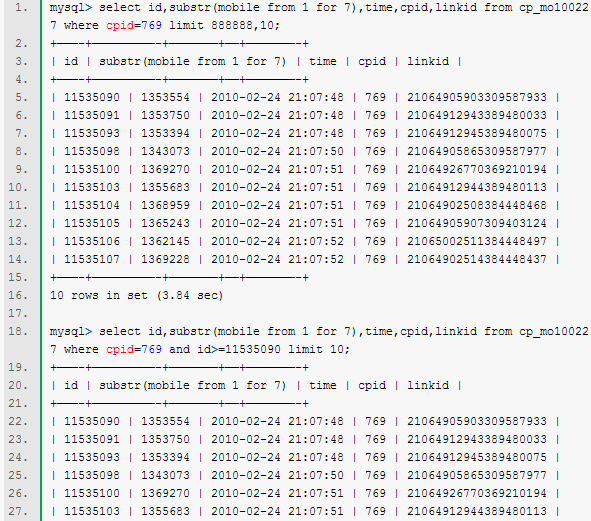
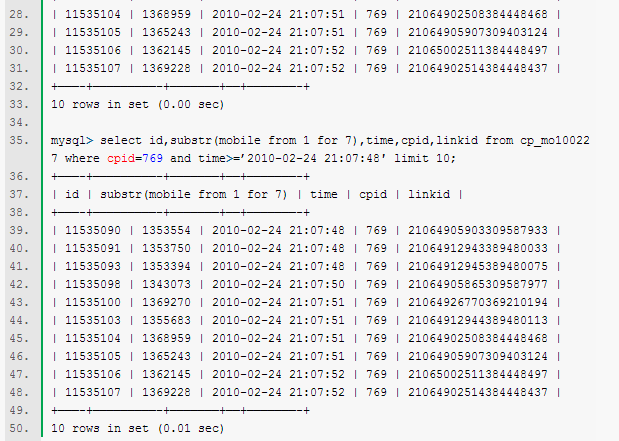
例中数据表id是主键,time也建了索引,表中总数据约为240w行,其中cpid为769的数据量大约为90w条.这里面的id和时间可能会是不连续的.故不能直接得获取id>m这样操作
所以可以显示“1,2,3,4,5,末页”或是“首页,<<100,101,102,103>>末页”这样,这样可以极大的减少m值!
MySQL里面的join顺便说一句就是,通常有点讲究的是用小表去驱动大表,而由于MySQLjoin实现的原理就是做循环比如leftjoin就是对左边的数据进行循环去驱动右边的表,比如左边是可能会有m条记录匹配,右边有n条记录那么就是做m次循环,每次扫描n行数据,总扫面行数是m*n行数据.左边返回的结果集的大小就决定了循环的次数,故单纯的用小表去驱动大表不一定的正确的。
小表的结果集可能也大于大表的结果集,所以写join的时候尽可能的先估计两张表的可能结果集,用小结果集去驱动大结果集.值得注意的是在使用left/rightjoin的时候,从表的条件应写在on之后,主表应写在where之后.否则MySQL数据库会当作普通的连表查询!
我们通过例子将limit与join的区别讲解了一遍,而且还具体的告诉了大家如何优化,希望大家在实际应用中多多体会。
