字符集与乱码
现在,随着计算机的不断发展以及越来越普及,计算机世界的字符编码集就变得越来越大以及越来越复杂,今天小编就从编码发展的源头入手,给大家详细解释乱码为什么会出现。
(一)字符编码简史
注意:以下有的内容是来自网络的,但内容十分有趣,相信大家看完这一段,就会对计算机字符编码发展史有一个新的认识。
(1)字节与计算机的出现
很久以前,有一群人决定用8个能够开合的晶体管组合成不一样的状态来表示世界万物。他们看到8个开关状态是好的,所以就把它们称为”字节”;
然后,他们又做了可以处理这些字节的一些机器,机器开动就能用字节组合出许多状态,状态就变来变去。他们看到这样是好的,就把机器称为”计算机”;
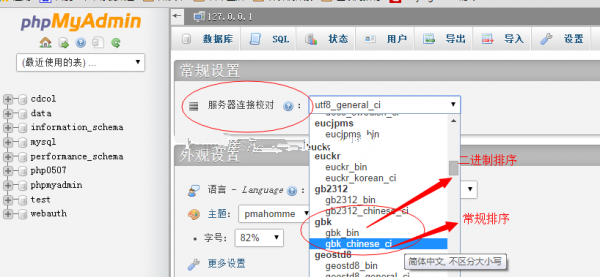
(2)ASCII编码的诞生
一开始,计算机只在美国使用,八位字节能够组合出256,即2的8次方种不一样的状态。
分别把编号从0开始的32种状态规定了特殊用途,要是终端、打印机遇上约定好的字节被传过来的时侯,就做约定的动作。要是遇上0x10,终端就会换行;要是遇上0x07,终端就嘟嘟叫;要是遇上0x1b,打印机就打印反白的字或者是终端用彩色显示字母。他们看到这样很好,就把这些0x20以下的字节状态称为”控制码”;
于是又把全部空格、标点符号、数字以及大小写字母分别用连续字节状态表示,一直编到第127号,这样的话计算机就能用不一样的字节存储英语文字。他们觉得很好,就把这个方案叫做ANSI的”ASCII”编码,即AmericanStandardCodeforInformationInterchange美国信息互换标准代码。当时世界上的计算机都在用相同的ASCII方案保存英文文字;
(1)ASCII扩展字符集的发展
世界各地都开始使用计算机了,但许多国家用的不是英文,字母里有许多是ASCII没有的,为了能在计算机保存他们的文字,他们就采用127号之后的空位表示这些新的字母以及符号。并且加入了许多画表格的时侯要用到的横线、竖线以及交叉等等的形状,一直把序号编到了255。从128到255的字符集就被称为“扩展字符集”;
(2)GB3212编码的诞生
中国开始用计算机时,已经没有能利用的字节状态可以表示汉字,重要的是,我们有6000多个常用汉字需要保存。但是,这难不倒智慧中国人民,人们就把那些127号后的奇异符号直接取消掉,并规定“一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节,即高字节从0xA1用到0xF7,后面一个字节,即低字节从0xA1到0xFE”,这样的话我们就能组合出7000多个简体汉字。在编码里,还可以把数学符号、罗马希腊的字母以及日文假名都编进去,在ASCII里本来就有数字、标点以及字母都重新两个字节长的编码,就是常说的”全角”字符,原来在127号以下就成为”半角”字符,我们把这种汉字方案称为“GB2312”,就是对ASCII的中文扩展;
(3)GBK编码的诞生
汉字实在太多了,很快就发现有人名没法打出来。于是,不得不继续把GB2312没有用到的码位找出来用上,但是还是不够用。于是就不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是汉字的开始,不管后面跟的是不是扩展字符集里的内容。扩展之后的编码方案被称为GBK标准,就包括了GB2312全部内容,又增加近20000个新的汉字,其中包括繁体字和符号;
(4)GB18030编码的诞生
渐渐的,少数民族也开始用电脑了,于是又加了几千个新的少数民族字,GBK就扩成了GB18030。从此,汉字编码体系就已经完成,中国程序员们通称它为”DBCS”,即DoubleByteCharecterSet双字节字符集。DBCS系列标准里,最大特点就是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,所以为了支持中文处理,他们写的程序就一定要注意字串里每一个字节的值,要是这个值大于127,就认为一个双字节字符集里的字符出现了;
(5)ISO组织与UNICODE编码的诞生
由于各国都制定了各自的编码标准,就导致互相之间谁也不懂谁的编码,谁也不支持别人的编码,就使不同编码之间互通信息时经常出现乱码。此时ISO,即国际标谁化组织就决定着手解决这个问题。他们废弃了所有的地区编码方案,重新搞一个包括了地球上全部文化、字母以及符号的编码,叫做”UniversalMultiple-OctetCodedCharacterSet”,简称为UCS,俗称为”UNICODE”。
#p#分页标题#e#
UNICODE开始制订时,计算机里的存储器容量就迅速发展,储存空间也不再成为问题。于是,ISO就规定必须用两个字节,也就是16位来统一表示全部字符,对于ASCII里的那些”半角”字符,UNICODE保持其原编码不变,只把长度由原来的8位扩展为16位,其他文化和语言的字符就全部重新统一编码。由于”半角”英文符号只需要用到低8位,所以它的高8位永远是0,所以这种方案在保存英文文本时就会浪费一倍的空间。
此时,程序员就发现strlen函数靠不住了,一个汉字相当于一个字符,而不再是两个。从UNICODE开始,不管是半角的英文字母,还是全角的汉字,都是统一的”一个字符”。并且都是统一的”两个字节”,就要注意”字符”和”字节”两个术语的不同,”字节”是一个8位的物理储存单元,”字符”就是一个文化相关的符号。在UNICODE当中,一个字符就是两个字节。
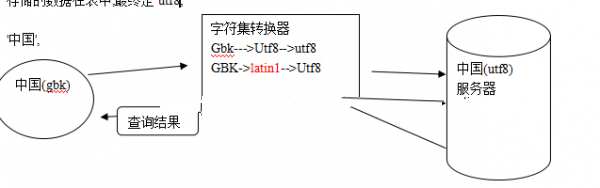
但是,在UNICODE制订时没有考虑与任何一种编码方案保持兼容,这就使GBK与UNICODE在汉字的内码编排上完全不一样,不存在简单的算术方法能把文本内容从UNICODE编码和另一种编码中进行转换,这种转换一定要通过查表进行。
综上所述,UNICODE用两个字节表示一个字符,他能够组合出65535个不一样的字符,这应该能够覆盖全部文化的符号。要是不够也没关系,ISO准备了UCS-4方案,就是用四个字节表示一个字符,这样就可以组合出21亿个不一样的字符,最高位有其他用),这应该能够用很久;
(6)网络时代与UTF-8编码的诞生
UNICODE来到时,一计算机网络也兴起了,UNICODE在网络上如何传输也是必须考虑的问题,于是面向传输的UTF,即UCSTransferFormat标准出现了,即UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只为传输时的可靠性,从UNICODE到UTF时不是直接对应,而是要过算法和规则转换,UTF-8用1到6个字节编码UNICODE字符。
UTF-8是变长字节编码方式。要是只有一个字节的话,某个字符的UTF-8编码最高二进制位是0,如果是多字节,从最高位开始第一个字节,连续的二进制位值为1的个数决定了其编码的位数,其余的字节都以10开头。UTF-8可以最多用到6个字节。
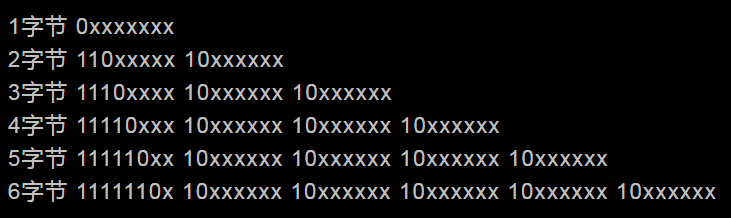
所以,UTF-8中能表示字符编码的实际位数有31位,就是说x表示的位。这些x表示的位与UNICODE编码是对应的,位高低顺序也一样,除了控制位,即每字节开头的10等。
(7)UNICODE转换UTF-8编码规则简述
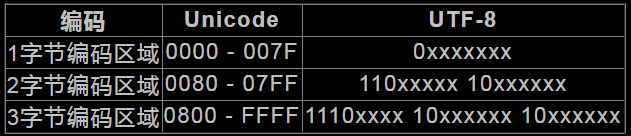
上表是1~3字节Unicode转UTF-8的规范,如下例:
如”汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,就要用3字节模板:1110xxxx10xxxxxx10xxxxxx。把6C49的二进制为:0110110001001001,把这个比特流按三字节模板的分段方法为0110110001001001,依次代替模板中的x,就能得到:1110-011010-11000110-001001,就是说E6B189,为”汉”这个字的UTF8编码,所以中文一个字符在UTF-8编码中占3字节。
对于数据高低位的解读方式,在网络里传递信息时是很重要的问题。一些计算机采用低位先发送的方法,如INTEL架构,另一些就采用高位先发送的方式。网络中交换数据的时侯,为了核对双方对于高低位的认识是不是一致,就采用了简便方法,即在文本流开始时向对方发送一个标志符,要是文本先发送高位,那就发送”FEFF”,不然的话就发送”FFFE”。
大家已经对字符编码的发展历史有了一个新的认识了。
(二)出现乱码的原因
200x年一段经典例子中,有人在Windows系统中打开了记事本程序,并输入了中文字符”联通”。然而,当时的windows记事本的编码默认是ASCII,ASCII编码不可以识别汉字,而当时的Windows系统多数都安装了汉化语言包,即GB2312或GBK编码,在最后保存的时候,记事本用GB系列编码方式把这两个中文字符储存到了硬盘上,所以,”联通”的内码转换如下:
”联”对应的GBK编码是c1aa,”通”对应的GBK编码是cda8,二进制如下:
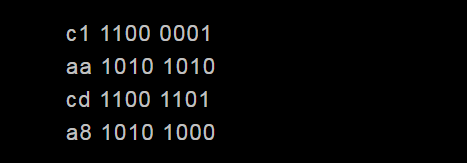
#p#分页标题#e#
注意:第一二个字节、第三四个字节起始部分都是”110″和”10″,刚好跟UTF8规则里的两字节模板相同。再打开记事本,记事本就会认为这是UTF8编码的文件,对UTF8编码进行还原操作,把第一个字节的110和第二个字节的10去掉,得到”00001101010″,然后把各位对齐,前端补0,就得到”0000000001101010″,对应Unicode的006A,就是小写的字母”j”,而之后的两字节用UTF8转换成Unicode是0368。这就是只有”联通”两个字的文件,保存后再次打开,变成乱码j口,而”口”可能是任意无法识别的字符代替的原因。
要是在”联通”之后多输入几个字保存,它们编码就不一定恰好是110和10开始的字节,这样的话,再打开时,记事本就不会坚持这是一个utf8编码的文件,就会尝试ASCII和GBK编码进行解读。这时,乱码就不出现了。
总结:在上例,记事本文件保存到硬盘当中,就是把数据存储到数据库当中,记事本程序就等同于连接数据库时用的文字终端,然而,乱码的产生是由于终端和数据库分别使用了不一样的编码解释数据,小编在接下来会给大家详细解释。其实小编觉得,MySQL当中还能开发出很多很有趣的东西,不过就需要我们不断的摸索哦。
