Druid入门须知
随着互联网快速发展,数据量增长快,达到TB、PB,以交通车流量为例,如湖南省每月的车辆流量至少达到4亿,这个数据量远不止如此。数据量如此大,如何满足后期分析,传统面向OLTP型数据库(Oracle、MySQL等)无法要求,渐渐开始转向OLAP,如GreenPlum等,虽然很多OLAP数据库吸收分布式计算思想,数据达到20亿以上后,进行Count、聚合等操作性能仍然达不到客户实时分析要求。
虽然相关大数据框架及组件已经很流行:Hadoop(离线分析)、Spark、storm、Hive、Impala、Hbase等,Hadoop生态系统大庞大,Spark一站式安装部署,但是满足实时分析还需借助其它组件、开发要求很高。
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。尤其是当发生代码部署、机器故障以及其他产品系统遇到宕机等情况时,Druid仍能够保持100%正常运行。创建Druid的最初意图主要是为了解决查询延迟问题,当时试图使用Hadoop来实现交互式查询分析,但是很难满足实时分析的需要。而Druid提供了以交互方式访问数据的能力,并权衡了查询的灵活性和性能而采取了特殊的存储格式。
一、特征:
1.为分析而设计——Druid是为OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
2.快速的交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
3.高可用性——Druid的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
4.可扩展——Druid已实现每天能够处理数十亿事件和TB级数据。
二、业务场景:
1.需要交互式聚合和快速探究大量数据时;
2.需要实时查询分析时;
3.具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
4.对数据尤其是大数据进行实时分析时;
5.需要一个高可用、高容错、高性能数据库时。
Druid被设计成增强的分析应用,重点关注注入数据和查询数据的延时问题
三、Druid目的:
之所以需要Druid,是因为现实情况是现有的开源关系型数据库(RDBMS)和NoSQLkey/value数据库没办法为一些交互式应用提供低延迟的数据导入和查询,除了查询响应时间的要求外,该系统还必须是多租户和高可用的。
秒级的数据导入和查询的要求
四、Druid节点:
外部依赖:MySQL、DeepStorage、Zookeeper
1.realtime数据消费者,定期生成不可变数据
2.historical加载和处理由实时节点创建的不可变数据
3.coordinator
4.broker
5.overload
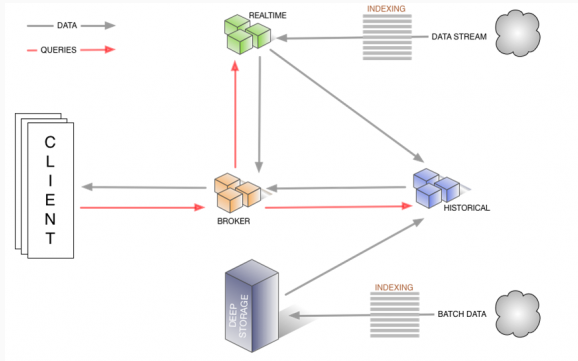
同时它还有以下模块:
1.DruidDriver代理Driver,能够提供基于Filter-Chain模式的插件体系。
2.SQLParser
所以Druid可以:
1、充当数据库连接池。
2、可以监控数据库访问性能
3、获得SQL执行日志
简单配置如下:

Druid是目前比较流行的高性能的,分布式列存储的OLAP框架(具体来说是MOLAP)。它有如下几个特点:
1.亚秒级查询
druid提供了快速的聚合能力以及亚秒级的OLAP查询能力,多租户的设计,是面向用户分析应用的理想方式。
2.实时数据注入
druid支持流数据的注入,并提供了数据的事件驱动,保证在实时和离线环境下事件的实效性和统一性
3.可扩展的PB级存储
druid集群可以很方便的扩容到PB的数据量,每秒百万级别的数据注入。即便在加大数据规模的情况下,也能保证时其效性
4.多环境部署
druid既可以运行在商业的硬件上,也可以运行在云上。它可以从多种数据系统中注入数据,包括hadoop,spark,kafka,storm和samza等
5.丰富的社区
druid拥有丰富的社区,供大家学习。
小编结语:
更多内容尽在课课家教育~~
