如何利用Spring实现数据库读写分离?
现在大型的电子商务系统,在数据库层面大都采用读写分离技术,就是一个Master数据库,多个Slave数据库。Master库负责数据更新和实时数据查询,Slave库当然负责非实时数据查询。因为在实际的应用中,数据库都是读多写少(读取数据的频率高,更新数据的频率相对较少),而读取数据通常耗时比较长,占用数据库服务器的CPU较多,从而影响用户体验。我们通常的做法就是把查询从主库中抽取出来,采用多个从库,使用负载均衡,减轻每个从库的查询压力。
采用读写分离技术的目标:有效减轻Master库的压力,又可以把用户查询数据的请求分发到不同的Slave库,从而保证系统的健壮性。我们看下采用读写分离的背景。
随着网站的业务不断扩展,数据不断增加,用户越来越多,数据库的压力也就越来越大,采用传统的方式,比如:数据库或者SQL的优化基本已达不到要求,这个时候可以采用读写分离的策略来改变现状。
具体到开发中,如何方便的实现读写分离呢?目前常用的有两种方式:
1.第一种方式是我们最常用的方式,就是定义2个数据库连接,一个是MasterDataSource,另一个是SlaveDataSource。更新数据时我们读取MasterDataSource,查询数据时我们读取SlaveDataSource。这种方式很简单,我就不赘述了。
2.第二种方式动态数据源切换,就是在程序运行时,把数据源动态织入到程序中,从而选择读取主库还是从库。主要使用的技术是:annotation,SpringAOP,反射。
借助于spring框架在2.0.1之后提供的AbstractRoutingDataSource可以实现动态的选择数据源datasource,下面先举一个最简单的例子:
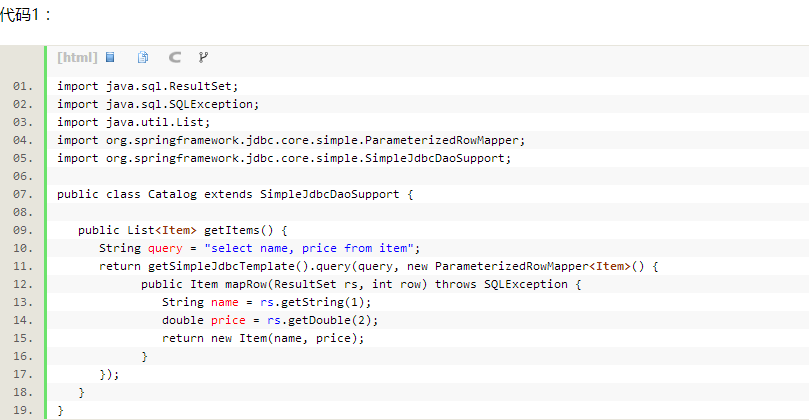
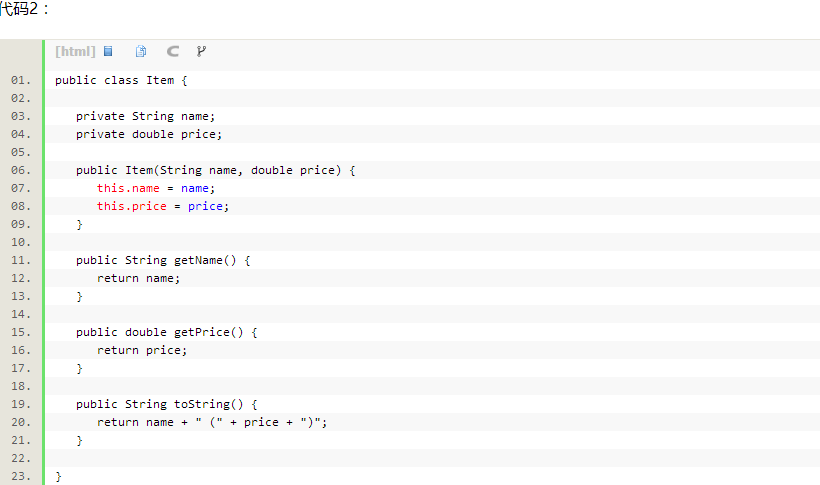
一、首先新建一个CatalogVO对象的DAO(见代码1),它继承了SimpleJdbcDaoSupport,JdbcDaoSupport需要注入一个DataSource,同时也提供了操作模板JdbcTemplate。添加一个方法用于获取所有的“货物Item”。货物Iteam是一个POJO类(见代码2)
代码1:
代码2:
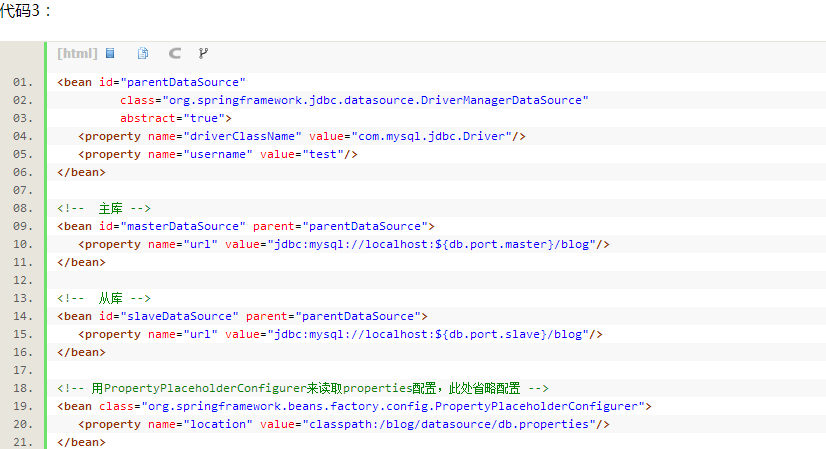
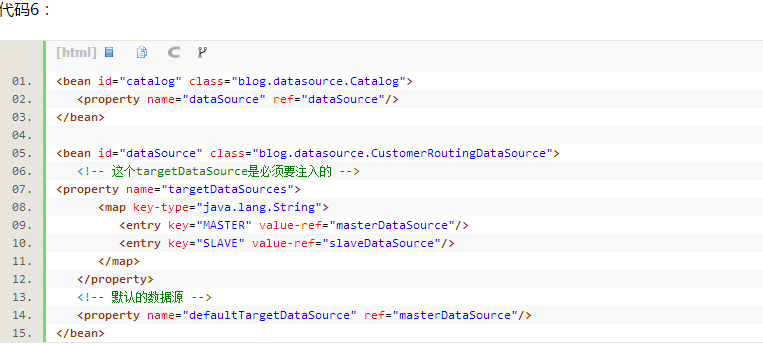
二、配置Spring多数据源,这里配置了一个主库和一个从库,他们可以共同继承一个父的数据源。
代码3:
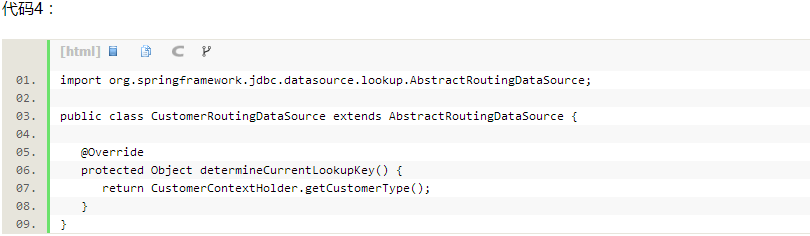
三、新建一个datasource继承自AbstractRoutingDataSource,并且覆盖determineCurrentLookupKey()方法,每次用这个datasource获取数据库连接的时候都会回调这个方法获得key,根据返回的字符串key(也可以是枚举值,数字类型),动态地通过datasource配置的id来在Spring的配置文件中找到相应的datasource来获取connection(见代码4)。那么如果每次访问都需要根据key来决定如何选择数据源,那么这个key必须要保证线程安全,并发情况下每个线程都会去寻找本应该属于自己的key获取数据源,所以CustomerContextHolder类中就用到了ThreadLocal来保证(见代码5)。
代码4:
代码5:

在Spring中的配置如下:
代码6:
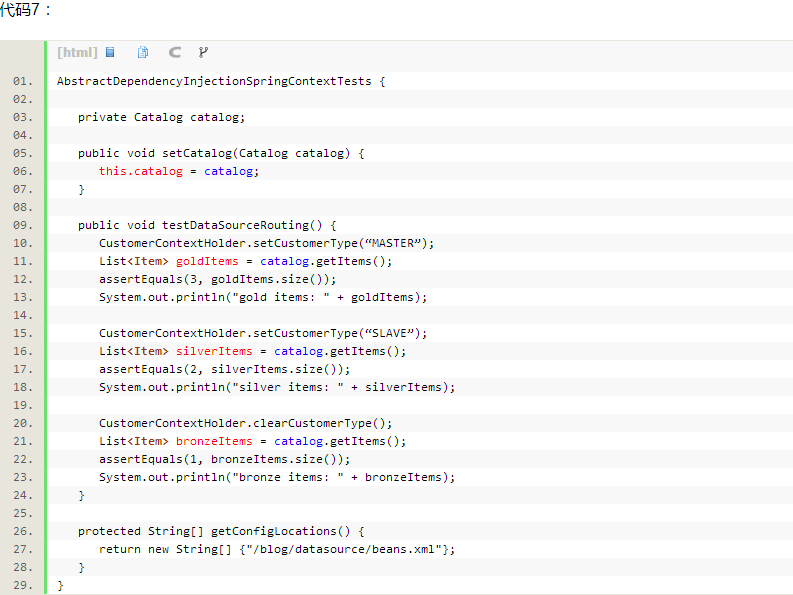
四、测试用例
代码7:
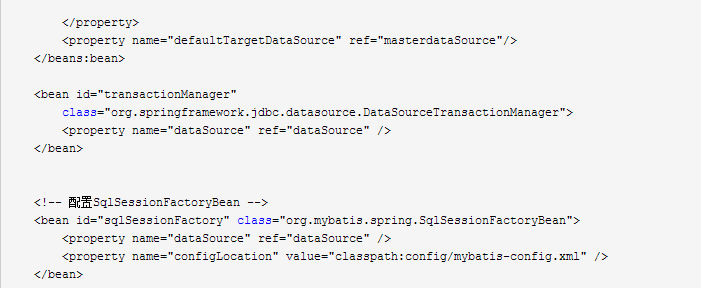
为了方便测试,另外定义了2个数据库,shop模拟Master库,test模拟Slave库,shop和test的表结构一致,但数据不同,数据库配置如下:

#p#分页标题#e#
在spring的配置中增加aop配置
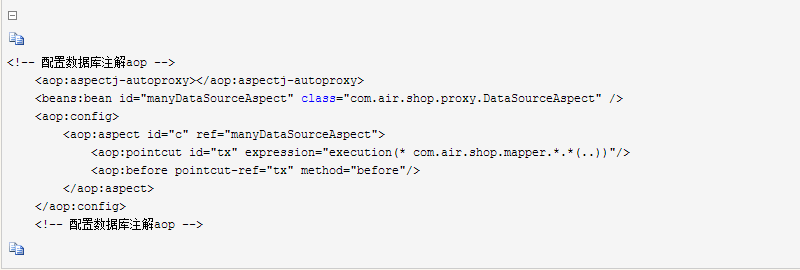
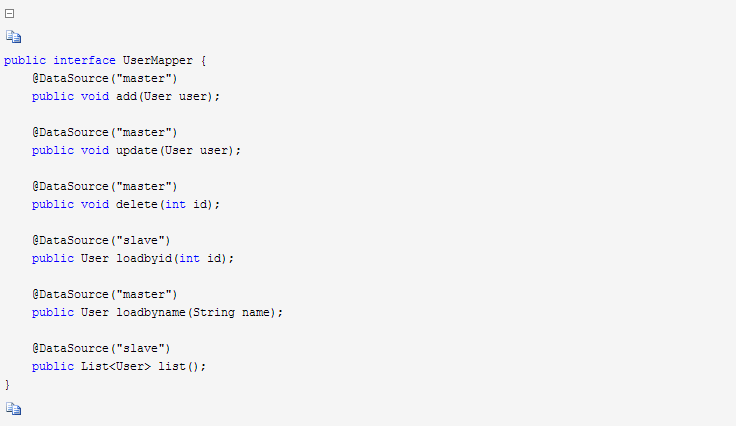
下面是MyBatis的UserMapper的定义,为了方便测试,登录读取的是Master库,用户列表读取Slave库:
好了,运行我们的Eclipse看看效果,输入用户名admin登录看看效果
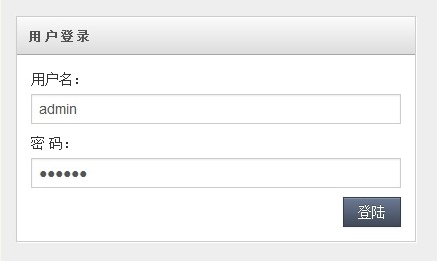
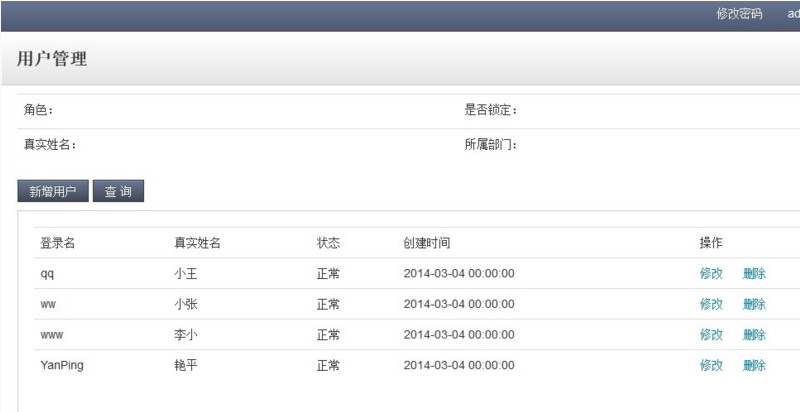
从图中可以看出,登录的用户和用户列表的数据是不同的,也验证了我们的实现,登录读取Master库,用户列表读取Slave库。
小编结语:
更多内容尽在课课家教育~~
