利用Java语言举办Unicode署理编程
副标题#e#
早期 Java 版本利用 16 位 char 数据范例暗示 Unicode 字符。这种设计方 法有时较量公道,因为所有 Unicode 字符拥有的值都小于 65,535 (0xFFFF), 可以通过 16 位暗示。可是,Unicode 厥后将最大值增加到 1,114,111 (0x10FFFF)。由于 16 位太小,不能暗示 Unicode version 3.1 中的所有 Unicode 字符,32 位值 — 称为码位(code point) — 被用于 UTF-32 编码模式。
但与 32 位值对比,16 位值的内存利用效率更高, 因此 Unicode 引入了一个种新设计要领来答允继承利用 16 位值。UTF-16 中采 用的这种设计要领分派 1,024 值给 16 位高署理(high surrogate),将别的 的 1,024 值分派给 16 位低署理(low surrogate)。它利用一个高署理加上一 个低署理 — 一个署理对(surrogate pair) — 来暗示 65,536 (0x10000) 和 1,114,111 (0x10FFFF) 之间的 1,048,576 (0x100000) 值 (1,024 和 1,024 的乘积)。
Java 1.5 保存了 char 范例的行为来表 示 UTF-16 值(以便兼容现有措施),它实现了码位的观念来暗示 UTF-32 值。这个扩展(按照 JSR 204:Unicode Supplementary Character Support 实现) 不需要记着 Unicode 码位或转换算法的精确值 — 但领略署理 API 的正 确用法很重要。
东亚国度和地域连年来增加了它们的字符会合的字符数 量,以满意用户需求。这些尺度包罗来自中国的国度尺度组织的 GB 18030 和来 自日本的 JIS X 0213。因此,寻求遵守这些尺度的措施更有须要支持 Unicode 署理对。本文表明相关 Java API 和编码选项,面向打算从头设计他们的软件, 从只能利用 char 范例的字符转换为可以或许处理惩罚署理对的新版本的读者。
顺序会见
顺序会见是在 Java 语言中处理惩罚字符串的一个根基操纵。在 这种要领下,输入字符串中的每个字符从新至尾按顺序会见,可能有时从尾至头 会见。本小节接头利用顺序会见要领从一个字符串建设一个 32 位码位数组的 7 个技能示例,并预计它们的处理惩罚时间。
示例 1-1:基准测试(不支持代 理对)
清单 1 将 16 位 char 范例值直接分派给 32 位码位值,完全没 有思量署理对:
清单 1. 不支持署理对
int[] toCodePointArray(String str) { // Example 1-1
int len = str.length(); // the length of str
int[] acp = new int[len]; // an array of code points
for (int i = 0, j = 0; i < len; i++) {
acp[j++] = str.charAt(i);
}
return acp;
}
尽量这个示例不支持署理对,但它提供了一个处理惩罚时间基准来比 较后续顺序会见示例。
示例 1-2:利用 isSurrogatePair()
清单 2 利用 isSurrogatePair() 来计较署理对总数。计数之后,它分派足够的内存 以便一个码位数组存储这个值。然后,它进入一个顺序会见轮回,利用 isHighSurrogate() 和 isLowSurrogate() 确定每个署理对字符是高署理照旧低 署理。当它发明一个高署理后头带一个低署理时,它利用 toCodePoint() 将该 署理对转换为一个码位值并将当前索引值增加 2。不然,它将这个 char 范例值 直接分派给一个码位值并将当前索引值增加 1。这个示例的处理惩罚时间比 示例 1 -1 长 1.38 倍。
清单 2. 有限支持
int[] toCodePointArray(String str) { // Example 1-2
int len = str.length(); // the length of str
int[] acp; // an array of code points
int surrogatePairCount = 0; // the count of surrogate pairs
for (int i = 1; i < len; i++) {
if (Character.isSurrogatePair(str.charAt(i - 1), str.charAt(i))) {
surrogatePairCount++;
i++;
}
}
acp = new int[len - surrogatePairCount];
for (int i = 0, j = 0; i < len; i++) {
char ch0 = str.charAt(i); // the current char
if (Character.isHighSurrogate(ch0) && i + 1 < len) {
char ch1 = str.charAt(i + 1); // the next char
if (Character.isLowSurrogate(ch1)) {
acp[j++] = Character.toCodePoint(ch0, ch1);
i++;
continue;
}
}
acp[j++] = ch0;
}
return acp;
}
#p#副标题#e#
清单 2 中更新软件的要领很幼稚。它较量贫苦,需要大量修改 ,使得生成的软件很懦弱且此后难以变动。详细而言,这些问题是:
需 要计较码位的数量以分派足够的内存
很可贵到字符串中的指定索引的正 确码位值
很难为下一个处理惩罚步调正确移动当前索引
一个改造后的算法呈此刻下一个示例中。
示例:根基支持
Java 1.5 提供了 codePointCount()、codePointAt() 和 offsetByCodePoints() 要领来别离处理惩罚 示例 1-2 的 3 个问题。清单 3 利用 这些要领来改进这个算法的可读性:
清单 3. 根基支持
#p#分页标题#e#
int[] toCodePointArray(String str) { // Example 1- 3
int len = str.length(); // the length of str
int[] acp = new int[str.codePointCount(0, len)];
for (int i = 0, j = 0; i < len; i = str.offsetByCodePoints(i, 1)) {
acp[j++] = str.codePointAt(i);
}
return acp;
}
可是,清单 3 的处理惩罚时间比 清单 1 长 2.8 倍。
示例 1-4:利用 codePointBefore()
当 offsetByCodePoints() 吸收一个负数 作为第二个参数时,它就能计较一个间隔字符串头的绝对偏移值。接下来, codePointBefore() 可以或许返回一个指定索引前面的码位值。这些要领用于清单 4 中从尾至头遍历字符串:
清单 4. 利用 codePointBefore() 的根基支持
int[] toCodePointArray(String str) { // Example 1-4
int len = str.length(); // the length of str
int[] acp = new int[str.codePointCount(0, len)];
int j = acp.length; // an index for acp
for (int i = len; i > 0; i = str.offsetByCodePoints(i, -1)) {
acp[--j] = str.codePointBefore(i);
}
return acp;
}
这个示例的处理惩罚时间 — 比 示例 1-1 长 2.72 倍 — 比 示例 1-3 快一些。凡是,当您较量零而不长短零值时,JVM 中的代 码巨细要小一些,这有时会提高机能。可是,微小的改造大概不值得牺牲可读性 。
示例 1-5:利用 charCount()
示例 1-3 和 1-4 提供根基的代 理对支持。他们不需要任何姑且变量,是结实的编码要领。要获取更短的处理惩罚时 间,利用 charCount() 而不是 offsetByCodePoints() 是有效的,但需要一个 姑且变量来存放码位值,如清单 5 所示:
清单 5. 利用 charCount() 的优化支持
int[] toCodePointArray(String str) { // Example 1-5
int len = str.length(); // the length of str
int[] acp = new int[str.codePointCount(0, len)];
int j = 0; // an index for acp
for (int i = 0, cp; i < len; i += Character.charCount(cp)) {
cp = str.codePointAt (i);
acp[j++] = cp;
}
return acp;
}
清单 5 的处理惩罚时间低落到比 示例 1-1 长 1.68 倍。
示例 1-6:会见一个 char 数组
清单 6 在利用 示例 1-5 中展 示的优化的同时直接会见一个 char 范例数组:
清单 6. 利用一个 char 数组的优化支持
int[] toCodePointArray(String str) { // Example 1-6
char[] ach = str.toCharArray(); // a char array copied from str
int len = ach.length; // the length of ach
int[] acp = new int [Character.codePointCount(ach, 0, len)];
int j = 0; // an index for acp
for (int i = 0, cp; i < len; i += Character.charCount(cp)) {
cp = Character.codePointAt(ach, i);
acp[j++] = cp;
}
return acp;
}
char 数组 是利用 toCharArray() 从字符串复制而来的。机能获得改进,因为对数组的直 接会见比通过一个要领的间接会见要快。处理惩罚时间比 示例 1-1 长 1.51 倍。但 是,当挪用时,toCharArray() 需要一些开销来建设一个新数组并将数据复制到 数组中。String 类提供的那些利便的要领也不能被利用。可是,这个算法在处 理大量数据时有用。
示例 1-7:一个面向工具的算法
这个示例的 面向工具算法利用 CharBuffer 类,如清单 7 所示:
清单 7. 利用 CharSequence 的面向工具算法
int[] toCodePointArray(String str) { // Example 1-7
CharBuffer cBuf = CharBuffer.wrap(str); // Buffer to wrap str
IntBuffer iBuf = IntBuffer.allocate( // Buffer to store code points
Character.codePointCount(cBuf, 0, cBuf.capacity ()));
while (cBuf.remaining() > 0) {
int cp = Character.codePointAt(cBuf, 0); // the current code point
iBuf.put(cp);
cBuf.position (cBuf.position() + Character.charCount(cp));
}
return iBuf.array();
}
#p#分页标题#e#
与前面的示例差异,清单 7 不 需要一个索引来持有当前位置以便举办顺序会见。相反,CharBuffer 在内部跟 踪当前位置。Character 类提供静态要领 codePointCount() 和 codePointAt() ,它们能通过 CharSequence 接口处理惩罚 CharBuffer。CharBuffer 老是将当前位 置配置为 CharSequence 的头。因此,当 codePointAt() 被挪用时,第二个参 数老是配置为 0。处理惩罚时间比 示例 1-1 长 2.15 倍。
处理惩罚时间较量
这些顺序会见示例的计时测试利用了一个包括 10,000 个署理对和 10,000 个非署理对的样例字符串。码位数组从这个字符串建设 10,000 次。测 试情况包罗:
OS:Microsoft Windows® XP Professional SP2
Java:IBM Java 1.5 SR7
CPU:Intel® Core 2 Duo CPU T8300 @ 2.40GHz
Memory:2.97GB RAM
表 1 展示了示例 1-1 到 1-7 的绝 对和相对处理惩罚时间以及关联的 API:
表 1. 顺序会见示例的处理惩罚时间和 API
| 示例 | 说明 | 处理惩罚 时间 (毫秒) |
与 示例 1-1 的比率 |
API |
|---|---|---|---|---|
| 1-1 | 不支持署理对 | 2031 | 1.00 | |
| 1-2 | 有限支持 | 2797 | 1.38 | Character 类:
static boolean isHighSurrogate(char ch) static boolean isLowSurrogate(char ch) static boolean isSurrogatePair(char high, char low) static int toCodePoint(char high, char low) |
| 1-3 | 根基支持 | 5687 | 2.80 | String 类:
int codePointAt(int index) int codePointCount(int begin, int end) int offsetByCodePoints(int index, int cpOffset) |
| 1-4 | 利用 codePointBefore() 的根基支持 | 5516 | 2.72 | String 类:
int codePointBefore(int index) |
| 1-5 | 使 用 charCount() 的优化支持 | 3406 | 1.68 | Character 类:
static int charCount(int cp) |
| 1-6 | 利用 一个 char 数组的优化支持 | 3062 | 1.51 | Character 类:
static int codePointAt(char[] ach, int index) static int codePointCount(char[] ach, int offset, int count) |
| 1-7 | 利用 CharSequence 的面向工具要领 | 4360 | 2.15 | Character 类:
static int codePointAt(CharSequence seq, int index) static int codePointCount(CharSequence seq, int begin, int end) |
随时机见
随时机见是直接会见一个字符串中 的任意位置。当字符串被会见时,索引值基于 16 位 char 范例的单元。可是, 假如一个字符串利用 32 位码位,那么它不能利用一个基于 32 位码位的单元的 索引会见。必需利用 offsetByCodePoints() 来将码位的索引转换为 char 范例 的索引。假如算法设计很糟糕,这会导致很差的机能,因为 offsetByCodePoints() 老是通过利用第二个参数从第一个参数计较字符串的内 部。在这个小节中,我将较量三个示例,它们通过利用一个短单元来支解一个长 字符串。
示例 2-1:基准测试(不支持署理对)
清单 8 展示如 何利用一个宽度单元来支解一个字符串。这个基准测试留作后用,不支持署理对 。
清单 8. 不支持署理对
#p#分页标题#e#
String[] sliceString(String str, int width) { // Example 2-1
// It must be that "str != null && width > 0".
List<String> slices = new ArrayList<String>();
int len = str.length(); // (1) the length of str
int sliceLimit = len - width; // (2) Do not slice beyond here.
int pos = 0; // the current position per char type
while (pos < sliceLimit) {
int begin = pos; // (3)
int end = pos + width; // (4)
slices.add(str.substring(begin, end));
pos += width; // (5)
}
slices.add(str.substring(pos)); // (6)
return slices.toArray(new String[slices.size()]); }
sliceLimit 变量对支解位置有所限制,以制止在剩余的字符串不敷以支解当前宽度单元时抛 出一个 IndexOutOfBoundsException 实例。这种算法在当前位置超出 sliceLimit 时从 while 轮回中跳出后再处理惩罚最后的支解。
示例 2-2: 利用一个码位索引
清单 9 展示了如何利用一个码位索引来随时机见一个 字符串:
清单 9. 糟糕的机能
String[] sliceString (String str, int width) { // Example 2-2
// It must be that "str != null && width > 0".
List<String> slices = new ArrayList<String>();
int len = str.codePointCount(0, str.length()); // (1) code point count [Modified]
int sliceLimit = len - width; // (2) Do not slice beyond here.
int pos = 0; // the current position per code point
while (pos < sliceLimit) {
int begin = str.offsetByCodePoints(0, pos); // (3) [Modified]
int end = str.offsetByCodePoints(0, pos + width); // (4) [Modified]
slices.add(str.substring(begin, end));
pos += width; // (5)
}
slices.add(str.substring (str.offsetByCodePoints(0, pos))); // (6) [Modified]
return slices.toArray(new String[slices.size()]); }
清 单 9 修改了 清单 8 中的几行。首先,在 Line (1) 中,length() 被 codePointCount() 替代。其次,在 Lines (3)、(4) 和 (6) 中,char 范例的 索引通过 offsetByCodePoints() 用码位索引替代。
根基的算法流与 示 例 2-1 中的看起来险些一样。但处理惩罚时间按照字符串长度与示例 2-1 的比率同 比增加,因为 offsetByCodePoints() 老是从字符串头到指定索引计较字符串内 部。
示例 2-3:淘汰的处理惩罚时间
可以利用清单 10 中展示的要领 来制止 示例 2-2 的机能问题:
清单 10. 改造的机能
String[] sliceString(String str, int width) { // Example 2-3
// It must be that "str != null && width > 0".
List<String> slices = new ArrayList<String>();
int len = str.length(); // (1) the length of str
int sliceLimit // (2) Do not slice beyond here. [Modified]
= (len >= width * 2 || str.codePointCount(0, len) > width)
? str.offsetByCodePoints(len, -width) : 0;
int pos = 0; // the current position per char type
while (pos < sliceLimit) {
int begin = pos; // (3)
int end = str.offsetByCodePoints(pos, width); // (4) [Modified]
slices.add(str.substring(begin, end));
pos = end; // (5) [Modified]
}
slices.add(str.substring(pos)); // (6)
return slices.toArray(new String [slices.size()]); }
#p#分页标题#e#
首先,在 Line (2) 中,(清单 9 中的 )表达式 len-width 被 offsetByCodePoints(len,-width) 替代。可是,当 width 的值大于码位的数量时,这会抛出一个 IndexOutOfBoundsException 实 例。必需思量界线条件以制止异常,利用一个带有 try/catch 异常处理惩罚措施的 子句将是另一个办理方案。假如表达式 len>width*2 为 true,则可以安详 地挪用 offsetByCodePoints(),因为纵然所有码位都被转换为署理对,码位的 数量仍会高出 width 的值。可能,假如 codePointCount(0,len)>width 为 true,也可以安详地挪用 offsetByCodePoints()。假如是其他环境, sliceLimit 必需配置为 0。
在 Line (4) 中,清单 9 中的表达式 pos + width 必需在 while 轮回中利用 offsetByCodePoints(pos,width) 替换。需 要计较的量位于 width 的值中,因为第一个参数指定当 width 的值。接下来, 在 Line (5) 中,表达式 pos+=width 必需利用表达式 pos=end 替换。这制止 两次挪用 offsetByCodePoints() 来计较沟通的索引。源代码可以被进一步修改 以最小化处理惩罚时间。
处理惩罚时间较量
图 1 和图 2 展示了示例 2-1 、2-2 和 2-3 的处理惩罚时间。样例字符串包括沟通数量的署理对和非署理对。当 字符串的长度和 width 的值被变动时,样例字符串被切割 10,000 次。
图 1. 一个分段的常量宽度
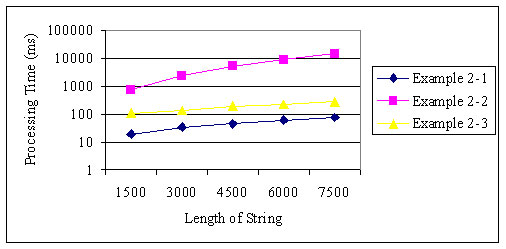
图 2. 分段的常量计数
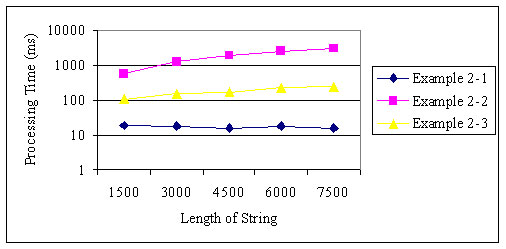
示例 2-1 和 2-3 凭据长度比例增加了它们的处理惩罚时间,但 示例 2-2 凭据长度的平方比例增加了处理惩罚时间。当字符串长度和 width 的值增加而分段 的数量固按时,示例 2-1 拥有一个常量处理惩罚时间,而示例 2-2 和 2-3 以 width 的值为比例增加了它们的处理惩罚时间。
信息 API
大大都处理惩罚 署理的信息 API 拥有两种名称沟通的要领。一种吸收 16 位 char 范例参数, 另一种吸收 32 为码位参数。表 2 展示了每个 API 的返回值。第三列针对 U+53F1,第 4 列针对 U+20B9F,最后一列针对 U+D842(即高署理),而 U+20B9F 被转换为 U+D842 加上 U+DF9F 的署理对。假如措施不能处理惩罚署理对, 则值 U+D842 而不是 U+20B9F 将导致意想不到的功效(在表 2 中以粗斜体暗示 )。
表 2. 用于署理的信息 API
| 类 | 要领/结构函数 | 针对 U+53F1 的值 | 针对 U+20B9F 的值 | 针对 U+D842 的值 |
|---|---|---|---|---|
| Character | static byte getDirectionality(int cp) | 0 | 0 | 0 |
| static int getNumericValue(int cp) | -1 | -1 | – 1 | |
| static int getType(int cp) | 5 | 5 | 19 | |
| static boolean isDefined(int cp) | true | true | true | |
| static boolean isDigit(int cp) | false | false | false | |
| static boolean isISOControl(int cp) | false | false | false | |
| static boolean isIdentifierIgnorable(int cp) | false | false | false | |
| static boolean isJavaIdentifierPart(int cp) | true | true | false | |
| static boolean isJavaIdentifierStart(int cp) | true | true | false | |
| static boolean isLetter(int cp) | true | true | false | |
| static boolean isLetterOrDigit(int cp) | true | true | false | |
| static boolean isLowerCase(int cp) | false | false | false | |
| static boolean isMirrored(int cp) | false | false | false | |
| static boolean isSpaceChar(int cp) | false | false | false | |
| static boolean isSupplementaryCodePoint(int cp) | false | true | false | |
| static boolean isTitleCase(int cp) | false | false | false | |
| static boolean isUnicodeIdentifierPart(int cp) | true | true | false | |
| static boolean isUnicodeIdentifierStart(int cp) | true | true | false | |
| static boolean isUpperCase(int cp) | false | false | false | |
| static boolean isValidCodePoint(int cp) | true | true | true | |
| static boolean isWhitespace(int cp) | false | false | false | |
| static int toLowerCase(int cp) | (不行变动 ) | |||
| static int toTitleCase(int cp) | (不行变动) | |||
| static int toUpperCase(int cp) | (不行变动) | |||
Character. |
Character.UnicodeBlock of(int cp) | CJK_UNIFIED_IDEOGRAPHS | CJK_UNIFIED_IDEOGRAPHS_EXTENSI ON_B | HIGH_SURROGATES |
| Font | boolean canDisplay(int cp) | (取决于 Font 实例) | ||
| FontMetrics | int charWidth(int cp) | (取决于 FontMetrics 实例) | ||
| String | int indexOf(int cp) | (取决于 String 实例) | ||
| int lastIndexOf(int cp) | (取决于 String 实例) | |||
其他 API
本小节先容前面的小节中没有接头 的署理对相关 API。表 3 展示所有这些剩余的 API。所有署理对 API 都包括在 表 1、2 和 3 中。
表 3. 其他署理 API
#p#分页标题#e#
| 类 | 要领/结构函数 |
|---|---|
| Character | static int codePointAt(char[] ach, int index, int limit) |
| static int codePointBefore(char[] ach, int index) | |
| static int codePointBefore(char[] ach, int index, int start) | |
| static int codePointBefore(CharSequence seq, int index) | |
| static int digit(int cp, int radix) | |
| static int offsetByCodePoints (char[] ach, int start, int count, int index, int cpOffset) | |
| static int offsetByCodePoints (CharSequence seq, int index, int cpOffset) | |
| static char[] toChars(int cp) | |
| static int toChars(int cp, char[] dst, int dstIndex) | |
| String | String(int[] acp, int offset, int count) |
| int indexOf(int cp, int fromIndex) | |
| int lastIndexOf(int cp, int fromIndex) | |
| StringBuffer | StringBuffer appendCodePoint (int cp) |
| int codePointAt(int index) | |
| int codePointBefore(int index) | |
| int codePointCount(int beginIndex, int endIndex) | |
| int offsetByCodePoints(int index, int cpOffset) | |
| StringBuilder | StringBuilder appendCodePoint (int cp) |
| int codePointAt(int index) | |
| int codePointBefore(int index) | |
| int codePointCount(int beginIndex, int endIndex) | |
| int offsetByCodePoints(int index, int cpOffset) | |
IllegalFormat |
IllegalFormatCodePointException (int cp) |
| int getCodePoint() |
#p#分页标题#e#
清单 11 展示了从一个码位建设一个字符串的 5 种 要领。用于测试的码位是 U+53F1 和 U+20B9F,它们在一个字符串中反复了 100 亿次。清单 11 中的注释部门显示了处理惩罚时间:
清单 11. 从一个码位 建设一个字符串的 5 种要领
int cp = 0x20b9f; // CJK Ideograph Extension B
String str1 = new String(new int []{cp}, 0, 1); // processing time: 206ms
String str2 = new String(Character.toChars(cp)); // 187ms
String str3 = String.valueOf(Character.toChars(cp)); // 195ms
String str4 = new StringBuilder ().appendCodePoint(cp).toString(); // 269ms
String str5 = String.format("%c", cp); // 3781ms
str1、str2、str3 和 str4 的处理惩罚时间没有明明差异。相反,建设 str5 耗费的时间要长得多,因为它利用 String.format(),该要领支持基 于当地和名目化信息的机动输出。str5 要领应该只用于措施的末端来输出文本 。
竣事语
Unicode 的每个新版本都包括了通过署理对暗示的新定 义的字符。东亚字符集尺度并不是这样的字符的惟一来历。譬喻,移动电话中还 需要支持 Emoji 字符(心情图释),尚有各类古字符需要支持。您从本文收获 的技能和机能阐明将有助于您在您的 Java 应用措施中支持所有这些字符。
