借助BeanKeeper快速实现工具耐久化
副标题#e#
引言
NetMind BeanKeeper 是一个开源的 java 工具 / 干系数据库映 射框架,它可以辅佐用户快速将工具生存到干系数据库中,同时它也支持自界说 地查询和事务,可以满意用户在各类应用场景的需求。它最大的特点就是简朴, 无需设置。同时,它是纯 Java 的,也支持 HSQLDB 和 MySQL 等多种干系数据库。本文将先容 BeanKeeper 的根基道理和架构,并将其同 Hibernate、Spring 等其他框架举办较量,总结其主要利益。最后将演示一个案例先容如何借助 BeanKeeper 快捷地实现将 Java 工具生存到干系数据库中。
BeanKeeper 的架构
工具耐久性险些是所有 Java™ 应用措施( 从桌面应用措施到企业级应用措施)中的必备,耐久性的缺点是它一直都不太简 单。
面向工具的开拓要领是当今企业级应用开拓情况中的主流开拓要领 ,干系数据库是企业级应用情况中永久存放数据的主流数据存储系统。工具和关 系数据是业务实体的两种表示形式,业务实体在内存中表示为工具,在数据库中 表示为干系数据。内存中的工具之间存在关联和担任干系,而在数据库中,干系 数据无法直接表达多对多关联和担任干系。因此,需要 ORM(Object Relational Mapping)实现措施工具到干系数据库数据的映射。
由于关 系数据库是今朝最风行的存储系统,因此要将工具耐久化到干系数据库中,我们 就要办理 ORM 的问题。今朝主流的 ORM 框架有:Spring、Hibernate 等框架。 它们都存在一个问题是:太巨大了。要操作这些框架举办工具耐久化,开拓人员 首先要阅读几百页的文档以相识如何利用这些框架,然后又要编写 XML 设置映 射文件以汇报框架假如和举办 ORM。并且一旦工具模子产生改变后又要修改映射 文件。这些都极大地增加了开拓人员的进修曲线和事情量,同时也容易堕落。而 Bean keeper 的理念是简朴的工作简朴做,它只管简化这些操纵。
Bean Keeper 是一个基于 LGPL 协议的开源软件,它具有如下特性:
利用简朴,你只需要进修 3 个捏词就可以根基把握其利用要领 ;
零设置。除了数据库的毗连 URL 外。你不需要其他设置 ;
可扩展性,这个类库支持漫衍式操纵,可以将您的数据举办多拷贝存储和负 载均衡 ;
100% 地透明地支持 List、Map、Set 等荟萃 ;
自动分页大数据集。分页是 100% 透明地,包括百万笔记录的数据集可以直 接地给表示层,而不消担忧内存和数据库负载的问题 ;
自界说的面向工具的查询语言,用户不需要编写巨大的 SQL 语句 ;
各类数据库间的可移植性。BeanKeeper 屏蔽了种种数据库之间的差别,好比 对 Null 值的处理惩罚,空字符串 (Oracle),查询时巨细写敏感,保存字等差别。 这就意味着你可以变动底层的数据库 ;
对事务的支持,可以或许实现事务的提交和回滚。
下载 BeanKeeper
BeanKeeper 的安装进程很简朴。首先,会见 BeanKeeper 站点下载 Jar 包 。今朝最新的宣布版本是 2.6.0。本文中所有示例也是基于此版本。
BeanKeeper 是基于 LGPL 协议的,你可以在你的贸易软件中贸易软件通过类 库引用 (link) 方法利用它而不需要开源贸易软件的代码。可是假如修改它的代 码可能衍生,则所有修改的代码,涉及修改部门的特别代码和衍生的代码都必需 回收 LGPL 协议。
图 1. BeanKeeper 今朝版本
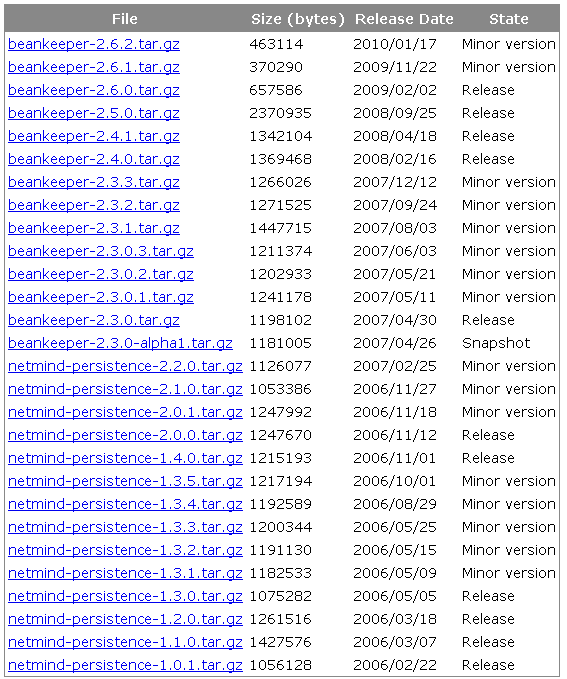
#p#副标题#e#
另外 BeanKeeper 还依赖于下列类库::
commons-lang-2.4.jar
commons-io-1.4.jar
commons-logging.jar
commons-collections-3.2.1.jar
commons-configuration-1.6.jar
log4j-1.2.15.jar
在本例中,我们利用的是 MySQL 数据库来耐久化数据,所以我们还需要下载 MySQL 的 JDBC 驱动:
mysql-connector-java-5.0.8-bin.jar
生存工具
在本章中,我们将演示一个案例先容如何操作 BeanKeeper 将员工 (Employee) 信息耐久化到 MySQL 数据库中。首先从 CSV 文件中一条条读出员 工信息,然后将这些信息生成一个 EmployeeBean 工具,然后将 EmployeeBean 工具耐久化。
首先我们需要界说一个“雷同 JavaBean”类,那么“雷同 JavaBean”是什 么意思呢?真正的 JavaBeans 是一些可视组件,可以在开拓情况中设置它们以 便在 GUI 机关中利用。一些用真正的 JavaBeans 开始的老例在 Java 社区中已 经变得很是普及,尤其是对付数据类。假如一个类遵守下列老例,我就称其为“ 雷同 JavaBean”:
该类是民众的
它界说了一个民众的缺省(无参数)结构函数
它界说了民众的 getX 和 setX 要领用来会见属性(数据)值
既然技能上的界说不成问题,在谈及这些“雷同 JavaBean”类的个中一个时 ,我将跳过所有这些,并只称号它为“bean”类。
如下表所示,我们界说了一个 EmployeeBean 类,类中包括员工 id,姓名, 年数,入职年代信息。
清单 1. EmployeeBean 类
#p#分页标题#e#
package cn.ac.iscas.beankeeper.sample;
import java.util.Date;
public class EmployeeBean {
String id;
String name;
int age;
Date onBoardTime;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getOnBoardTime() {
return onBoardTime;
}
public void setOnBoardTime(Date onBoardTime) {
this.onBoardTime = onBoardTime;
}
}
接下来存储 EmployeeBean 工具到数据库中。首先从 CSV 文件中一条条读出 员工信息,然后将这些信息生成一个 EmployeeBean 工具,最后将 EmployeeBean 工具耐久化到数据库。
清单 2. 生存 EmployeeBean 工具代码
package cn.ac.iscas.beankeeper.sample;
import hu.netmind.persistence.Store;
import java.io.File;
import java.sql.Date;
import java.util.List;
import org.apache.commons.io.FileUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class EmployeeSave {
private static Log log;
/**
* @param args
*/
public static void main(String[] args) {
System.setProperty("log4j.configuration", "file:log4j.xml");
log = LogFactory.getLog(EmployeeBean.class);
try {
String csvFile = args[0];
// open store, uses MySQL driver
Store store = new Store ("org.gjt.mm.mysql.Driver",
"jdbc:mysql://localhost:3306/lhq?user=root&password=sa");
// read csv and generate beans
List historicalData = FileUtils.readLines(new File(csvFile));
// remove first line (header)
historicalData.remove(0);
// store beans to database
for (Object _data : historicalData) {
String[] data = ((String) _data).split (",");
EmployeeBean bean = new EmployeeBean();
bean.setId(data[0]);
bean.setName(data[1]);
bean.setAge(Integer.parseInt(data[2]));
bean.setOnBoardTime(Date.valueOf(data [3]));
// save stock bean to database
store.save(bean);
}
} catch (Exception e) {
log.error(e.getMessage(), e);
system.out.println("Usage: java sample.StockData "
+ "<symbol name> <historical prices file> <query>");
}
}
}
从上面的代码我们可以看出,事实上耐久化一个工具的进程很是简朴,我们 只需要首先实例化一个 Store 工具
Store store = new Store("org.gjt.mm.mysql.Driver",
"jdbc:mysql://localhost:3306/lhq? user=root&password=sa");
然后直接挪用 store 的 save() 要领
store.save(bean);
这样一个 bean 工具就被存储到数据库中了,详细如何实现 ORM 映射对用户 来说是透明的,用户不消体贴工具的哪一个属性对应到了数据库表的哪一列。读 者要是对 BeanKeeper 的靠山实现较量感乐趣,可以查察 MySQL 数据库。
图 2. 数据库中生成的表

#p#分页标题#e#
如图 2 所示,BeanKeeper 在数据中生成了四张表:classes 表, employeebean 表,nodes 表和 tablemap 表。个中,classes 表和 tablemap 表生存了 Java 类到表名的映射信息,
图 3.classes 表

图 4.tablemap 表
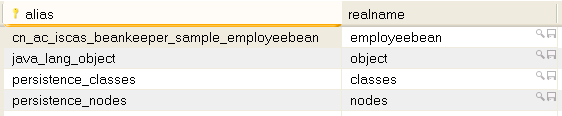
从图 3 和图 4 我们可以看到, cn.ac.iscas.beankeeper.sample.EmployeeData 类的工具被生存到了 employeebean 表中。
打开 employeebean 表 ( 图 5) 我们可以看到,员工工具的各个属性都已经 生存到表中。
图 5.employeebean 表

查询工具
接下来我们先容如何从数据库中查询出工具。譬喻我们要找出所有小于 30 岁的,2005 年之后入职的员工,同时以工号举办排序。
清单 3. 查询示例代码
String query="find EmployeeBean where age<30 and onBoardTime>='2005-01-01' order by id";
Store store = new Store("org.gjt.mm.mysql.Driver",
"jdbc:mysql://localhost:3306/lhq?user=root&password=sa");
List<EmployeeBean> emps = store.find(query);
for(EmployeeBean emp:emps)
System.out.println(emp.getName());
BeanKeeper 查询接口有四个:
find(String statement)
find(String statement, Object[] parameters)
findSingle(String statement)
findSingle(String statement, Object[] parameters)
个中 find 返回的是所有满意条件的工具的荟萃 (List),List 接口的详细 实现类是 LazyList,它具有自动分页的成果,所以纵然返回的功效中包括上百 万笔记录,你也不消担忧内存和数据库负载的问题,他会自动地处理惩罚。除此之外 ,它还提供了 size() 要领,可以返回查询功效的总记录条数。
findSingle 要领返回单个工具,当查询到第一个满意条件的记录后,即遏制 查询,返回功效。
事务节制
事务指的是一系列原子的数据库操纵,在我们的上下文中指的是工具操纵。 这一些操纵要么是所有操纵都乐成完成,事务完成提交;要么是某一操纵失败, 数据回滚到事务开始前的状态。
BeanKeeper 今朝只支持用户打点的事务边界分别,这就意味着你要指定事务 的开始和事务的竣事。纵然你不显示地界说事务,事务其实也是隐含地存在的, 因为你对 store 的每个操纵(好比 save() 和 remove() 要领)城市隐式地创 建一个事务,假如这个操纵的某一环节呈现了错误,这个事务将会回滚。
事务跟踪器(Transaction tracker)认真打点应用中的所有事务。假如你想 跟踪事务的提交和回滚事件,你可以给事务跟踪器添加监听器,这样当提交和回 滚操纵举办时你将可以获得通知。
TransactionListener 接口包罗两个要领:
void transactionCommited(Transaction transaction);
void transactionRolledback(Transaction transaction);
留意:这些要领获得触发这个事件的事务工具时,这些事务已经竣事了,所 以你不能操作它们去执行操纵。同样地,当你从跟踪器中获取到事务工具,并执 行某些数据库相关的操纵时,为制止形成死轮回,此时跟踪器中的事件将不会再 被触发。
清单 4. 添加事务监听器代码
TransactionTracker tt= store.getTransactionTracker();
tt.addListener(new TransactionListener(){
@Override
public void transactionCommited(Transaction transaction) {
System.out.println("Transaction Commited");
}
@Override
public void transactionRolledback(Transaction transaction) {
System.out.println("Transaction Rolledback");
}
});
竣事语
通过上文先容,我们可以看出借助 NetMind BeanKeeper,我们不需要任何配 置,只需利用 BeanKeeper 的三个接口便可实现将工具生存到干系数据库中,相 对付 Hibernate 等框架要简朴得多。同时它也支持巨大的查询和事务成果,可 满意大部门应用场景的需要。
原文地点:http://www.ibm.com/developerworks/cn/java/j-lo- beankeeper/index.html
