全面讲解NLP与知识图谱的对接
NLP是神经语言程序学 (Neuro-Linguistic Programming) 的英文缩写。在香港,也有意译为身心语法程式学的。N (Neuro) 指的是神经系统,包括大脑和思维过程。今天我们就来了解一下NLP与知识图谱的对接的知识,有需要的小伙伴,可以参考一下。本文整理自中国中文信息学会常务理事、白硕博士在杭州金融知识图谱论坛上的演讲。
两个问题
第一个问题是,为什么有人说“中文知识图谱”,难道知识图谱是有国籍的吗?它是有母语的吗?知识是无国界的,这个当然是理论上的说法。具体到一个国度,一个语言文化的大环境,我们就会发现,事实上知识是有母语的。理论依据就是所谓的 语言相对论 。可能大家最近都看了《降临》,《降临》讲的就是语言相对论。一种思维方式、一种文化是被它的语言,它所操的母语所塑造。这是一个很重要的论断,也正因为这个,在英语世界里搞得非常好的一些技术,到汉语的世界来,就有可能水土不服。这给我们提出的任务,就不止是一个移植、汉化的问题。实际上与 NLP 的对接,就是知识处理。与 NLP 对接的这一块,任务比我们想象中重。语言的差距越大,亲疏关系离得越远,这个任务就越重。因为英语和德语之间不会那么费劲,法语跟意大利语之间也没有那么费劲,但是英语跟汉语之间,可能就是要费劲的。这与语言相对论是同样的道理。
第二个问题,知识图谱与 NLP 对接是一个新问题吗?这需要看我们从什么意义上讲。

从学术意义上讲,肯定不是一个新问题,这个问题我们早已有之。在知识图谱不叫知识图谱的年代,实际上自然语言处理的研究者们,就已经在研究如何表示自然语言的语义。自然语言的语义和具体的知识,具体的常识,具体的一些事实陈述之间,到底是什么样的关系,也有不少研究。这里面我们暂且还不说这些具体的研究。知识抽取有很多经典性的工作,比如恐怖活动,恐怖事件这样一个大的范畴,它里面一系列的环节,再比如凶杀案、恐吓信。还有事件范围更大的,比如总统选举,它的选举前期怎么样,中期怎么样,后期怎么样,就不是一个事件而是一个话题了。作为自然语言的语义和作为知识的表示之间,是有着天然的联系的。但是还不完全是一回事。因为语言有语言的单位,它叙述的单位,有它切入的视角。叙述单位和知识要把握的,一个大的场景要把握的单位之间,可能会有一个粒度不一样的衔接。比如我们可能一句一句地说发生了什么事情,什么人死了,在什么地点,那么语义理解也是一句一句把它转义为语义的表示。但是这个语义的表示,还不直接就是知识图谱,还不直接就是那样一个大的场景的描述。所以还要通过不同的蛛丝马迹,通过不同外围的描述,再去激发核心的大的场景,然后再往里面添一些相应的添项。以上是从学术观点看。
从技术观点看,它也是一个不新不旧的问题。不新不旧就是说它与过去是有很多衔接的。但是在新的形势下,对技术也提出了一些新的要求。这些新的要求,也需要我们把它落地。具体到金融领域,我们也会看到确实是有一些新的要求,面对这样一些要求,需要去把它们落地。
从产业来看则是一个新的问题。我们怎样有效地把知识图谱的资源和 NLP 的资源衔接起来。不久前,在一个微信群里面,有一位投资人说他想找这样的资源,找这样的人,找这样的团队合作,把 NLP 直接与量化投资结合,一起合作开发搞成一个系统。在我看来,这不是一个系统,这是好几个系统了。系统之间是有衔接的,你不能说淘金的人,把卖水的生意都一块做了,这是不行的。术业有专攻,有人擅长这个,你就让擅长这个的人去做,有什么需求就给人家提,但你不要把大家都搞成一个系统,那就没法玩了。这个说明了领域的产业分工,NLP 做哪一段,知识图谱做哪一段,知识图谱的应用做哪一段,这分别是几个系统,分别由不同的人来提供。这个事情可能还是没有形成一个稳定的业态导致的。因此需要我们大家一起来探索和努力。
NLP的定义
关于人类行为与沟通程序的一套详细可行的模式。虽然它本身并非一套心理治疗法,NLP的重要法则可以被运用于了解人类经验和行为,和使之有所改变。NLP曾被运用于治疗方面,结果是一套效果强大、快速和含蓄的技巧,能够在人类的行为和能力方面做成广泛和长久的改变。NLP专注于修正和重似脑的设计思想模式,以求更大的灵活和能力。N(Neuro)指神经系统,意译为身心。指我们比较稳定的身心素质,结构及比较逸动的身心状态。L(Linguistic)指语言,指我们沟通中所用的字眼、短句和音调及一切身体动作;还有内心的对话,想象也属语言。P(Programming)指程序。在前面,我们谈到身心与语言。我们就是通过语言来影响自己与他人的身心。同样,他人也通过语言来影响我们。这个影响的过程,NLP称之为程序。写过C++或者类似面向对象编程语言的人,一下子就能看出来了。NLP研究的是就是我们的语言对身心起作用的程序。它的创造人,找到一些卓越的人,研究他们有一些怎样的程序。把它总结起来,然后就可以教给其他人。其他人可要吸收这些程序,那么他也可以获致类似的效果。
模态算子
#p#分页标题#e#
我现在介入一些比较专业的话题,模态算子。这个模态算子是什么东西,大家一看就知道的。因为我们在一些报道中,在一些关于产业、经济发展的这种新闻报道中,以及各种各样的公司公告和业绩公告中,都会看到有这样一些描述。这些描述是一个事实在前面加了一个东西,如果我们不认真对待或者说把它们忽略了,是会有问题的。
这个东西叫模态算子,它有几种表达形式。
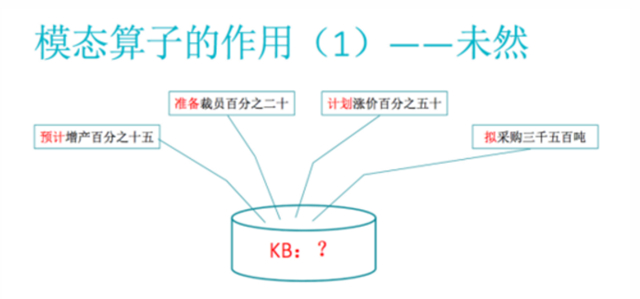
第一种表示 未然 ,就是说还没发生,但是预计或者计划,或者将要发生。我们看这样一些例子,第一个,我们预计增产 15%,第二个是 准备 裁员 20%, 计划 涨价 50%, 拟 采购多少多少吨。如果我们把这些词放过去了,那就可能错把一个未然的东西,当成一个事实来处理。如果放到知识库,那么这个没有发生的事情,跟已经发生的事情搅在一起,你有一些推理能力的话,就会推出很多最后你自己都不相信的结果。所以怎么样去处理未然?这里面我们提出的模态算子一类,在我们中文的这个语言学里面,算是计划类。
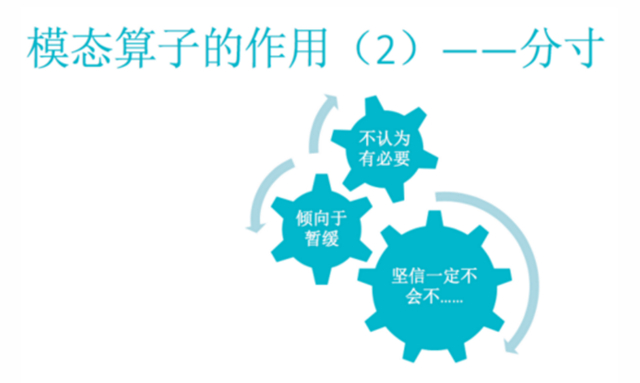
第二类在陈述前面加了主观的折扣或者表示分寸的东西。比如说我不认为有必要怎样,这样一个前缀,或者说倾向于暂缓什么,或者说坚信一定不会怎么样。可能会用一些,就是副词或者说一些表示认知的这样一些词,再进行什么样的组合。这样一种组合,它会把一个裸的陈述加上一些分寸感,一种主观的过滤。这样一些东西,我们也要注意,不能忽略。如果把这些前缀都忽略掉,然后把后面的被前缀约束的东西,当做一种事实陈述,然后再跟事实混在一起,无论是进行推理也好,进行问答也好,都可能会放大一些小概率的事情。
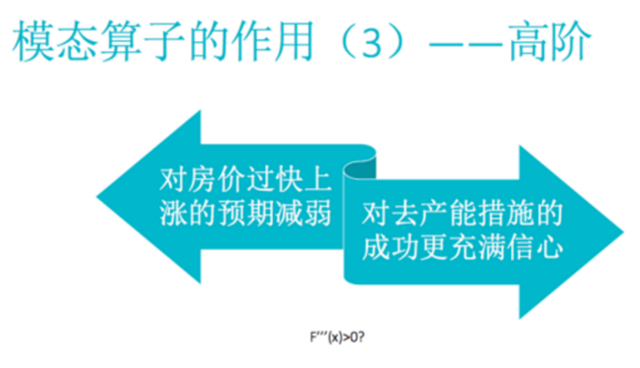
第三类是一些高阶表述。我们在外交场合会见到一些高阶表述的外交辞令。不幸的是,关于财经类的新闻报道中,也看到了这样的表述。比如说对房价过快上涨的预期减弱,这里面对价格做了上涨的修饰,然后又对预期价格上涨这件事做了减弱 。对于这种套了好几层的套路,是一些对高阶导数的定性描述。我们怎样去把它落到所谓的知识库里面,也是一个问题。比如对去产能措施的成功充满信心,还没成功呢只是充满信心,还没有去产能,只是要采取一些措施。
如果我们去采集这样一些数据,采集到的不全是客观事实。因为除了陈述本身之外,还覆盖了一些东西,到底是谁说的,说的是哪个世界的事,是现实世界的事还是我们未来世界的事,说的时候打了多少折扣,从里到外套了多少套路,这些都是我们需要关注的。如果不关注这些点,或者只去采认识的东西,就是采出一些裸事实来。如果不看这些裸事实外面套的外套,可能会有偏颇。
#p#分页标题#e#
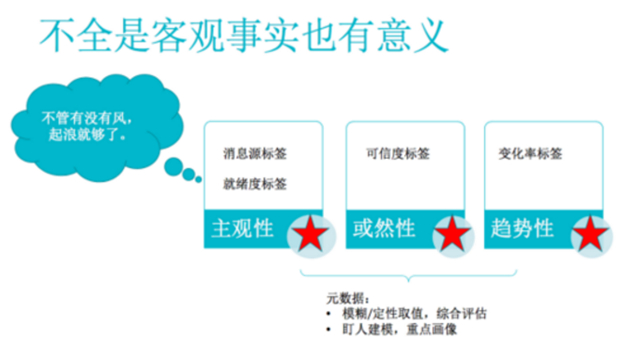
另一方面,这些不全是客观事实的表述,它也有自己的意义。尤其是在金融领域,资本市场是最典型的,不管有没有风,起浪就够了。因为它造成的一些效果,在人的心理有投射,而这些效果会引发后面的一些动荡和行为。不管这个东西是真是假,它引发行为总是真的。如果焦点恰恰在引发行为的这个分析上,那么有这个风,它的作用就会存在,我们就要分析它的作用。那么具体怎么分析呢?我们刚才说的这三类,一类是未然的,那它到底能不能变成已然,这里面是有它的主观性在内的,是谁说的,来源是否可靠。其来源是否可靠,也对它从未然到已然的概率,会产生影响。所以这时候我们需要一些标签把看到的模态算子变成标签,比如说消息源的标签,就绪度的标签。第二类就是打了折扣的这些,我们就要根据这个折扣的分寸感,去给它标注相应的可信度的标签。第三类是定性的导数,我们还要给它标变化率的标签,比如表现率的定性曲直。通过这样一些标签,我们就能够区分带了模态算子帽子的陈述跟裸的事实陈述。这些标签也可以在后期加以利用,我们把它叫做模态元数据。
如何使用模态元数据?
可以想到的三种方法,一种是分库存放,隔绝推理。我推我的,事实跟事实在一起推,不是事实也许可能成为事实的,或者说有一定概率成为事实的或者怎么样的,那些放到另外的地方另外推,这两个互相不相往来。这样分库存放可以减少一定的混乱,但隔绝推理就可能会使我们失去了一些挖到更多知识的机会。
第二种方式就是混合存放,放开推理,这种其实也不好。因为它们长的也不一样,性质也是有所区别的,如果全放在一起,放开推理的话,推出来的东西可能你就无法掌控。
我们推荐的是第三种,就是分库存放。同时对推理有一定的控制,就不让它放开了推。当然说是这么说,具体实施还是要注意到很多事情,我们这里就是从学术角度强调,有这样一类陈述,这类陈述需要大家引起重视。那么一些路径上的考虑先放在这儿,至于说怎么样去实现,我们可以底下再做一些探讨。
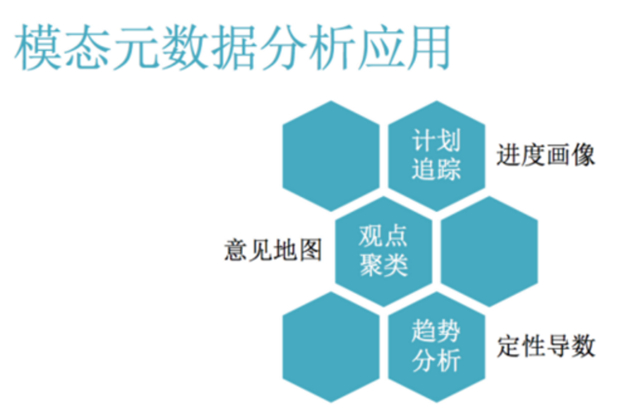
它能怎么用呢?比如说这个公司在不同的时间,会承诺未来做一些事情,它到底做的怎么样呢?这个可以给进度,通过计划最终给进度划线,什么时候哪些东西的未然成为已然了,我们可以看它实现的情况。还有就是观点聚类,那也就是说根据大家对同一件事情打的不同的折扣,我们可以给这样一个人群的观点的分布画像,让他知道谁是站在左边,谁是站在右边,谁是站在中间。我们还可以对趋势进行一些定性导数的分析。
深层语言分析结果的对接
下一个话题,深层语言分析的结果如何与知识图谱进行对接。
深层语言分析,传统来说是把这个语言分成词法、句法、语义三个层面,然后剩下的就是计入应用场景,语义也属于应用场景的一部分。有一条线,线的左边是语言,线的右边是知识,实际上语义已经延伸到知识领域一小块了,但场景基本都属于知识这个领域,而还有一大部分语义,一大半句法,词法的全部都是属于语言这个领域的。从什么地方出发,来达到我们最终的目标,场景,会产生不同的技术路线。
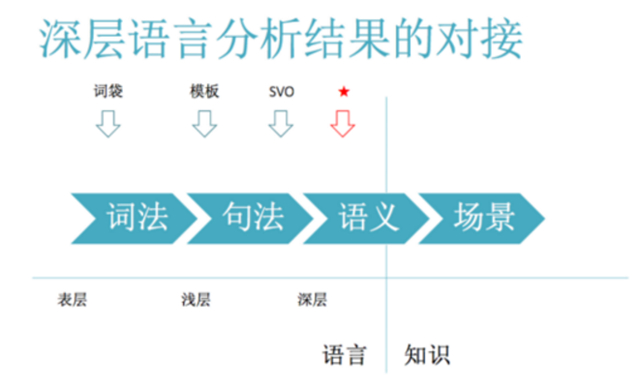
最早是用词袋来激活场景,在知识图谱里面当时叫框架。从这儿就隔得非常远,我们可以利用的信息就非常少。当然这个应用,如果说有一些非常限定领域的应用,出于效率的考虑,我们可以这样用。那么基于模板往前了一步,它利用了一些浅层的句法,但是这个句法不够深。不够深的情况下,它再进一步,就离场景近了一点,但是实际上它还是有一些信息没有捕捉到,或者有一些结构性的关键信息没有捕捉到。因为没有捕捉到,所以这里面还是有一些失误,或者说不够精准的情况。利用句法分析去做,可以用所谓的 SVO, 就是主谓宾语言上的一个简写。去找这种主谓宾的搭配,然后利用主谓宾的组合这种深层的信息,跟相应的一些场景里面的知识图谱也好,什么样的表示也好去对接。SVO 也有它的一个位置,在上图我们画星星的地方。它除了采用深层的句法之外,还采用了一定的语义特征,我们叫次范畴语义特征,这个深层句法加上次范畴语义特征能干的事,又比这个又多一点。现在这种对接的效果,我们看它处的位置跟我们的场景距离就比较短了,它能够利用的一些结构性的信息就更多了。
#p#分页标题#e#
说到这儿,我想说一个产品,小孩拿到了一个新机器人,很高兴跟机器人对话玩。小孩说,你给我讲个故事吧,然后机器人从故事库里面挑一些故事就开始讲了。小孩挺高兴,但是过一会,他表现欲很强,就跟机器人说,那我给你讲个故事吧。机器人不懂,以为是让他讲故事,又开始讲。是“我给你”还是“你给我”这个事情没有搞明白。可以肯定,它是基于模板来做的,可你要考虑一下语序这个事情,至少你这个技能就不会是单打一的出来,一定是成对的或者怎么样出来。正因为它不是成对出来的,所以我们可以很有信心的说,他们是基于模板的技术。基于模板里面就是说,我给你,你给我这个语序的信息,它是没有捕捉到的。
在证券市场里,买卖,在银行里面借贷,包括我们生活当中的娶嫁,都存在一个相对关系,一个讲一个听。你赋予它讲故事的能力,如果说同时能够因为语义上的关联,赋予他一个倾听的能力,不是更好嘛。所以这个是我们从这里面看到的,基于模板的对接。
SVO 的局限
那么 SVO 会出现什么问题呢?它会出现这样的问题:比如说一个公司增长率超过了 15%,然后另一个场景表示,它的增长率是超过了联想(公司)。这都是主谓宾,宾语是放在不同地方的,说明我们知道谁跟谁有关系,但是关系的性质其实是不一样的,而这个是一个细粒度才能区分,只从 SVO 区别不了这件事情。为什么区别不了?因为超过了联想的意思是以联想为对标,在这个增长率上,是超过了联想的那个增长率。
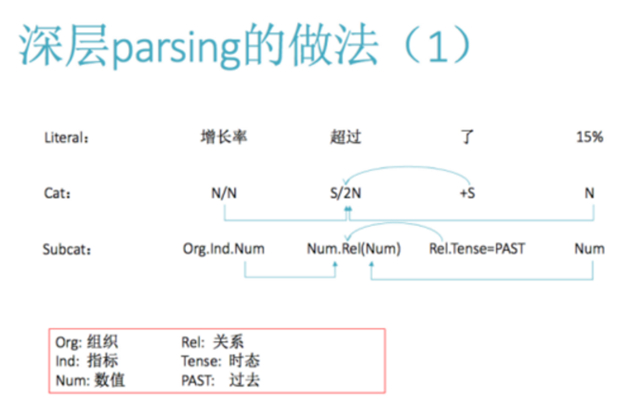
我们的做法就是深层 parsing,这里面我们看底下那行,这一行就是语义次范畴,那个 Cat 还是句法的范畴,这个 Subcat 就是语义次范畴。那么在这里面,我们就看到有一个做法,就是脑补。把联想顺着杆往下滑,从一个组织滑到一个组织的某项指标,然后在某项指标的数值,用这种方法顺着杆滑下来,然后从不可比就变成可比了。其实我们提出语法分析的过程,不仅能分析我们金融领域比较实用的句子,还能分析看起来老大难的句子。
比如说“这个问题老张的处理方法我有意见”,这句就不是常规的用法,而是宾语提前的用法。这种宾语提前的用法,就是说处理的,处理的是问题,办法是处理的办法,意见是对办法的意见。像这样一些名词,按说都是不挖坑的,但是我们这里是要挖坑的,而且要有其他的名词给它填坑,甚至是动词给它填坑,那么这样复杂的过程,我们也可以做,比如说用线图的方式去表达这个分析的结果,或者用平面图的方式去表达这个分析的结果,这都是可以做的。
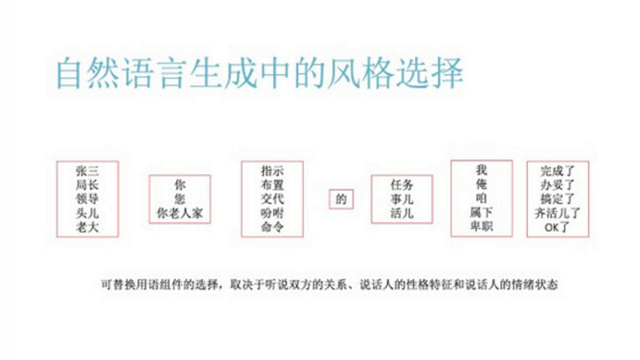
最后我们简单说一下自然语言当中的风格选择问题。大家看这个就知道了,实际上我们很多的地方,每一个零件都是可替换的,而替换的不同选择反映了风格。风格反映了听说对方的关系,反映了说话人的性格特征和情绪状态。
#p#分页标题#e#
知识图谱跟自然语言的对接,知识图谱自身的推理需要有一个共同的中间站,我们比拟的说法,虚拟的说法,它是图谱操作的系统,这可能是需要的。
结束语:文章讲解NLP与知识图谱的对接,就结束了。各位小伙伴应该学的差不多了吧!如果各位小伙伴还想了解更多这方面的知识,可以登录课课家哟!这里面有全面的知识内容和视频教程哦!
