大数据比想象的不靠谱:数据驱动背后的谎言与欺骗的讲解
在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!

每天早晨我都在谎言中开启新的一天。
起床后我走进卫生间,称了一下自己的体重。这个数据会从中国制造的体重秤上同步到我手机中的 App 里面,并且最终进入**的数据库,我的体重数据将永久地存放在云端。
我进行这个称量体重的仪式是因为感觉它能迫使我对于自己的体重保持诚实。它会阻止我找借口欺骗自己,比如说衣服不合身是因为洗的缩水了,而不是因为吃下去太多啤酒与奶酪。这些体重数据是真实无误的,它们不是出自于我的主观判断,因此体重秤是不会说谎的。
当然了,我们都相信体重秤显示的数字从技术层面上来看不应有假,这个数字就是当下我的真实体重,它就如同蛋糕菜谱上的配方表里的数字一样是可靠的。
但是在一次次的称体重中你会发现,那个决定了一个人是标准还是臃肿,是瘦削还是肥胖的体重数字,其实是很容易**纵的。oracle数据库教程
如果我想让自己轻一些,我就会在上称之前出去跑步流一身大汗,排出多余水分。如果我担心自己减的太猛已经超出了健身方案制定的标准,那么我就需要重新回到健康饮食当中,推迟称重的时间,补充食物与充足的水,这样子就可以看到体重数字又有所回升。
当然了,你所使用的这些干预体重的方法只会带来增减 5 磅(约为 4.5 斤)左右的差别,但是对于某些和我一样对于体重无比看重的人来说,这些小小的体重数字波动已经足以让我感觉自己确实有所转变,从这个人
变成了这个人 oracle视频教程
oracle视频教程
你也许觉得这只是个人生活方面的数字欺诈,世界上的其他数据,比如说发表在公开学术期刊上的数据总没那么容易被人为操纵吧。
不过如果你看到了最近刊登在美国权威学术期刊《科学》上面的一项研究,或许就不会这么认为了。该项目的研究人员对于已发表的 100 篇高质量心理学论文中进行的实验进行了复制,看看是不是能够得出相同的数据,而实验结果是仅仅有 36% 的数据可以重现。换句话说,就算是换了另一批小心翼翼且专业的研究人员,也有三分之二的论文结果是不能被重现出来的。
「这个研究项目为我们提供了不少证据,了解到在很多心理学研究论文中发现的结论仍然需要细致的工作去反复检验,看看这些结果到底是不是像我们知道的那样确定。」
在如今的很多研究领域当中,科学家们会一直收集数据,直到数据呈现出一种在统计学上显著的模式,然后他们会使用这些经过严格挑选的数据去发表论文。在学术圈里这种做法被称作是「P 值篡改」(p-hacking),只要掌握一些数据操作的技巧,就可以让数据虚高,得出一个在统计学上显著且有意义的结果。在论文中常用的篡改数据的手法如下:
oracle视频
《纲要》明确,推动大数据发展和应用,在未来5至10年打造精准治理、多方协作的社会治理新模式,建立运行平稳、安全高效的经济运行新机制,构建以人为本、惠及全民的民生服务新体系,开启大众创业、万众创新的创新驱动新格局,培育高端智能、新兴繁荣的产业发展新生态。
《纲要》部署三方面主要任务。一要加快政府数据开放共享,推动资源整合,提升治理能力。大力推动政府部门数据共享,稳步推动公共数据资源开放,统筹规划大数据基础设施建设,支持宏观调控科学化,推动政府治理精准化,推进商事服务便捷化,促进安全保障高效化,加快民生服务普惠化。二要推动产业创新发展,培育新兴业态,助力经济转型。发展大数据在工业、新兴产业、农业农村等行业领域应用,推动大数据发展与科研创新有机结合,推进基础研究和核心技术攻关,形成大数据产品体系,完善大数据产业链。三要强化安全保障,提高管理水平,促进健康发展。健全大数据安全保障体系,强化安全支撑。[8]
#p#分页标题#e#
2015年9月18日贵州省启动我国首个大数据综合试验区的建设工作,力争通过3至5年的努力,将贵州大数据综合试验区建设成为全国数据汇聚应用新高地、综合治理示范区、产业发展聚集区、创业创新首选地、政策创新先行区。
围绕这一目标,贵州省将重点构建“三大体系”,重点打造“七大平台”,实施“十大工程”。
“三大体系”是指构建先行先试的政策法规体系、跨界融合的产业生态体系、防控一体的安全保障体系;“七大平台”则是指打造大数据示范平台、大数据集聚平台、大数据应用平台、大数据交易平台、大数据金融服务平台、大数据交流合作平台和大数据创业创新平台;“十大工程”即实施数据资源汇聚工程、政府数据共享开放工程、综合治理示范提升工程、大数据便民惠民工程、大数据三大业态培育工程、传统产业改造升级工程、信息基础设施提升工程、人才培养引进工程、大数据安全保障工程和大数据区域试点统筹发展工程。
把上述所有加在一起,你就会发现知识产出的过程当中存在着如此明显的问题。
当这些有问题的研究结论进入到 Facebook 驱动的社交媒体世界当中时,即便是一个小小的「P 值篡改」的研究也会迅速传遍世界,而且不会有多少人表示怀疑。当一个普通人在快速浏览新闻的时候不会意识到那些「科学实验得出」、「研究表明」其实就是扯淡,其研究结果根本经不起检验,尤其是当这些说法出现在学术期刊上,就更不会引发怀疑了。
这就是所谓专业的科学研究!如果在学术研究领域当中都存在着数据作假,那么就更别提在数据驱动的商业领域情况会是如何了。
在令人啧啧称奇的《国家的视角》(Seeing Like a State)一书中,展现了各国**与其他大型机构如何试图减少世界当中存在的极端复杂性,将其归为统计数据可以解释的范畴里,并使得其国家或者组织的领导人能够理解到底发生了什么。
作者 James C. Scott 在全书开头使用了一则历史当中真实的故事作为引子。在 18 世纪下半叶,普鲁士的统治者们想要知道在自己森林茂密的国家中到底拥有多少「自然资源」。因此他们就开始着手计算了,他们在自己国家的版图上画出了一个巨大的表格,这样就可以算出来在一个划定的森林范围当中可以产出多少板尺(译者注:硬木板材的计量单位)的木材。至于森林的其他价值,比如说为人类和动物提供庇护,以及自身拥有的生态环境价值都被忽略不计。
真实的世界并不那么守规矩,普鲁士统治者们得到的数据总是不完美。因此他们开始自己创造新的森林,在相同时间种下单一品种的树木,这样在森林当中就不会存在无法货币化的树木了。「事实就是在这种几何图形的森林规划背后有着国家力量的支撑,这种力量将原生的、真实的、包含多个物种且略显混乱的森林变成了新型大一统森林,并且将森林划分成网格状进行统一管理。」Scott 在书中如此写道。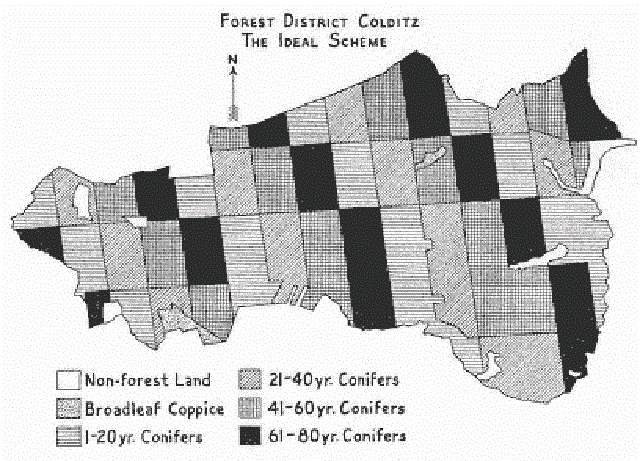
普鲁士的森林全都变成了网格!这些人甚至把树木按照严格的网格形状种成整齐的一排。
德国的林务员们对于如何施肥以及管理树木有着非常科学的认识。普鲁士的植树造林计划确实奏效,至少在接下来的 100 年里没有出现什么问题。在全世界各地有很多人采用了普鲁士这种统一管理森林的方法。
之后森林就开始**的死去。
「在德国的这一植树造林计划中,那些无法形成最终商业价值的树木品种被抛弃,以至于造成了后来树木**死亡的令人痛心的结果,这一局面只有在裸子植物被种下去之后才有可能得到扭转。」Oracle培训
树木生长需要依靠复杂的生态系统作为支撑,而这种系统的形成需要经过数代微生物与物种内部的相互作用培养而成,所有的这一切物种关系都被普鲁士严格的植树计划给破坏殆尽。植物与微生物的营养周期被打断,物种之间微妙的平衡一去不复返,在真实世界里隐藏着的运行规则只有在它消失时才会慢慢显露出来。德国人发明了一个新词汇去描述发生的这一切:Waldsterben,意思为森林的消逝。
有时候当我看看现在的世界,在很多情况下,人们仅凭得到的有限数据就去试图掌控人类与其他生物之间无比复杂的关系。我很想知道是否我们也已经步上了曾经的普鲁士的后尘,等待着下一个 Waldsterben 的时刻。
由广告支撑的互联网生态系统就是一个好例子。这种运作方式非常聪明:通过整个互联网获取人们的数据,然后根据已知的信息向他们展示想要看的广告。不仅如此,由于和传统的广播媒体与印刷媒体相比,人们的网上活动过程是可以跟踪的,因此广告主能够越来越精确地掌握人们想要买些啥。显然,在数据挖掘技术的支持下,在线广告市场份额在不断增长,已经夺取了大部分其他传统媒体所拥有的市场份额。很多新媒体公司不断增长的估值都是建立在数字广告市场将不断增长的预期基础上。
不过如果撕开这一层光鲜亮丽的外皮,就会发现其中显而易见的问题。在那些数字广告与宣传视频庞大流量的背后其实并非是真实的消费者,绝大部分都是软件伪造出来的虚假点击。
「这是一种让虚假流量以假乱真的艺术,它们会通过足够的信息将自己伪造成一个看上去真实的用户。由程序控制的广告计费系统无法分辨点击是来自真实的用户还是机器人,也无法识别出那些拥有新鲜、原创内容的网站与只会复制粘贴别人的文章与图片的假网站。」
当然了,高端的媒体不需要做这种事情。但是便宜且由程序控制的计费广告被虚假流量给蒙蔽了,虚假流量也拉低了整个在线媒体行业的广告价格,这使得那些真心做新闻的网站依靠广告费很难支撑自己的运行。同时,很多网站的用户都非常反感这种商业模式,并且开始安装广告**来对抗在线广告。
广告商与广告技术公司只想要抓取用户的数据去向他们投放精准匹配的广告,他们唯一想做的事情就是让自己投放的广告更加具有针对性。但是从实际出发,这种伴随着广告商不断增长的**而发展出来的广告模式势必会以难以预料的方式去重塑网络媒体的价值观。
我们欺骗自己说数据不过是一个镜头,仅仅反映出我们的生活图景,然而数据实际上已经成为了在线广告商业模式的引擎。广告商获取的用户数据已经改变了在线媒体业的运作方式。单以收集数据这种行为本身来看,它就不是一个中性的举动,它是一种重塑在线媒体的方式。
也就是说我每天上称量体重并不是为了获知自己真实的体重,而是为了改变对于自己胖瘦的认知。这个谎言通常都是奏效的。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!
